еҰӮдҪ•дҪҝз”Ёpythonе®һзҺ°ж—¶й—ҙеәҸеҲ—йў„жөӢдёӯзҡ„ж•°жҚ®ж»‘зӘ—ж“ҚдҪң
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңеҰӮдҪ•дҪҝз”Ёpythonе®һзҺ°ж—¶й—ҙеәҸеҲ—йў„жөӢдёӯзҡ„ж•°жҚ®ж»‘зӘ—ж“ҚдҪңвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңеҰӮдҪ•дҪҝз”Ёpythonе®һзҺ°ж—¶й—ҙеәҸеҲ—йў„жөӢдёӯзҡ„ж•°жҚ®ж»‘зӘ—ж“ҚдҪңвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
ж’°еҶҷиғҢжҷҜ
йқўеҗ‘ж•°жҚ®еҲҶжһҗзҡ„е°ҸзҷҪпјҢж°ҙе№іжңүйҷҗпјҢй”ҷиҜҜйҡҫе…ҚпјҢж¬ўиҝҺжҢҮжӯЈгҖӮ
д»Җд№ҲжҳҜж•°жҚ®ж»‘зӘ—
иҝӣиЎҢжңәеҷЁеӯҰд№ ж—¶пјҢдёҖиҲ¬йғҪиҰҒж¶үеҸҠеҲ°еҲ’еҲҶи®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶзҡ„жӯҘйӘӨгҖӮзү№еҲ«ең°пјҢеңЁеҒҡж•°жҚ®йў„жөӢж—¶пјҢдёҖиҲ¬жҠҠйў„жөӢзҡ„дҫқжҚ®пјҲд№ҹе°ұжҳҜеҺҶеҸІж•°жҚ®пјүз§°дҪңXпјҢжҠҠйңҖиҰҒйў„жөӢзҡ„ж•°жҚ®з§°дёәyгҖӮеҚійҰ–е…ҲжҠҠеҺҹе§Ӣж•°жҚ®еҲ’еҲҶдёәtrain_X, train_yиҝҷдёӨдёӘи®ӯз»ғж•°жҚ®йӣҶе’Ңtest_X, test_yиҝҷдёӨдёӘжөӢиҜ•ж•°жҚ®йӣҶгҖӮ
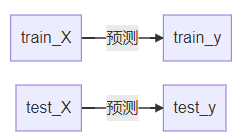
еҜ№дәҺж—¶й—ҙеәҸеҲ—ж•°жҚ®зҡ„йў„жөӢпјҢеҫҖеҫҖжҳҜе»әз«Ӣз”ұеҘҪеҮ дёӘеҺҶеҸІж•°жҚ®йў„жөӢдёӢдёҖж—¶еҲ»зҡ„жңӘжқҘж•°жҚ®пјҢиҝҷж—¶еҖҷдёәдәҶе……еҲҶеҲ©з”Ёе…ЁйғЁж•°жҚ®пјҢеә”иҜҘеҜ№еҺҹе§Ӣж•°жҚ®йӣҶиҝӣиЎҢж»‘зӘ—ж“ҚдҪңпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
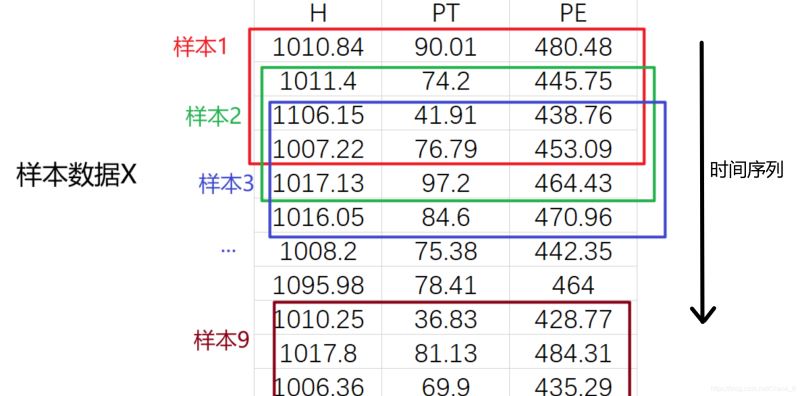
иҝҷйҮҢеұ•зӨәзҡ„жҳҜеӨҡдёӘзү№еҫҒзҡ„ж—¶й—ҙеәҸеҲ—пјҢе…¶дёӯжҜҸдёҖиЎҢж•°жҚ®еқҮеұһдәҺеҗҢдёҖж—¶еҲ»гҖӮеҒҮи®ҫпјҢжҲ‘们иҰҒд»ҘHпјҲ humidityпјүгҖҒPTпјҲpressureпјүгҖҒPEпјҲpowerпјүдёүдёӘзү№еҫҒдёәйў„жөӢдҫқжҚ®пјҢеҸ–еҪ“еүҚе’ҢдёҠдёүдёӘж—¶еҲ»е…ұеӣӣдёӘж—¶еҲ»зҡ„е·ІзҹҘж•°жҚ®еҜ№дёӢдёҖж—¶еҲ»зҡ„PEпјҲеҠҹзҺҮпјүиҝӣиЎҢйў„жөӢпјҢйӮЈд№ҲеҜ№дәҺXж•°жҚ®йӣҶзҡ„ж»‘зӘ—е°ұеә”иҜҘеҰӮдёҠеӣҫжүҖзӨәпјҢиҖҢеҜ№yж•°жҚ®йӣҶзҡ„ж»‘зӘ—еә”иҜҘеҰӮдёӢеӣҫжүҖзӨәгҖӮ
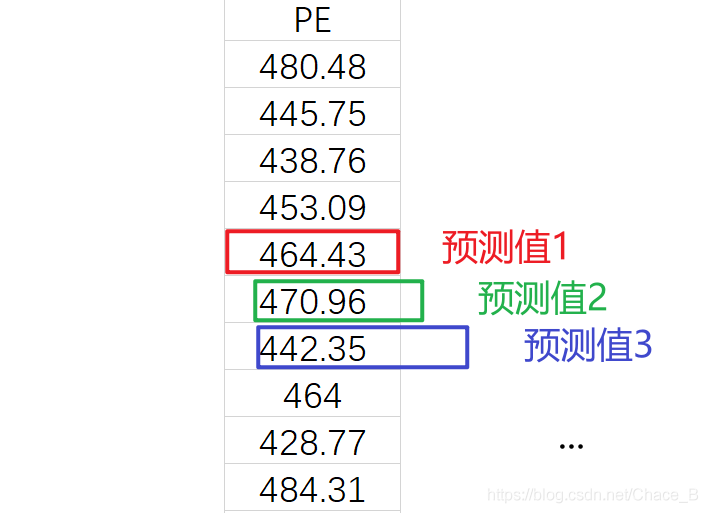
дёӢйқўз»ҷеҮәж»‘зӘ—е®һдҫӢгҖӮ
д»Јз Ғе®һзҺ°
ж»‘зӘ—еҮҪж•°
def sliding_window(DataSet, X_width, y_width, gap = 1, multi_vector = None, X_data = True):
'''
DataSet has to be as a DataFrame
'''
if X_data:
if multi_vector:
a,b = DataSet.shape
else:
a = DataSet.shape[0]
b = 1
c = (a-X_width-y_width-a%gap)/gap
X = np.reshape(DataSet.iloc[0:X_width,:].values,(1,X_width,b))
for i in range(len(DataSet) - X_width - y_width):
i += 1
if i > c:
break
j = i * gap
tmp = DataSet.iloc[j:j + X_width,:].values
tmp = np.reshape(tmp,(1,X_width,b))
X = np.concatenate([X,tmp],0)
return X
else:
if multi_vector:
print('y_data-errorпјҡexpect 1D ,given %dD'%DataSet.shape[1])
return;
else:
a = DataSet.shape[0]
c = (a-X_width-y_width-a%gap)/gap
y = np.reshape(DataSet.iloc[X_width:X_width + y_width,0].values,(1,y_width))
for i in range(len(DataSet) - X_width - y_width):
i += 1
if i > c:
break
j = i * gap + X_width
tmp = DataSet.iloc[j:j + y_width,:].values
tmp = np.reshape(tmp,(1,y_width))
y = np.concatenate([y,tmp])
return yеҚ•зү№еҫҒж—¶й—ҙеәҸеҲ—
еҚ•зү№еҫҒж—¶й—ҙеәҸеҲ—жҳҜжҢҮд»…жңүдёҖдёӘзү№еҫҒзҡ„дёҖз»ҙж—¶й—ҙеәҸеҲ—пјҢеҰӮиӮЎзҘЁж”¶зӣҳд»·гҖҒйЈҺз”өеңәйЈҺйҖҹж•°жҚ®гҖҒж—ҘиҗҘдёҡйўқзӯүгҖӮеҜ№еҚ•зү№еҫҒж—¶й—ҙеәҸеҲ—ж»‘зӘ—ж“ҚдҪңеҰӮдёӢпјҡ
#DataSetи®ӯз»ғж•°жҚ®йӣҶ
#X_widthдҪҝз”Ёзҡ„еҺҶеҸІж•°жҚ®й•ҝеәҰ
#y_widthиҰҒйў„жөӢзҡ„ж•°жҚ®й•ҝеәҰ
#X_dataжҳҜеҗҰжҳҜXж•°жҚ®йӣҶ
train_X = sliding_window(DataSet, X_width, y_width)
train_y = sliding_window(DataSet, X_width, y_width, X_data = None)
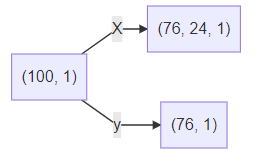
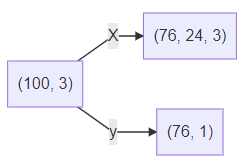
еҒҮи®ҫи®ӯз»ғж•°жҚ®йӣҶжҳҜдёҖдёӘ100*1зҡ„еәҸеҲ—пјҢдҪҝз”Ё24дёӘж•°жҚ®йў„жөӢжңӘжқҘзҡ„1дёӘж•°жҚ®пјҢйӮЈд№Ҳж»‘зӘ—ж“ҚдҪңе°ұе°ҶеҺҹж•°жҚ®еҒҡдәҶиҝҷж ·зҡ„еҸҳжҚўпјҡ
еӨҡзү№еҫҒж—¶й—ҙеәҸеҲ—
еӨҡзү№еҫҒж—¶й—ҙеәҸеҲ—жҢҮж—¶й—ҙеәҸеҲ—зҡ„зү№еҫҒдёҚжӯўдёҖдёӘпјҢеҰӮдёҠж–ҮжүҖдёҫзҡ„HгҖҒPTгҖҒPEдёүзү№еҫҒеәҸеҲ—гҖӮиҝҷз§Қж•°жҚ®дёҖиҲ¬дҪҝз”ЁеңЁеҫ…йў„жөӢзҡ„ж•°жҚ®и·ҹеӨҡдёӘзү№еҫҒзӣёе…іжҖ§иҫғй«ҳзҡ„еңәеҗҲдёӯпјҢеҰӮж°”иұЎж•°жҚ®еөҢе…Ҙзҡ„йЈҺйҖҹйў„жөӢгҖҒиӮЎеёӮж•°жҚ®еөҢе…Ҙзҡ„收зӣҳд»·ж јйў„жөӢзӯүгҖӮиҝӣиЎҢеӨҡзү№еҫҒж—¶й—ҙеәҸеҲ—ж»‘зӘ—ж“ҚдҪңеҰӮдёӢпјҡ
#DataSetи®ӯз»ғж•°жҚ®йӣҶ
#X_widthдҪҝз”Ёзҡ„еҺҶеҸІж•°жҚ®й•ҝеәҰ
#y_widthиҰҒйў„жөӢзҡ„ж•°жҚ®й•ҝеәҰ
#multi_vectorжҳҜеҗҰдёәеӨҡзү№еҫҒ
#X_dataжҳҜеҗҰжҳҜXж•°жҚ®йӣҶ
train_X = sliding_window(DataSet, X_width, y_width, multi_vector = True)
test_y = sliding_window(DataSet, X_width, y_width, multi_vector = True, X_data = None)
еҒҮи®ҫи®ӯз»ғж•°жҚ®йӣҶжҳҜдёҖдёӘ100*3зҡ„еәҸеҲ—пјҢдҪҝз”Ё24дёӘж•°жҚ®йў„жөӢжңӘжқҘзҡ„1дёӘж•°жҚ®пјҢйӮЈд№Ҳж»‘зӘ—ж“ҚдҪңе°ұе°ҶеҺҹж•°жҚ®еҒҡдәҶиҝҷж ·зҡ„еҸҳжҚўпјҡ
жіЁж„ҸдәӢйЎ№
DataSetеҝ…йЎ»жҳҜDataFrameж јејҸгҖӮ
yж•°жҚ®йӣҶеҸӘиғҪжҳҜдёҖз»ҙгҖӮ
д»ҘдёҠжҳҜвҖңеҰӮдҪ•дҪҝз”Ёpythonе®һзҺ°ж—¶й—ҙеәҸеҲ—йў„жөӢдёӯзҡ„ж•°жҚ®ж»‘зӘ—ж“ҚдҪңвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





