这篇文章主要介绍“如何理解java中的管道模式”,在日常操作中,相信很多人在如何理解java中的管道模式问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”如何理解java中的管道模式”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
管道模式,不属于23种设计模式之一(是责任链模式的一种变体),但是在我们实际业务架构中还是有很多场景适用的,主要用于将复杂的进程分解成多个独立的子任务,像流水线一样去执行,了解一下呗
假设我们有这样的一个需求,读取文件内容,并过滤包含 “hello” 的字符串,然后将其反转

Linux 一行搞定
cat hello.txt | grep "hello" | rev
用世界上最好语言 Java 实现也很简单
File file = new File("/Users/starfish/Documents/hello.txt"); String content = FileUtils.readFileToString(file,"UTF-8"); List<String> helloStr = Stream.of(content).filter(s -> s.contains("hello")).collect(Collectors.toList()); System.out.println(new StringBuilder(String.join("",helloStr)).reverse().toString());再假设我们上边的场景是在一个大型系统中,有这样的数据流需要多次进行复杂的逻辑处理,还是简单粗暴的把一系列流程像上边那样放在一个大组件中吗?
这样的设计完全违背了单一职责原则,我们在增改,或者减少一些处理逻辑的时候,就必须对整个组件进行改动。可扩展性和可重用性几乎没有~~
那有没有一种模式可以将整个处理流程进行详细划分,划分出的每个小模块互相独立且各自负责一小段逻辑处理,这些小模块可以按顺序连起来,前一模块的输出作为后一模块的输入,最后一个模块的输出为最终的处理结果呢?
如此一来修改逻辑时只针对某个模块修改,添加或减少处理逻辑也可细化到某个模块颗粒度,并且每个模块可重复利用,可重用性大大增强。
恩,这就是我们要说的管道模式

管道模式(Pipeline Pattern) 是责任链模式(Chain of Responsibility Pattern)的常用变体之一。
顾名思义,管道模式就像一条管道把多个对象连接起来,整体看起来就像若干个阀门嵌套在管道中,而处理逻辑就放在阀门上,需要处理的对象进入管道后,分别经过各个阀门,每个阀门都会对进入的对象进行一些逻辑处理,经过一层层的处理后从管道尾出来,此时的对象就是已完成处理的目标对象。
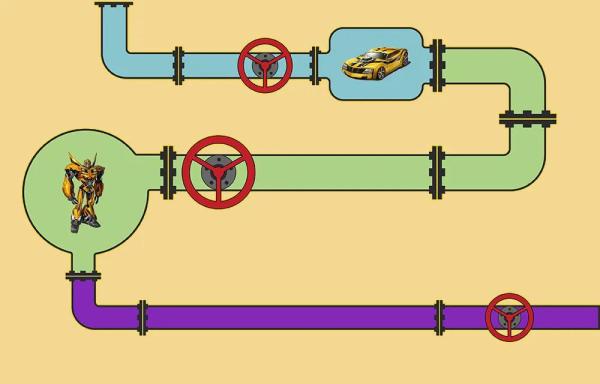
管道模式用于将复杂的进程分解成多个独立的子任务。每个独立的任务都是可复用的,因此这些任务可以被组合成复杂的进程。
PS:纯的责任链模式在链上只会有一个处理器用于处理数据,而管道模式上多个处理器都会处理数据。
管道模式:对于管道模式来说,有 3 个对象:
阀门:处理数据的节点,或者叫过滤器、阶段
管道:组织各个阀门
客户端:构造管道,并调用
程序员还是看代码消化才快些,我们用管道模式实现下文章开头的小需求
1、处理器(管道的各个阶段)
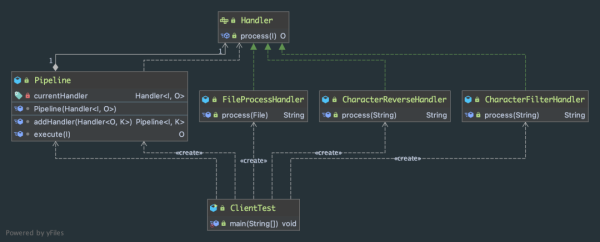
public interface Handler<I,O> { O process(I input); }2、定义具体的处理器(阀门)
public class FileProcessHandler implements Handler<File,String>{ @Override public String process(File file) { System.out.println("===文件处理==="); try{ return FileUtils.readFileToString(file,"UTF-8"); }catch (IOException e){ e.printStackTrace(); } return null; } }public class CharacterFilterHandler implements Handler<String, String> { @Override public String process(String input) { System.out.println("===字符过滤==="); List<String> hello = Stream.of(input).filter(s -> s.contains("hello")).collect(Collectors.toList()); return String.join("",hello); } }public class CharacterReverseHandler implements Handler<String,String>{ @Override public String process(String input) { System.out.println("===反转字符串==="); return new StringBuilder(input).reverse().toString(); } }public class Pipeline<I,O> { private final Handler<I,O> currentHandler; Pipeline(Handler<I, O> currentHandler) { this.currentHandler = currentHandler; } <K> Pipeline<I, K> addHandler(Handler<O, K> newHandler) { return new Pipeline<>(input -> newHandler.process(currentHandler.process(input))); } O execute(I input) { return currentHandler.process(input); } }import lombok.val; public class ClientTest { public static void main(String[] args) { File file = new File("/Users/apple/Documents/hello.txt"); val filters = new Pipeline<>(new FileProcessHandler()) .addHandler(new CharacterFilterHandler()) .addHandler(new CharacterReverseHandler()); System.out.println(filters.execute(file)); } }
产品他么的又来了,这次是删除 hello.txt 中的 world 字符
三下五除二,精通 shell 编程的我搞定了
cat hello.txt |grep hello |rev | tr -d 'world'
Java 怎么搞,你应该很清晰了吧
Pipeline 模式的核心思想是将一个任务处理分解为若干个处理阶段(Stage),其中每个处理阶段的输出作为下一个处理阶段的输入,并且各个处理阶段都有相应的工作者线程去执行相应的计算。因此,处理一批任务时,各个任务的各个处理阶段是并行(Parallel)的。通过并行计算,Pipeline 模式使应用程序能够充分利用多核 CPU 资源,提高其计算效率。 ——《Java 多线程编程实战指南》
优点
将复杂的处理流程分解成独立的子任务,解耦上下游处理逻辑,也方便您对每个子任务的测试
被分解的子任务还可以被不同的处理进程复用
在复杂进程中添加、移除和替换子任务非常轻松,对已存在的进程没有任何影响,这就加大了该模式的扩展性和灵活性
对于每个处理单元又可以打补丁,做监听。(这就是切面编程了)
模式需要注意的东西
鸿蒙官方战略合作共建——HarmonyOS技术社区
Pipeline的深度:Pipeline 中 Pipe 的个数被称作 Pipeline 的深度。所以我们在用 Pipeline 的深度与 JVM 宿主机的 CPU 个数间的关系。如果 Pipeline 实例所处的任务多属于 CPU 密集型,那么深度最好不超过 Ncpu。如果 Pipeline 所处理的任务多属于 I/O 密集型,那么 Pipeline 的深度最好不要超过 2*Ncpu。
基于线程池的 Pipe:如果 Pipe 实例使用线程池,由于有多个 Pipe 实例,更容易出现线程死锁的问题,需要仔细考虑。
错误处理:Pipe 实例对其任务进行过程中跑出的异常可能需要相应 Pipe 实例之外进行处理。
此时,处理方法通常有两种:一是各个 Pipe 实例捕获到异常后调用 PipeContext 实例的 handleError 进行错误处理。另一个是创建一个专门负责错我处理的 Pipe 实例,其他 Pipe 实例捕获异常后提交相关数据给该 Pipe 实例处理。
可配置的 Pipeline:Pipeline 模式可以用代码的方式将若干个 Pipe 实例添加,也可以用配置文件的方式实现动态方式添加 Pipe。
如果,你的管道逻辑真的很简单,也直接用 Java8 提供的 Function 就,具体实现如下这样
File file = new File("/Users/apple/Documents/hello.txt"); Function<File,String> readFile = input -> { System.out.println("===文件处理==="); try{ return FileUtils.readFileToString(input,"UTF-8"); }catch (IOException e){ e.printStackTrace(); } return null; }; Function<String, String> filterCharacter = input -> { System.out.println("===字符过滤==="); List<String> hello = Stream.of(input).filter(s -> s.contains("hello")).collect(Collectors.toList()); return String.join("",hello); }; Function<String, String> reverseCharacter = input -> { System.out.println("===反转字符串==="); return new StringBuilder(input).reverse().toString(); }; final Function<File,String> pipe = readFile .andThen(filterCharacter) .andThen(reverseCharacter); System.out.println(pipe.apply(file));但是,并不是一碰到这种类似流式处理的任务就需要用管道,Pipeline 模式中各个处理阶段所用的工作者线程或者线程池,表示各个阶段的输入/输出对象的创建和一定(进出队列)都有其自身的时间和空间开销,所以使用 Pipeline 模式的时候需要考虑它所付出的代价。建议处理规模较大的任务,否则可能得不偿失。
到此,关于“如何理解java中的管道模式”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





