目前在系统中涉及到搜索的解决方案都是通过数据库自带特性解决,如通过mysql5.7自带的全文检索功能实现资源的搜索。
这样实现的好处是方便,无需额外开发和维护成本。但是随着业务的发展和数据的增加,性能和可扩展方面很容易出现瓶颈。
结合本次方案库需求的契机,决定引入spring boot + solr 为主要架构基础的前置平台用于应对日渐旺盛的搜索服务需求。
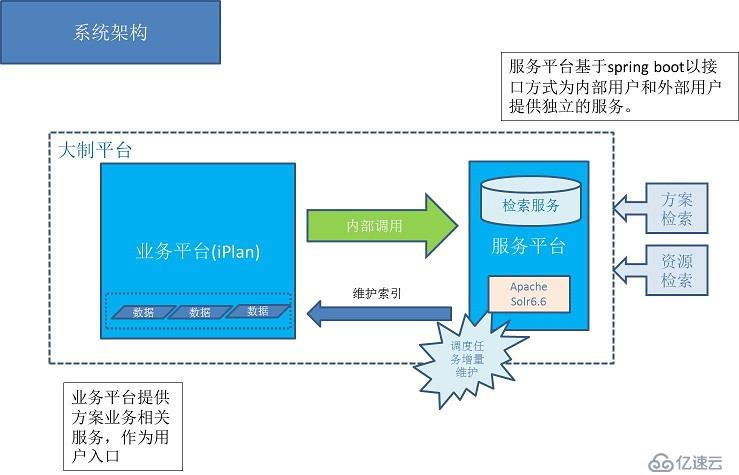
前置平台基于spring boot开发,主要看中spring boot的微服务思想,方便开发和部署。同时可以为以后的微服务架构做技术热身。
通过spring boot搭建的前置平台会处理请求接入,限流,监控,安全等非功能性需求。
搜索端结合了最新的apache solr服务器端(6.6版本),使用自带的smart-cn中文分词组件,提供搜索服务的基础支持。
架构实现部分主要通过具体实践来验证架构的可行性,不涉及具体业务细节和实际数据,
架构实现的操作描述力求做到可复制。
首先确保本机安装了jdk8+,然后就进入eclipse,创建一个maven project。
POM文件包含以下内容:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.BUILD-SNAPSHOT</version>
</parent>
<properties>
<spring.data.solr.version>2.1.1.RELEASE</spring.data.solr.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
<version>${spring.data.solr.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
</dependency>
</dependencies>Maven结构搭好后就是搭建你的项目架构,如图:
Application.java 对应了项目的入口,通过一段很简单的代码就可以启动一个jetty服务了。
package app;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import sample.Example;
@SpringBootApplication
public class Application {
public static void main(String[] args) throws Exception {
SpringApplication.run(Example.class, args);
}
}运行示意图:
首先到官方网站下载最新的安装包,当前版本是6.6,下载zip包就可以了。
解压后的文件夹有以下几个目录是首先需要关注的:
bin: 启动脚本目录,通过这里面的命令来启动关闭服务器
server:solr服务器目录,配置文件和jar包以及索引数据都是在这个目录里面的
contrib:这个里面放的是随版本发布的一些可选包,我们后面用到的中文分词包就在里面
由于我们是验证架构所以所有的配置都是基于单机的。
下一步要做的是创建一个core,在solr-6.6.0\server\solr目录下新建一个文件夹sample_solr,包含如下文件夹
conf 配置文件目录,初始版本从solr-6.6.0\example\example-DIH\solr\db\conf 复制
data 数据文件目录,手工创建
core.properties 手工创建目录,内容如下:
name=sample_solr |
创建完成core后需要修改一下core里面的配置文件,
在solr-6.6.0\server\solr\sample_solr\conf目录下面,有三个文件,按照顺序修改
solrconfig.xml
找到data import的request handler修改为
<requestHandler name="/dataimport" class="solr.DataImportHandler"> <lst name="defaults"> <str name="config">solr-data-config.xml</str> </lst> </requestHandler>
solr-data-config.xml
通过这个文件来配置你的data source和文档字段,下面是我的配置
有几个地方需要注意的,
batchSize
官方文档建议针对mysql数据库使用-1来迫使mysql使用Integer.MIN_VALUE作为fetch size,实际操作中设置成-1时我使用mysql-connector-java-5.1.24(这个驱动如果没有需要自行下载并发到solr-6.6.0\server\lib目录)作为驱动会出现result set close的错误,所以这边设置成10,具体有没有用还待验证
后来在mysql的bug list找到了一个相似的问题,供参考
https://bugs.mysql.com/bug.php?id=83027
entity的PK
在deltaQuery的时候会用到,虽然deltaQuery的语句是通过update_time> xxx来获取增量数据,实际最后查询的时候还是通过pk in (ids) 这样的方式,所以如果需要用到deltaQuery,PK需要设置成数据库表的主键
field的定义
这边可以看到我定义了一个tag字段,可是当你去搜索的时候,结果里面死活只出现id和name。
最后发现文档中的字段都是要通过定义的,只不过solr为自己的sample预留了一些字段定义刚好包含id和name,这也算是个相当坑的地方。
managed-schema
上面说倒field需要通过定义,那么这个文件就是用来定义文档中使用到的字段和字段类型了。Solr正是通过scheme定义来构建索引。
这个scheme文件包含四种元素:
field type
字段的类型如文本,数字浮点等,定义贴切的类型有利于solr更准确的识别字段并输出结果
field
字段,用于组成solr文档的的基本单位。如果从面向对象角度来看,一个文档是一个对象,相应的字段就是这个对象的属性
dynamicField
动态字段,solr除了提供一些默认字段之外还预留了一些通配符字段定义,如下:
<dynamicField name="*_txt" type="text_general" multiValued="true" indexed="true" stored="true"/> |
结合我们上面的tag字段,如果我们觉得每个字段都要定义太麻烦,那么可以在entity里面直接使用dynamic field,
<field column="tag" name="tag_txt" type="string"/> |
重新建立索引后,我们的搜索结果如图:
copyField
从名字就可以看出来这是一个复制字段功能,从定义来看也很明显的发现有source有dest。一个主要的用途就是全文检索,将需要检索的字段都copy到一个字段,之后对这个字段的搜索不就是全文检索了吗?这个和早期数据库里面将几个字段组合起来后来个模糊查询就是全文搜索是一个道理。
这个要注意的是如果source有几个字段,那么目标字段的multiValued需要设置为true
更详细的含义建议参考官方文档,我们主要涉及field type,field和copyField的定义,这里就基于我们的例子来看看。
field type在一般情况下不需要扩展,因为solr已经自带了很多的类型了,这里我们为了支持中文分词,新增一个字段类型如下
<fieldType name="text_smart" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.HMMChineseTokenizerFactory"/> <filter class="solr.CJKWidthFilterFactory"/> <filter class="solr.StopFilterFactory" words="org/apache/lucene/analysis/cn/smart/stopwords.txt"/> <filter class="solr.PorterStemFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.HMMChineseTokenizerFactory"/> <filter class="solr.CJKWidthFilterFactory"/> <filter class="solr.StopFilterFactory" words="org/apache/lucene/analysis/cn/smart/stopwords.txt"/> <filter class="solr.PorterStemFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
可以看出一个field type由两部分构成,index和query。Index负责建立索引的时候对于字段的解析而query负责查询的时候。同时为了中文分词我们需要从solr-6.6.0\contrib\analysis-extras\lucene-libs中拷贝lucene-analyzers-smartcn-6.6.0.jar这个jar包到webapp\WEB-INF\lib
field的配置如下:
1 | <field name="tag" type="text_smart" indexed="true" stored="true"/><field name="text" type="text_smart" multiValued="true" indexed="true" stored="false"/> |
主要是对需要支持中文的字段type配置成我们之前定义的text_smart
copyField
<copyField source="name" dest="text"/><copyField source="tag" dest="text"/> |
通过上面的配置我们一个solr服务器端就可以正常运作了,我们回顾一下我们的过程
最后我们进入命令行,通过solr.cmd start来启动
基于我们前面两个章节的内容,这时候要做的就是在spring boot项目里面提供solr服务器的搜索接口封装以及索引的维护。
首先我们需要创建solr的配置,通过两个文件
1, application.properties
在src/main/resource目录下面新建一个properties文件,内容如下
spring.data.solr.host=http://127.0.0.1:8983/solr/sample_solr |
2, SolrConfig.java
通过注解将properties中定义的属性注入到bean中
package sample;
import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties(prefix = "spring.data.solr")
public class SolrConfig {
private String host;
private String zkHost;
private String defaultCollection;
//getter setter
}接下来就是通过一个controller来通过restful的方式将用户接口和solr script连接起来。
下面是我们的一个查询controller
package sample;
//import section
@RestController
@EnableAutoConfiguration
public class Example {
@Autowired
private SolrClient client;
@RequestMapping("/query/name/{name}")
public String queryByName(@PathVariable String name) throws IOException, SolrServerException {
ModifiableSolrParams params =new ModifiableSolrParams();
params.add("q",name);
params.add("hl","on");
params.add("hl.fl","name,tag");
params.add("ws","json");
params.add("start","0");
params.add("rows","10");
QueryResponse response=null;
try{
response=client.query(params);
SolrDocumentList results = response.getResults();
for (SolrDocument document:results) {
System.out.println( document);
}
}catch(Exception e){
e.getStackTrace();
}
return response.toString();
}
}启动spring boot服务,在浏览器输入我们的查询指令后就可以得到结果了
http://localhost:8080/query/name/测试
通过架构实现部分的验证,基于spring boot + solr的前置服务架构是可行的。但是作为一个前置平台来说,我们还需要关注哪些点呢?
安全性
前置平台很多时候是暴露在通用防火墙之外的,所以危险系数往往也是很高的。我们主要从两个方面来加强防范
限流
通过限流和适当的服务降级,保证服务可用性以及避免可能的流量***。具体实施可以参照线程池的思想,不具体展开。
认证
通过认证体系结合加密算法保证信息传输的保密性和完整性
可靠性
可靠性是指系统的可用程度,涵盖系统持续运行时间,宕机时间,服务回复时间等因素。我们通过预防和监控两个途径来保证。
预防
通过部署集群服务从前置,搜索服务角度去除单点
监控
通过独立的监控系统对前置系统和搜索服务器进行监控,设定合理的阈值和报警点
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





