python中所有的数据都是围绕对象来构建,这些对象可分为两类:可变对象和不可变对象。当变量被赋值,变量中存放的是对象引用(可以理解为C语言中的指针),指向内存中存放该对象的区域。
对于不可变对象而言,对象本身不可以改变(也可以理解为对象的值不可以改变),可以改变的是指向该对象的引用。
对于可变对象而言,对象本身的内容可以改变,指向该对象的引用不变~
不可变对象有:int,string,float,tuple...
不可变对象一旦创建,该对象本身就不能改变。若变量的值需要改变,只能重新创建对象,并改变变量的引用,如下图所示: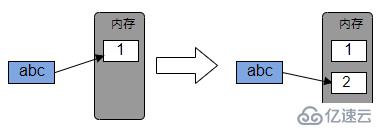
原来的对象不再被引用,会被当做垃圾回收~,可以使用 id() 函数做如下验证:
>>> abc = 1
>>> id(abc)
1456500192
>>> abc=2
>>> id(abc)
1456500224可变对象有:list,dict...
可变对象的内容可以改变,而变量的引用不会发生改变,如下图所示:
可以看到,对于可变对象,变量值的变化不需要重新创建对象,在python中可变对象往往是容器对象(即一个对象包含对其他对象的引用)
>>> abc=['a','b']
>>> id(abc)
2768889238408
>>> abc+=['c']
>>> id(abc)
2768889238408
>>> abc
['a', 'b', 'c']在python中可以通过 is 判断 两个变量是否引用自同一个对象,示例如下:
>>> a = 1
>>> b = 1
>>> a is b
True
>>> c = 2
>>> a is c
False由于python中存在小整数对象池,[-5,257)范围内的整数对象,python解释器不会重复创建~
python中的数字有很多种,包括:整型,长整型,布尔,浮点,复数。数字一经定义,不可更改(不可变对象)
python中的整型用八进制,十进制,十六进制表示:
# 环境为 python3
>>> 1 # 默认为十进制
1
>>> oct(8) # 八进制,"0o" 为前缀,python2.7中的前缀为"0",10表示为'010'
'0o10'
>>> hex(10) # 十六进制,前缀为0X或0x
'0xa' 数据类型转换,可使用 int() 转换为整型:
>>> a = '12'
>>> b = int(a) # 字符串类型转换为整型
>>> b
12
>>> int(1.2) # 浮点数转换为整型,小数部分会被略去
1python2中的整型有长度的限制,32位系统上长度为32位,取值范围为-2**31~2**31-1;64位系统上长度为64位,取值范围为-2**63~2**63-1。
python3中的长整型没有长度限制,可以无限大,但是这受到内存大小的限制(就是不可能无限大)
# 环境为 python2.7
>>> a = 1 # 定义整型
>>> a
1
>>> b = 2L # 定义长整型
>>> b
2L
>>> a = 9999999999999999999999999999999999
>>> a
9999999999999999999999999999999999L通过在数字后面加上 大写L 或者 小写l 表示长整型;在定义整型时,若数据的位数超过了限制范围,则会默认转换为长整型
Tip:在python3中,整型和长整型归为一类:整数类型 int
True 和 False,或者用1和0表示:1 表示True,0表示False~
在条件判断时,若条件语句返回为非零数值、非空字符串、非空list等,均表示为True,否则表示为False。
if []:
print('OK')
else:
print('NO')
结果输出:
NO
while 1: # 等效于while true,无限循环
print('hello world')python中的浮点数也就是小数,可用普通的方式表示,例如:
1.23,3.56 ...也可以使用科学计数法表示:
1.23*10^9就是1.23e9,或者12.3e8 # 小数位数太多时,用科学计数法表示~
0.000012可以写成1.2e-5
整数和浮点数在计算机内部存储的方式是不同的,整数运算是精确的,而浮点数运算则可能会有
四舍五入的误差。
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。虚数部分的字母j大小写都可以~
>> a = 1.3 + 2.5j >> a (1.3+2.5j) >> type(a) <class 'complex'>
数值的运算这里不做介绍
字符串是一个有序的字符集合,且字符串为不可变对象,一经创建,不可更改~
python字符串的创建可以使用单引号,也可以使用双引号
str1 = 'Hello'
str2 = "World"单引号或双引号前面加 r ,可以使字符串中的特殊字符失效,按原样输出:
>>> print('abc\tde')
abc de
>>> print(r'abc\tde')
abc\tde当 r 与 unicode字符串一起使用时,u 需要放在 r 的前面
str1 = ur'abc\tdevar1 = 'Hello'; var2 = 'Kitty'
# 字符串拼接
var1 + var2 # 输出:'HelloKitty'
# 重复输出
var1 * 3 # 输出:'HelloHelloHello'
# 成员运算,判断字符是否存在于指定字符串中
't' in var2 # 输出:True,存在返回True
'a' not in var2 # 输出:True,不存在返回True
# 原始字符串输出,字符串中的转移字符失效,在引号前使用 R 或 r 均可~
print(r'\t\n') # 输出:\t\n
print(R'\t\n') # 输出:\t\npython中的三引号,用于跨行输出,例如要输出如下语句:
line1---
line2---
line3---方式一:
>>> str1 = "line1---\nline2---\nline3---"
>>> str1
'line1---\nline2---\nline3---'
>>> print(str1)
line1---
line2---
line3---方式二(3对单引号还是3对双引号,结果一样)Pycharm环境:
str2 = '''line1---
line2---
line3---'''
print(str2)
输出结果:
line1---
line2---
line3---3对双引号""" """ 或者 3对单引号 ''' ''' 还可以表示多行注释(其中 # 为当行注释):
class Abc():
"""
多行注释
多行注释
多行注释
"""
def __init__(self):
pass
def say_hello(self):
# 单行注释
# 单行注释
return 'hello'----字符串索引
>>> my_str = 'hello'
>>> my_str[4]
'o'
>>> my_str[-3] # 最后第3个字符
'l'----截取字符串
>>> my_str = 'hello'
>>> my_str[1:4] # 截取其中的 第2个到第5个 字符
'ell'
>>> my_str[:4]
'hell' # 截取其中的 第1个到第4个 字符,不包括 my_str[4]
>>> my_str[3:]
'lo' # 截取其中的 第4个到最后1个字符
>>> my_str[:-3]
'he' # 截取第1个到最后第3个字符(不包括最后第3个)
>>> my_str[-3:-1]
'll' # 截取倒数第3个到倒数第1个字符(不包括倒数第一个)
>>> my_str[-3:]
'llo' # 截取倒数第3个到最后一个字符
>>> my_str[::-1]
'olleh' # 生成一个与原字符串顺序相反的字符串----切割、合并字符串
按字符串中的字符,切割字符串
>>> my_str = 'a,b,c,d,e'
>>> my_str.split(',')
['a', 'b', 'c', 'd', 'e'] # 返回列表合并列表或元组中的元素成字符串
>>> ':'.join(['a', 'b', 'c', 'd', 'e']) # 列表
'a:b:c:d:e'
>>> '#'.join(('a', 'b', 'c', 'd', 'e')) 元组
'a#b#c#d#e'----其他操作
>>> my_str = ' abc '
>>> len(my_str) # 获取字符串长度
5
# 移除字符串两边空白
>>> my_str.strip()
'abc'
# 移除字符串左边空白
>>> my_str.lstrip()
'abc '
# 移除字符串右边空白
>>> my_str.rstrip()
' abc'
# 查找字符
>>> my_str.index('b') # 若字符串中没有该字符,会返回报错信息
2
# 查找字符串
S.find(substr, [start, [end]]) # [start, [end]] 指定起始位置和结束位置
>>> my_str.find('bc')
2 # 返回查找到的字符串的第一个字符的索引,若没有找到,返回-1
# 搜索和替换
S.replace(oldstr, newstr, [count]) # count 指定替换次数
>>> my_str.replace('b','B',2)
'aBc aBc abc'
>>> my_str = 'abCD efg'
>>> my_str.lower() # 都转为小写
'abcd efg'
>>> my_str.upper() # 都转为大写
'ABCD EFG'
>>> my_str.swapcase() # 大小写互换
'ABcd EFG'
>>> my_str.capitalize() # 首字母大写
'Abcd efg'使用 str() 将其他类型的数据转换成字符串
>>> str(123456)
'123456'
>>> str(['a','b','c'])
"['a', 'b', 'c']"列表两边使用 [] 包含,[] 中可以存放多种类型的数据,每个数据之间使用逗号(,)分隔。列表数据可变对象~
方式一:my_lst1 = ['a', 1, 2]
方式二:my_lst2 = list('abc')
方式三:my_lst3 = list(['a', 1, 2])创建空列表:
my_lst = []
my_lst = list()# 索引
>>> my_lst = ['a','b','c','d']
>>> my_lst[2]
'c'
# 搜索列表元素
>>> my_lst.index('c')
2 # 返回index,若没有对应元素,返回报错信息
# 列表长度
>>> len(my_lst)
4
# 列表的切片,使用方式与字符串类似,不做意义注释
>>> my_lst = ['a','b','c','d']
>>> my_lst[1:3]
['b', 'c']
>>> my_lst[0:3:2] # 最后一个参数为步长
['a', 'c']
>>> my_lst[::2] # 整个列表从开头到结尾每隔 2 个元素取一个
['a', 'c']
>>> my_lst[:3]
['a', 'b', 'c']
>>> my_lst[2:]
['c', 'd']
>>> my_lst[:-2]
['a', 'b']
>>> my_lst[-3:-1]
['b', 'c']
>>> my_lst[-3:]
['b', 'c', 'd']
>>> my_lst[::-1]
['d', 'c', 'b', 'a']
# 追加元素(append追加)
>>> my_lst = [1,2,3]
>>> my_lst.append(4) # [1, 2, 3, 4]
# 追加元素(extend追加)
>>> my_lst = [1,2,3]
>>> my_lst.extend([4,5]) # [1, 2, 3, 4, 5]
# append与 extend 的区别在于,append 直接追加对象,extend 会迭代对象中的每个元素,然后进行追加
>>> my_lst = [1,2,3]
>>> my_lst.append([4, 5]) # [1, 2, 3, [4, 5]]
>>> my_lst = [1,2,3]
>>> my_lst.extend([4, 5]) # [1, 2, 3, 4, 5]
# 指定索引位置插入元素
>>> my_lst = [1,2,3]
>>> my_lst.insert(-1, 'a') # 最后一个元素前面插入
>>> my_lst
[1, 2, 'a', 3]
>>> my_lst.insert(0, 0) # 第一个元素前面插入
>>> my_lst
[0, 1, 2, 'a', 3]
# 删除元素
>>> a = my_lst.pop() # 不加参数默认删除最后一个元素,并将删除元素返回
>>> my_lst
[0, 1, 2, 'a']
>>> a
3
# pop() 指定参数,通过所应删除
>>> my_lst.pop(1)
1
>>> my_lst
[0, 2, 'a']
# 删除列表中的指定值 li.remove('aa')
>>> my_lst.remove('a') # 若列表中没有该元素,返回报错信息
>>> my_lst
[0, 2]
# 通过 索引和切片 删除元素
>>> my_lst = ['a', 'b', 'c', 'd']
>>> del my_lst[0:2]
>>> my_lst
['c', 'd']
# 清空列表
>>> my_lst.clear()
>>> my_lst
[]
# 列表元素出现的次数
>>> my_lst = ['a', 'b', 'c', 'd', 'a']
>>> my_lst.count('a')
2
>>> my_lst.count('g')
0
# 翻转列表
>>> my_lst = ['a', 'b', 'c', 'd']
>>> my_lst.reverse()
>>> my_lst
['d', 'c', 'b', 'a']----列表中的 in 操作(返回布尔值)
判断元素是否存在于列表中~
>>> my_lst = ['a', 'b', 'c', 'd']
>>> print('a' in my_lst)
True
>>> print('z' in my_lst)
False这里仅介绍 for 循环
my_lst = ['a', 'b', 'c', 'd', 'e']
for i in my_lst:
print(i)
for i in range(len(my_lst)):
print(my_lst[i])以上两种方式的输出结果一致~
可以使用 enumerate 函数连同 index 一起输出,首先了解下 enumerate:
my_lst = ['a', 'b', 'c', 'd', 'e']
for i in enumerate(my_lst):
print(i)
输出:
(0, 'a')
(1, 'b')
(2, 'c')
(3, 'd')
(4, 'e')
# 所以可以这样使用:
my_lst = ['a', 'b', 'c', 'd', 'e']
for index, value in enumerate(my_lst):
print('%s --> %s' % (index, value))
输出:
0 --> a
1 --> b
2 --> c
3 --> d
4 --> eTip:enumerate的第二个参数,可改变起始序号,可以自己尝试~
元组和字符串可通过 list() 转换成列表,这也是初始化列表的方法之一
lst_1 = list((1,2,3)) # [1, 2, 3]
lst_2 = list('abc') # ['a', 'b', 'c']来自字典的转换
>>> my_dict = {'a': 1, 'b': 2, 'c': 3}
>>> list(my_dict) # 将字典中的 keys 转为 list
['a', 'b', 'c']
或者
>>> list(my_dict.keys())
['a', 'b', 'c']
>>> list(my_dict.values()) # 将字典中的 values 转为list
[1, 2, 3]元组与列表类似,使用 () 包含其元素;元组与列表的最大区别在于,元组为不可变对象,一经创建,其内容无法更改。
tup_1 = ('a', 'b', 1, 2)
tup_2 = (1, 2, 3, 4)
tup_3 = 'a', 'b', 'c', 'd'创建空元组
tup_4 = ()创建仅包含一个元素的元组:
>>> tup_4 = (2) # 这样创建 tup_4 会被当做 int 类型,而不是 tuple;
>>> type(tup_4)
<class 'int'>
# 正确创建方式
>>> tup_4 = (2,)
>>> type(tup_4)
<class 'tuple'>元组的索引操作(tup[index]),搜索元素(tup.index()),获取长度(len(tup)),切片(tup[1:3]),元素出现的次数(tup.count())等 这些操作与 list 一致~
因为 tuple 为不可变对象,所以不支持 append,insert,extend,pop,remove,del,clear 等操作
>>> tup_1 = (1,2,3)
>>> tup_1[1] = 4
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignmenttuple 不支持 sort 和 reverse 操作,支持 sorted 操作,返回类型为列表
>>> tup_1 = (2,3,90,6,234,1,53,2)
>>> sorted(tup_1)
[1, 2, 2, 3, 6, 53, 90, 234]tuple同样也支持 in 操作:
>>> my_tup = ('a','b','c','d')
>>> print('a' in my_tup)
True
>>> print('z' in my_tup)
False上述对 list 的循环操作,同样也适用于tuple~
tuple() 可应用于 list,字符串,将其转换成 tuple 类型的数据
tup_1 = tuple("abcdefg") # ('a', 'b', 'c', 'd', 'e', 'f', 'g')
tup_2 = tuple([1,2,3,4,5]) # (1, 2, 3, 4, 5)来自字典的转换,与list类似
list(my_dict.keys()) 或者 list(my_dict) # 将字典中的 keys 转成tuple
list(my_dict.values()) # 将字典中的 values 转成tuple 字典也属于可变对象,使用一对花括号 {} 包含元素,字典中的每个元素为一个 key->value对,key和value之间使用冒号 : 分割,每个元素之间使用逗号隔开~
Tip:dict中的key必须是不可变对象,或者说是可hash类型(例如元组可以作为key),value可以是可变对象,也可以是不可变对象~
d1 = {'a': 1, 'b': 2, 'c': 3}
d2 = dict({'a': 1, 'b': 2, 'c': 3})
d3 = dict(a=1, b=2, c=3) # 这种方式定义字典,key 只能是字符串类型
d4 = dict([('a', 1), ('b', 2), ('c', 3)])
# 初始化字典
d6 = {}.fromkeys(['a', 'b'], None) # {'a': None, 'b': None}
d7 = {}.fromkeys(['a','b'], [1, 2]) # {'a': [1, 2], 'b': [1, 2]}创建空字典:
d1={};
d2=dict(); 字典的循环(d.keys,d.values, for i in d取出的是key)
dict.get(key)
dict.setdefault()
# 获取字典元素
>>> my_dict = {'a': 1, 'b': 2, 'c': 3}
>>> my_dict['b']
2
# 使用 get 方法获取,若没有指定的 key 返回为 None
>>> my_dict.get('b')
2
# 当只有一个参数时,setdefault的作用域get类似,查找指定的key,若没有返回None。当指定的key没有时,不光会返回 None ,还会在字典中添加该 key ,且值为None
>>> my_dict.setdefault('c')
3
>>> my_dict.setdefault('d')
>>> my_dict
{'a': 1, 'b': 2, 'c': 3, 'd': None}
# 添加的 key,也可以指定 value
>>> my_dict.setdefault('e', 5)
5
>>> my_dict
{'a': 1, 'b': 2, 'c': 3, 'd': None, 'e': 5}
# 添加操作
>>> my_dict = {'a': 1, 'b': 2, 'c': 3}
>>> my_dict['d'] = 4
>>> my_dict
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
# 修改操作
>>> my_dict['d'] = 40
>>> my_dict
{'a': 1, 'b': 2, 'c': 3, 'd': 40}
# 删除操作
>>> my_dict.pop('a')
1
>>> my_dict
{'b': 2, 'c': 3, 'd': 40}
# 清空字典
>>> my_dict.clear()
>>> my_dict
{}
# update操作,将 一个字典中(d_1)的元素更新到 另一个字典(d_2)中,若d_1中的key,d_2中也有,则d_1中的key更新d_2中的key,若d_1中的key,d_2中没有,则在d_2中进行添加,示例如下:
>>> d_1 = {'a': 1, 'b': 2, 'c': 3}
>>> d_2 = {'a': 12, 'x': 10, 'y': 20, 'z': 30}
>>> d_1.update(d_2)
>>> d_1
{'a': 12, 'b': 2, 'c': 3, 'x': 10, 'y': 20, 'z': 30}字典的 items() 函数以列表形式 返回可遍历的(键, 值) 元组。
my_dict = {'a': 1, 'b': 2, 'c': 3}
for i in my_dict.items():
print(i)
结果输出:
('a', 1)
('b', 2)
('c', 3)keys(),values()
my_dict = {'a': 1, 'b': 2, 'c': 3}
for i in my_dict.keys(): # keys() 获取字典的所有 key, 并以列表形式返回
print(i)
结果输出:
a
b
c
my_dict = {'a': 1, 'b': 2, 'c': 3}
for i in my_dict.values(): # values() 获取字典的所有 value, 并以列表形式返回
print(i)
结果输出:
1
2
3在python2中,也有items(),keys(),values()函数,返回的是一个字典的拷贝列表(items,keys或values),对应的还有iteritems(),iterkeys(),itervalues(),返回字典所有items(key,value)的一个迭代器,前者会占用额外内存,后者不会
在python3中,废弃了iteritems(),iterkeys(),itervalues()函数,使用items(),keys(),values()替代,其返回结果与python2中的iteritems(),iterkeys(),itervalues()一致
遍历字典也可以不使用上述的函数:
my_dict = {'a': 1, 'b': 2, 'c': 3}
for key in my_dict: # 遍历字典中的所有key
print(my_dict[key])列表转字典
方式一:
>>> ls_key = ['a', 'b', 'c']
>>> ls_value = [1, 2, 3]
>>> dict(zip(ls_key, ls_value))
{'a': 1, 'b': 2, 'c': 3}方式二:
>>> ls_key_value = [['a', 1], ['b', 2], ['c', 3]]
>>> dict(ls_key_value)
{'a': 1, 'b': 2, 'c': 3}字符串转为字典
方式一:
import json
user_str = '{"name" : "Kitty", "gender" : "female", "age": 18}'
# user_str = "{'name' : 'Kitty', 'gender' : 'female', 'age': 18}" # 必须写成上面这种形式(双引号),不能使用单引号,这也是使用 json 方式的缺陷
user_dict = json.loads(user_str) # {"name" : "Kitty", "gender" : "female", "age": 18}方式二:
user_str = '{"name" : "Kitty", "gender" : "female", "age": 18}'
user_dict = eval(user_str) # {'name': 'Kitty', 'gender': 'female', 'age': 18}Tip:使用eval不存在向json这样的问题,但是eval存在安全性问题,所以不建议使用~
方式三:
import ast
user_str = '{"name" : "Kitty", "gender" : "female", "age": 18}'
user_dict = ast.literal_eval(user_str) # {'name': 'Kitty', 'gender': 'female', 'age': 18}Tip:ast.literal_eval 不存在 json 的问题,也没有安全性问题,推荐使用~
集合(set)是一个无序不重复元素的序列。集合中只能存放不可变对象(可hash的)~
使用 {} 或者 set() 创建集合
my_set = {'python', 'ruby', 'java', 'python', 'go'} # 推荐使用
# 或者
my_set = set(['python', 'ruby', 'java', 'python', 'go'])
my_set = set({'python', 'ruby', 'java', 'python', 'go'})
my_set = set(('python', 'ruby', 'java', 'python', 'go'))
# 创建的集合为:{'python', 'java', 'go', 'ruby'}
# 集合中不可存放可变对象
>>> my_set = {[1,2,3], 'abc'}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'Tip:由于集合中的元素不可重复,重复的元素仅保留一个
创建空集合
my_set = set() # 不能使用 {},{} 会创建一个空的字典# 添加元素,add() 操作,若元素已经存在,则不进行任何操作
>>> my_set = {'python', 'ruby', 'java', 'python', 'go'}
>>> my_set.add('c')
>>> my_set
{'go', 'ruby', 'c', 'python', 'java'}
# 更新集合,update操作,已存在的元素,不进行操作,不存在的元素进行添加
>>> my_set = {'python', 'ruby', 'java', 'python', 'go'}
>>> my_set.update({'go','php','c'})
>>> my_set
{'go', 'ruby', 'c', 'python', 'php', 'java'}
# 删除元素
# remove,从集合中移除元素,若不存在,报错~
>>> my_set = {'python', 'ruby', 'java', 'python', 'go'}
>>> my_set.remove('python')
>>> my_set
{'go', 'ruby', 'java'}
>>> my_set.remove('php')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'php'
# discard,从集合中移除元素,元素不存在不会报错
>>> my_set = {'python', 'ruby', 'java', 'python', 'go'}
>>> my_set.discard('ruby')
>>> my_set.discard('php')
>>> my_set
{'go', 'python', 'java'}
# pop,随机从集合中删除一个元素,并返回被删除的元素
>>> my_set = {'python', 'ruby', 'java', 'python', 'go'}
>>> my_set.pop()
'go'
>>> my_set
{'python', 'ruby', 'java'}
# 计算集合中元素个数
>>> len(my_set)
3
# 清空集合
>>> my_set.clear()
>>> my_set
set()
# 判断集合是否包含某个元素,存在返回True,否则返回False~;对应的还有not in
>>> my_set = {'python', 'ruby', 'java', 'python', 'go'}
>>> 'java' in my_set
True
>>> 'erlang' in my_set
False>>> my_set_1 = {'Apple', 'Facebook', 'Amazon'}
>>> my_set_2 = {'Apple', 'Google', 'Alibaba'}----并集 union
>>> my_set_1 | my_set_2
{'Apple', 'Amazon', 'Google', 'Alibaba', 'Facebook'}
# 对应方法
>>> my_set_1.union(my_set_2)
{'Apple', 'Amazon', 'Google', 'Alibaba', 'Facebook'}----交集 intersection
>>> my_set_1 & my_set_2
{'Apple'}
# 对应方法
>>> my_set_1.intersection(my_set_2)
{'Apple'}----差集 difference
>>> my_set_1 - my_set_2
{'Amazon', 'Facebook'}
# 对应方法
>>> my_set_1.difference(my_set_2)
{'Amazon', 'Facebook'}----对称差集 sysmmetric difference
>>> my_set_1 ^ my_set_2
{'Alibaba', 'Amazon', 'Google', 'Facebook'}
# 对应方法
>>> my_set_1.symmetric_difference(my_set_2)
{'Alibaba', 'Amazon', 'Google', 'Facebook'}可使用 set() 将list,tuple,dict,字符串 转换成集合
my_set = set(['python', 'ruby', 'java', 'python', 'go'])
my_set = set(('python', 'ruby', 'java', 'python', 'go'))
my_set = set({'a':1, 'b':2, 'c':3}) # 仅获取 keys,转换后的集合 {'a', 'c', 'b'}
my_set = set('abcdefg') # {'e', 'c', 'f', 'd', 'b', 'a', 'g'}.................^_^
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





