这篇文章为大家带来有关java数据结构面试题和答案的详细介绍。大部分面试题都是大家经常见到的,为此分享给大家做个参考。一起跟随小编过来看看吧。
答:
A、HashMap基于Hashing原理,通过put()和get()方法存储与获取对象。
B、我们将值传递给put()方法,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来存储对象。
C、获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。
D、HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存存在链表的下一个节点。
E、HashMap在每个链表节点中存储键值对对象。
散列法(Hashing)是一种将字符组成的字符换转换为固定长度的数值或索引的方法,称为散列法,也叫哈希法。
由于通过更短的哈希值比用原来的值进行数据库搜索更快,这种方法一般用在数据库中建立索引进行搜索,同时还用在各种解密算法中。
答:HashMap及其子类,采用Hash算法来决定集合中元素的存储位置。当系统开始初始化HashMap时,系统会创建一个长度为capacity的Entry数组。
这个数组里可以存储元素的位置被称为bucket(桶)。每个bucket都有指定索引,系统可以根据其索引快速访问该bucket里存储的元素。
HashMap的每个bucket(桶)只存储一个元素Entry,由于Entry对象可以包含一个引用变量,也就是Entry指向另一个Entry依次类推,就形成了一个链。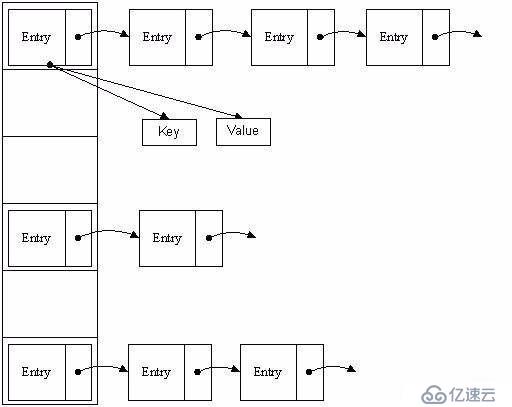
答:当HashMap的每个bucket里面只存储一个Entry,也就是没有通过指针产生Entry链时,此时HashMap具有最好的性能。
当程序取出对应的value时,系统只要先计算出key的hashcode返回值,根据hashode返回值找到该key在table数组中的索引,然后取出索引处的Entry,返回给可以对应的value即可。
public V get(Object key) {
// 如果 key 是 null,调用 getForNullKey 取出对应的 value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 直接取出 table 数组中指定索引处的值,
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next){
Object k;
// 如果该 Entry 的 key 与被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
} 如果HashMap的每个桶里只有一个Entry时,HashMap可以根据索引快速的取出桶里的Entry。
在碰撞问题下,单个桶里存储的不是一个Entry,而是一个Entry链,系统只有按顺序遍历每个Entry,知道找到目标Entry为止。
HashMap在底层将key-value作为一个整体,进行处理。这个整体就是Entry对象。HashMap底层采用一个Entry[]数组来保存所有的key-value。
当需要存储一个Entry对象时,会根据Hash算法来决定其存储位置;
先判断该位置上有没有Entry,没有的话就创建一个Entry对象,再在这个位置上插入;
如果有Entry的话,通过链表的遍历方式去逐个遍历,通过Equals方法将key和已有的key进行比较,看看有没有已经存在的key,有的话用新的value替换之前的value;如果没有则在table[i]插入该Entry,把原来的table[i]位置上的Entry赋值给新的Entry的next。所以新的Entry插入的位置永远是链表的最前面。
当需要取出一个Entry对象时,会根据Hash算法找到其存储位置,直接取出Entry。
答:会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
答:哈希表(HashTable)又叫做散列表,是根据关键码值(即键值对)而直接访问的数据结构。也就是说,它通过把关键码映射到表中一个位置来访问记录,以加快查找速度
答:1、继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
2、线程安全性不同
hashmap:此实现不是同步的。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
3、key和value是否允许null值
Hashtable中,key和value都不允许出现null值。
但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
HashSet实现了Set接口,它不允许集合中有重复的值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。如果我们没有重写这两个方法,将会使用这个方法的默认实现。public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。
答:
答:HashMap中默认的容量是16,负载因子为0.75。由于集合在使用的过程中,不断的存放数据,当存放的数量达到了16*0.75 = 12的时候就需要把当前的16容量进行扩容。扩容涉及到rehash,复制数据等操作,很消耗性能的。
答:ConcurrentHashMap是Java中的一个线程安全且高效的HashMap实现。平时涉及高并发如果要用map结构,那第一时间想到的就是它。
1、ConcurrentHashMap在JDK8里结构: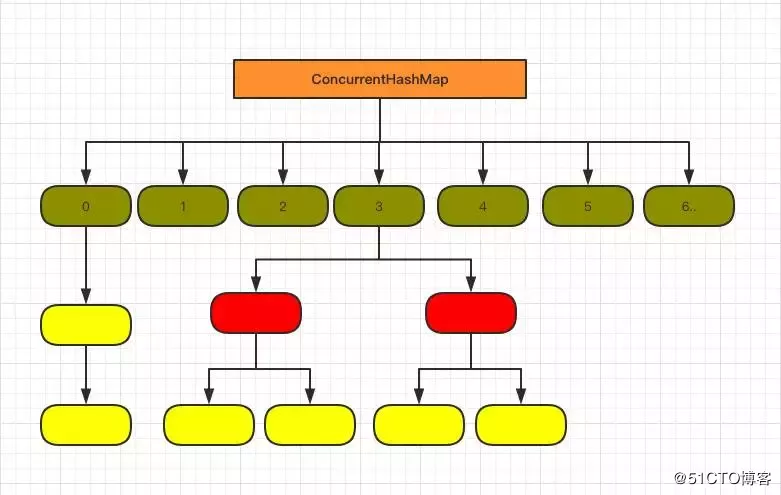
它的优点:结合了HashMap和HashTable。
它的两个静态内部类:HsahEntry和segment
它含有16个segment: ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。
它的get方法:count>0,hash找到HashEntry,hash相等并且key相同,若取value为null,加锁重新获取。
它的remove方法:加锁,每删除一个元素就将那之前的元素克隆一边。因为设置为第一次next之后不能再改变。
它的size()方法:2次不锁住segment方式统计各个segment的大小,若count发生变化,采用加锁方式统计。modCount变量,在put,remove和clean方法里操作元素,modcount加1.
答: 红黑树又称红-黑二叉树,它首先是一颗二叉树,它具体二叉树所有的特性。同时红黑树更是一颗自平衡的排序二叉树。
基本的二叉树都需要满足一个基本性质,树中的任何节点的值大于它的左侧子节点,且小于右侧子节点,这样使得树的检索效率大大提高。
但是二叉树非常容易失衡(一边倒),这样会导致检索效率大大降低。因此出现了一系列的算法,像:AVL、SBT、伸展树、TREAP、红黑树等。
这样二叉树就平衡了,它的左右两个子树的高度差绝对值不超过1,左右都是一颗平衡二叉树。【后续跟进此类型的算法...】
答:TreeMap继承AbstractMap,实现NavigableMap、Cloneable、Serializable三个接口。其中AbstractMap表明TreeMap为一个Map即支持key-value的集合, NavigableMap(更多)则意味着它支持一系列的导航方法,具备针对给定搜索目标返回最接近匹配项的导航方法 。
【1】TreeMap中的元素默认按照keys的自然排序排列。(对Integer来说,其自然排序就是数字的升序;对String来说,其自然排序就是按照字母表排序)
//创建一个空集合,按照自然顺序排列
TreeMap<Integer, String> treeMap = new TreeMap<>();
//创建一个空TreeMap,按照指定的comparator排序
TreeMap<Integer, String> map = new TreeMap<>(Comparator.reverseOrder());
map.put(3, "val");
map.put(2, "val");
map.put(1, "val");
map.put(5, "val");
map.put(4, "val");
System.out.println(map); // {5=val, 4=val, 3=val, 2=val, 1=val}
//map创建一个TreeMap,keys按照自然排序
Map<Integer, String> map = new HashMap<>();
map.put(1, "val");
map.put(1, "val");
map.put(5, "val");
map.put(4, "val");
TreeMap<Integer, String> treeMap = new TreeMap<>(map);以上就是java数据结构面试题和答案的详细内容了,看完之后是否有所收获呢?如果想了解更多相关内容,欢迎关注亿速云行业资讯!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





