这篇文章将为大家详细讲解有关如何用Python编写信息进行收集子域名脚本,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
0×00 前言
任务:
使用脚本借助搜索引擎搜集网站子域名信息。
准备工具:
python安装包、pip、http请求库:requests库、正则库:re库。
子域名是相对于网站的主域名的。比如百度的主域名为:baidu.com,这是一个***域名,而在***域名前由"."隔开加上不同的字符,比如zhidao.baidu.com,那么这就是一个二级域名,同理,继续扩展主域名的主机名,如club.user.baidu.com,这就是一个三级域名,依次类推。
0X00 正文
手动收集子域名是怎样的一种过程?
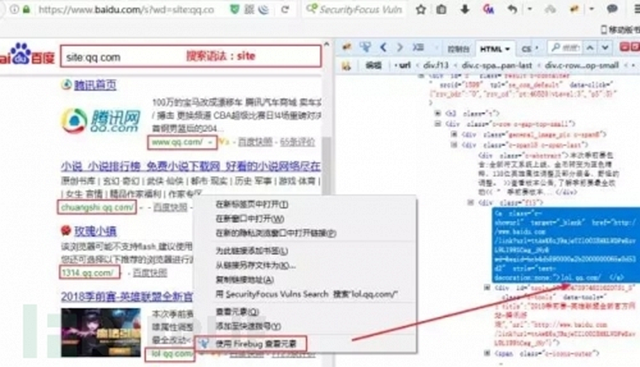
举个例子,比如我们要收集qq.com这个主域名,在百度搜索引擎能够搜索到的所有子域名。
首先,使用搜索域名的语法搜索~
搜索域名语法:site:qq.com
然后,在搜索结果中存在我们要的子域名信息,我们可以右键,查看元素,复制出来。
如何用python替代手工的繁琐操作?
其实就是将手工收集用代码来实现自动化,手工收集的步骤:

收集器制作开始:
1.发起一个搜索的http请求
请求我们使用python的第三方http库,requests
需要额外安装,可以使用pip进行安装pipinstallrequests
requests基本使用-example:
help(requests)查看requests的帮助手册。
dir(requests)查看requests这个对象的所有属性和方法。
requests.get('http://www.baidu.com'
发起一个GET请求。
好了,补充基础知识,我们来发起一个请求,并获得返回包的内容。
#-*-coding:utf-8-*- import requests #导入requests库 url='http://www.baidu.com/s?wd=site:qq.com' #设定url请求 response=requests.get(url).content #get请求,content是获得返回包正文 print response
返回包的内容实在太多,我们需要找到我们想要的子域名,然后复制出来。
从查看元素我们可以发现,子域名被一段代码包裹着,如下:
style="text-decoration:none;">chuangshi.qq.com/ </a>
2.正则表达式——(.*?) 闪亮登场:
正则 规则:style=”text-decoration:none;”>(.*?)/
正则表达式难吗?难。复杂吗?挺复杂的。
然而最简单的正则表达式,我们把想要的数据用(.*?)来表示即可。
re 基本使用-example:
假设我们要从一串字符串'123xxIxx123xxLikexx123xxStudyxx'取出ILike Study,我们可以这么写:
eg='123xxIxx123xxLikexx123xxStudyxx' printre.findall('xx(.*?)xx',eg) #打印结果 ['I','Like','Study']
基于上述例子,依葫芦画瓢也可以获取子域名了。
#-*-coding:utf-8-*- importrequests#导入requests库 importre#导入re库 url='http://www.baidu.com/s?wd=site:qq.com'#设定url请求 response=requests.get(url).content#get请求,content是获得返回包正文 #重点,重点,下面这段代码~ subdomain=re.findall('style="text-decoration:none;">(.*?)/',response) printsubdomain
结果:
['www.qq.com','chuangshi.qq.com','1314.qq.com','lol.qq.com','tgp.qq.com','open.qq.com','https:','ac.qq.com']
3.翻页的处理
上面获得的子域名,仅仅只是返回结果的***页内容,如何获取所有页面的结果?
key=qq.com #为url添加页码: url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=0" url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=10" url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=20" #pn=0为***页,pn=10为第2页,pn=20为第3页…
天啊,100页我要写100个url吗?当然不是,循环语句解决你的困扰。
foriinrange(100):#假设有100页 i=i*10 url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=%s"%i
4.重复项太多?想去重?
基础知识:
python的数据类型:set
set持有一系列的元素,但是set的元素没有重复项,且是无序的。
创建set的方式是调用set()并传入一个list,list的元素将作为set的元素。
sites=list(set(sites))#用set实现去重
正则表达式匹配得到的是一个列表list,我们调用set()方法即可实现去重。
5.完整代码&&总结
下面是百度搜索引擎爬取子域名的完整代码。
#-*-coding:utf-8-*- importrequests importre key="qq.com" sites=[] match='style="text-decoration:none;">(.*?)/' foriinrange(48): i=i*10 url="http://www.baidu.com.cn/s?wd=site:"+key+"&cl=3&pn=%s"%i response=requests.get(url).content subdomains=re.findall(match,response) sites+=list(subdomains) site=list(set(sites))#set()实现去重 printsite print"Thenumberofsitesis%d"%len(site) foriinsite: printi
结果截图:

0X02 总结
其实子域名挖掘就是一个小小的爬虫,只不过我们是用百度的引擎来爬取,不过呢,用bing引擎爬去的数据量会比百度更多,所以建议大家使用bing的引擎,代码的编写方法和百度的大同小异就不放代码了,给个小tip,bing搜索域名用的是domain:qq.com这个的语法哦。
关于如何用Python编写信息进行收集子域名脚本就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





