本篇内容主要讲解“分享一次数据库SQL查询的数次轮回”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“分享一次数据库SQL查询的数次轮回”吧!
我们使用数据库,直观感受上是客户端发送一个 SQL,数据库把这个SQL执行一下,查出来数据返回给客户端。但其实SQL在背后被转换,优化,历经许多「磨难」才把结果给取回来。
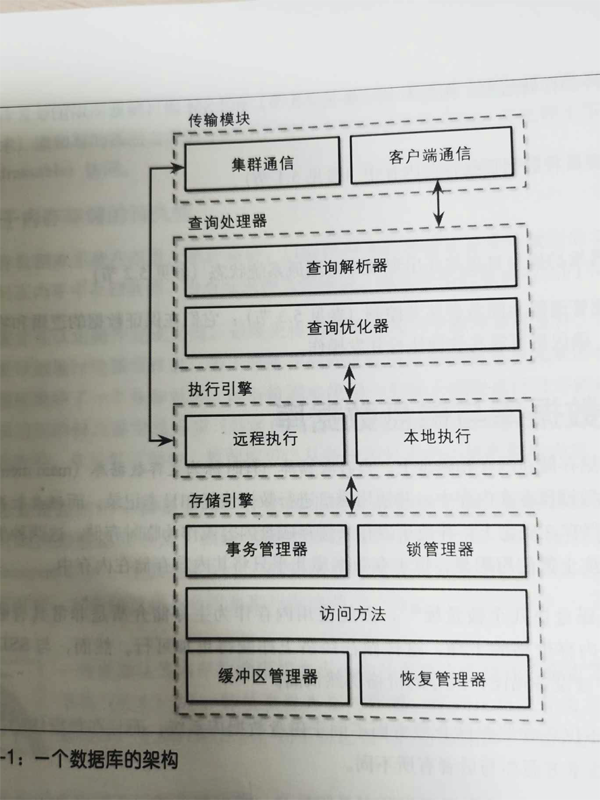
如上图, 我们看到是从查询处理器里经过解析器,优化器,才进入的执行引擎。
今天我们先来看查询管理器,后面再重点来看查询的优化器是怎样精打细算的。
查询管理器
这一部分是数据库功能体现。在这部分里,会将写得不好的查询转换成可以快速执行代码, 然后执行它,并将结果返回给客户端。这个过程会包含多个步骤:
首先解析查询是否是合法的
然后会将查询重写,去除没用的操作符,并做一些预优化
对查询优化以提升性能,将查询转换成执行和数据访问计划
编译查询计划
执行
这部分里,对最后两点我们不会说太多,相对来说他俩没那么关键。
查询解析器
每个SQL语句都会经过分析器去校验语法是否正确。如果你写错了,解析器会拒绝查询。比如你手误,把SELECT 写成了 SLECT,那直接会停止在这儿。
此外,还会检查关键词顺序是否正确。
然后,查询SQL中的表名和列名也会分析,解析器会通过数据库的 metadata 来检查以下内容:
表是否存在
表中对应的查询字段是否存在
对应的操作符是不是能作用在指定的列上(比如不能把一个数字和字符串比大小,也不能给一个integer用substring)
之后会检查查询中对应的表你是否有权限去读或写,毕竟这些访问权限是DBA分配的。
在解析的过程中, 查询SQL 会被转换成数据库的内部表示形式(一般是一棵树)。如果一切 OK,这个转换后的内容会发送给查询「重写器」
查询 Rewriter
在这一步,我们拿到了一个查询的内部表示形式,重写器的目标是要:
对查询做预优化
避免无用的操作
帮助优化器发现最佳方案
重写器会对查询执行一系列已知的规则。如果查询符合某个规则的模式,就会应用这个规则来重写查询。以下是(可选)的规则:
视图合并:如果在查询中使用了视图,那视图将会随着该视图的SQL代码进行转换。
子查询打平:有子查询的查询很难优化,因此重写器将尝试修改查询,甚至删除子查询。
例如
SELECT PERSON.* FROM PERSON WHERE PERSON.person_key IN (SELECT MAILS.person_key FROM MAILS WHERE MAILS.mail LIKE 'christophe%');
就会被这条SQL替换
SELECT PERSON.* FROM PERSON, MAILS WHERE PERSON.person_key = MAILS.person_key and MAILS.mail LIKE 'christophe%';
去除无用的操作符:如果你用了DISTINCT,但你已经有一个UNIQUE约束以保证数据唯一,那DISTINCT关键字就会被删除。
消除多余的连接:如果你有两次相同的连接条件,因为一个连接条件被隐藏在视图中,或者由于传递性而导致无用的连接,则将其删除。
持续的算术评估:如果查询是需要计算的内容,那么在重写过程中将对其进行一次计算。比如,把WHERE AGE> 10 + 2转换为WHERE AGE> 12,然后将TODATE(“ 日期”)转换为datetime格式的日期
(高级)分区修正:如果你使用了分区表,重写器可以找到要使用的分区。
(高级)实例化视图重写:如果已经有了和查询子集匹配的实例化视图,重写器会检查该视图是否是最新视图,并修改查询使用实例化视图而不是原始表。
(高级)自定义规则:如果你创建了重写查询的自定义规则,那重写器会执行这些规则(高级)Olap转换:分析/窗口函数,星型连接,汇总…也都会进行转换(但是具体是由重写器还是优化器完成的取决于数据库,因为这两个过程邻近)。
这个重写后的查询会发送给查询优化器,有趣的来了。
统计
在进入数据库如何优化查询之前,我们需要先谈谈统计信息,因为没有统计信息,数据库就会很傻。如果你不告诉数据库分析自己的数据,它不会这样做,而且会做出错误的假设。
那数据库需要什么信息呢?
我们大概说一下论数据库和操作系统如何存储数据的。他们使用的最小单位称为页或块(默认为4或8 KB)。也就是说,如果你只需要1 KB,也会占一页。如果页面占用8 KB,那就会浪费7 KB。
回到统计来,当你要求数据库获取统计信息时,它会计算这些内容:
一个表中的行或页的数量
一个表里的每一列
单独的数据内容
数据的长度(最小,最大,平均)
数据区间信息(最小、最大、平均)
表的索引信息
这些统计信息会帮助优化器更好的预估查询中磁盘I/O,CPU以及内存的使用。
每一列的统计信息都很重要。比如一个 PERSON 表,需要在 LAST_NAME, FIRST_NAME两列做连接,通过统计,数据库能知道FIRST_NAME这一列共多少个不同的值,LAST_NAME有多少个不同的值。所以数据库会使用LAST_NAME,FIRST_NAME来连接,而不是FIRST_NAME,LAST_NAME,因为LAST_NAME不太可能相同,会少产生数据。大多数情况下,数据库的前两三个字符比较 LAST_NAME就足够了。
当然这些是基本的统计信息,你也可以让数据库计算 histograms 这种更高阶的统计数据。最常使用的值,质量等等,通过这些附加信息,可以帮助数据库找到更高效的查询计划,特别是像等值查询,以及范围查询这种。因为数据库已经知道这种情况下有多少条记录。
这些统计信息记录在数据库的元数据中。因此也是需要花时间不断更新的。这也是为啥在大多数数据库里他都不自动更新。
到此,相信大家对“分享一次数据库SQL查询的数次轮回”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





