本篇文章给大家分享的是有关Python如何爬取历年高考分数线,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
粉丝独白
高考已经结束了,相信绝大部分同学都在放松自己了,毕竟压抑了这么久。现在虽然距离高考放榜还有一段时间,可能有一些同学已经迫不及待地想知道自己考的怎样。因此,现在就来爬取高考网上的近几年高考分数线,看一下近几年分数线的变化趋势,从而心里面有个底,这样才能够更加放松的去嗨皮。
使用的工具库
beautifulsoup
echarts
1.总体思路
在高考网上,可以查看各省的分数线,其中文理科都有2009-2017年的数据,所以可以直接爬取这些数据下来存到MongoDB中,然后再使用echarts进行绘图展示,从而可以更加直观的看到高考分数线的变化趋势。
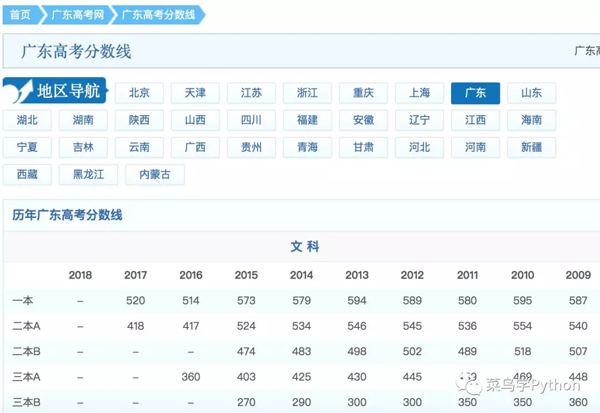
2.爬取数据
(1)获取各省的分数线信息
有两种方法可以达到这个目的
1).通过拼接URL链接切换省份,可以得出链接的变化规律:只要替换省份的拼音上去就可以请求到:
http://www.gaokao.com/guangdong/fsx/
http://www.gaokao.com/shanghai/fsx/
推荐使用pypinyin模块——汉字拼音转换模块/工具。直接使用lazy_pinyin方法就可以得到各省的拼音。由于返回的是列表,所以还需要处理一下才能使用。
>>> from pypinyin import lazy_pinyin >>> lazy_pinyin('北京') ['bei', 'jing']2).通过获取地区导航中的各省链接,直接得到URL:
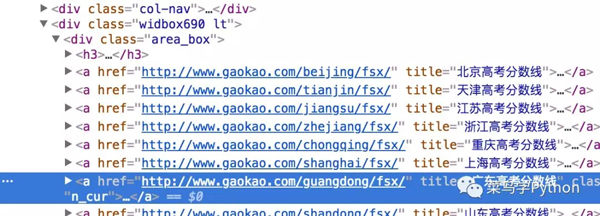
获取各省份的链接:
# 获取省份及链接 pro_link = [] def get_provice(url): web_data = requests.get(url, headers=header) soup = BeautifulSoup(web_data.content, 'lxml') provice_link = soup.select('.area_box > a') for link in provice_link: href = link['href'] provice = link.select('span')[0].text data = { 'href': href, 'provice': provice } provice_href.insert_one(data)#存入数据库 pro_link.append(href)(2)爬取分数线
接下来就可以开始爬取分数线了,通过审查元素(如下图),直接使用beautifulsoup来过滤内容。
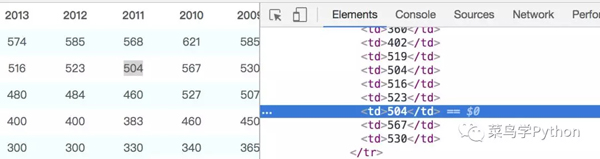
# 获取分数线 def get_score(url): web_data = requests.get(url, headers=header) soup = BeautifulSoup(web_data.content, 'lxml') # 获取省份信息 provice = soup.select('.col-nav span')[0].text[0:-5] # 获取文理科 categories = soup.select('h4.ft14') category_list = [] for item in categories: category_list.append(item.text.strip().replace(' ', ''))#替换空格 # 获取分数 tables = soup.select('h4 ~ table') for index, table in enumerate(tables): tr = table.find_all('tr', attrs={'class': re.compile('^c_\S*')})#使用正则匹配 for j in tr: td = j.select('td') score_list = [] for k in td: # 获取每年的分数 if 'class' not in k.attrs: score = k.text.strip() score_list.append(score) # 获取分数线类别 elif 'class' in k.attrs: score_line = k.text.strip() score_data = { 'provice': provice.strip(),#省份 'category': category_list[index],#文理科分类 'score_line': score_line,#分数线类别 'score_list': score_list#分数列表 } score_detail.insert_one(score_data)#插入数据库3.开始爬取
由于有30多个省份,所以这里使用多线程来爬取,可以提高爬取效率。
if __name__ == '__main__': header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0', 'Connection': 'keep - alive' } url = 'http://www.gaokao.com/guangdong/fsx/' get_provice(url) pool = Pool() pool.map(get_score, [i for i in pro_link])#使用多线程使用多线程爬取的话,不用1分钟就可以爬完所有的数据了。看,多线程可牛逼了,叉会腰先。
4.数据可视化
爬取数据只是***步,接下来就要对数据进行处理展示了。从mongodb 中查找出数据,对数据进行清洗整理,由于我这里的pyecharts有点问题,所以使用echarts进行展示。
1).筛选省份等信息
直接通过mongodb的find函数,限制查找的内容。
import pymongo import charts client = pymongo.MongoClient('localhost', 27017) gaokao = client['gaokao'] score_detail = gaokao['score_detail'] # 筛选分数线、省份、文理科 def get_score(line,pro,cate): score_list=[] for i in score_detail.find({"$and":[{"score_line":line},{"provice":pro},{'category': cate}]}): score_list = i['score_list'] score_list.remove('-')#去掉没有数据的栏目 score_list = list(map(int, score_list)) score_list.reverse() return score_list2).定义相关数据
# 获取文理科分数 line = '一本' pro = '北京' cate_wen = '文科' cate_li = '理科' wen=[] li = [] wen=get_score(line,pro,cate_wen)#文科 li=get_score(line,pro,cate_li)#理科 # 定义年份 year = [2017,2016,2015,2014,2013,2012,2011,2010,2009] year.reverse()
3).折线图展示
series = [ { 'name': '文 科', 'data': wen, 'type': 'line' }, { 'name': '理科', 'data': li, 'type': 'line', 'color':'#ff0066' } ] options = { 'chart' : {'zoomType':'xy'}, 'title' : {'text': '{}省{}分数线'.format(pro,line)}, 'subtitle': {'text': 'Source: gaokao.com'}, 'xAxis' : {'categories': year}, 'yAxis' : {'title': {'text': 'score'}} } charts.plot(series, options=options,show='inline')这样就可以得到下面的历年分数线趋势图了。当然,可以修改get_score的参数就可以的到其他省份的信息了。
5.预测分数线
通过折线图,可以大概的预测2018年北京高考一本的分数线:文科在550-560分之间;理科在530-540分之间。当然,这只是预测的,如果有特殊情况的话,可能波动会比较大。另外,还可以通过拉格朗日插值法求出今年的分数线,这样比较准确,但是由于过程比较麻烦,所以这里只是目测而已。
以上就是Python如何爬取历年高考分数线,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





