RиҜӯиЁҖе®һзҺ°еӣәе®ҡеҲҶз»„жұҮжҖ»зҡ„ж–№жі•
з»„еҗҚз§°е’Ңз»„ж•°йҮҸе·ІзҹҘзҡ„еҲҶз»„жұҮжҖ»иў«з§°дёәеӣәе®ҡеҲҶз»„жұҮжҖ»пјҢжӯӨзұ»з®—жі•зҡ„еҲҶз»„дҫқжҚ®жқҘиҮӘдәҺж•°жҚ®йӣҶд№ӢеӨ–пјҢжҜ”еҰӮпјҡжҢүз…§еҸӮж•°еҲ—иЎЁдёӯзҡ„е®ўжҲ·еҗҚеҚ•еҲҶз»„пјҢжҲ–жҢүз…§жқЎд»¶еҲ—иЎЁиҝӣиЎҢеҲҶз»„гҖӮжӯӨзұ»з®—жі•дјҡж¶үеҸҠеҲҶз»„дҫқжҚ®жҳҜеҗҰи¶…еҮәж•°жҚ®йӣҶгҖҒжҳҜеҗҰйңҖиҰҒеӨҡдҪҷзҡ„з»„гҖҒж•°жҚ®жҳҜеҗҰйҮҚеҸ зӯүй—®йўҳпјҢи§ЈеҶіиө·жқҘжңүдёҖе®ҡзҡ„йҡҫеәҰгҖӮжң¬ж–Үе°Ҷд»Ӣз»ҚRиҜӯиЁҖе®һзҺ°еӣәе®ҡеҲҶз»„жұҮжҖ»зҡ„ж–№жі•гҖӮ
дҫӢ1пјҡеҲҶз»„дҫқжҚ®дёҚи¶…еҮәж•°жҚ®йӣҶ
ж•°жҚ®жЎҶsalesжҳҜи®ўеҚ•и®°еҪ•пјҢе…¶дёӯCLIENTеҲ—жҳҜе®ўжҲ·еҗҚпјҢAMOUNTеҲ—жҳҜи®ўеҚ•йҮ‘йўқпјҢиҜ·е°ҶsalesжҢүз…§вҖңжҪңеҠӣе®ўжҲ·еҲ—иЎЁвҖқиҝӣиЎҢеҲҶз»„пјҢ并еҜ№еҗ„з»„зҡ„AMOUNTеҲ—жұҮжҖ»жұӮе’ҢгҖӮжҪңеҠӣе®ўжҲ·еҲ—иЎЁдёә[ARO,BON,CHO]пјҢиҜҘеҲ—иЎЁжҒ°еҘҪжҳҜCLIENTеҲ—зҡ„еӯҗйӣҶгҖӮ
иҜҙжҳҺпјҡsalesзҡ„жқҘжәҗеҸҜд»ҘжҳҜж•°жҚ®еә“д№ҹеҸҜд»ҘжҳҜж–Ү件пјҢжҜ”еҰӮпјҡorders<-read.table("sales.txt",sep="\t", header=TRUE)гҖӮе…¶еүҚеҮ иЎҢж•°жҚ®еҰӮдёӢпјҡ
д»Јз Ғпјҡ
byFac<-factor(sales$CLIENT,levels=c("ARO","BON","CHO"))
result<-aggregate(sales$AMOUNT,list(byFac),sum)
и®Ўз®—з»“жһңпјҡ

д»Јз Ғи§ЈиҜ»пјҡ
1.еҮҪж•°factorз”ҹжҲҗдәҶдёҖдёӘеҲҶз»„дҫқжҚ®пјҲеңЁRдёӯиў«з§°дёәеӣ еӯҗпјүпјҢеҮҪж•°aggregateжҢүз…§еҲҶз»„дҫқжҚ®иҝӣиЎҢеҲҶз»„жұҮжҖ»пјҢж•ҙж®өд»Јз Ғзҡ„з»“жһ„йқһеёёжё…жҷ°гҖӮ
2.йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҲҶз»„дҫқжҚ®дёҚжҳҜеҗ‘йҮҸжҲ–ж•°з»„пјҢеӣ жӯӨдёҚиғҪзӣҙжҺҘеҶҷжҲҗbyFac<- c("ARO","BON","CHO")гҖӮеҲҶз»„дҫқжҚ®д№ҹдёҚиғҪзӣҙжҺҘдҪҝз”ЁпјҢиҝҳйңҖиҰҒиҪ¬еҢ–жҲҗlistзұ»еһӢгҖӮиҝҷдәӣж–№йқўжҳҜеҲқеӯҰиҖ…дёҚжҳ“зҗҶи§Јзҡ„ең°ж–№пјҢе°Өеә”жіЁж„ҸгҖӮ
3.еҰӮжһңд»ҘCLIENTеҲ—дёәеҲҶз»„дҫқжҚ®пјҲеҚійқһеӣәе®ҡеҲҶз»„пјүпјҢеҲҷеҸӘйңҖдёҖеҸҘд»Јз Ғе°ұиғҪе®һзҺ°пјҡ
result<-aggregate(sales$AMOUNT,list(sales$CLIENT),sum)
жҖ»з»“пјҡдҪҝз”ЁaggregateеҸҜд»ҘиҪ»жқҫе®һзҺ°жң¬жЎҲдҫӢгҖӮ
дҫӢ2пјҡеҲҶз»„дҫқжҚ®и¶…еҮәж•°жҚ®йӣҶ
еҲҶз»„дҫқжҚ®д»…йҷҗдәҺеҲ—ж•°жҚ®пјҢиҝҷеұһдәҺзү№ж®Ҡжғ…еҶөпјҢе®һйҷ…дёҠз”ұдәҺеҲҶз»„дҫқжҚ®жқҘиҮӘдәҺж•°жҚ®йӣҶд№ӢеӨ–пјҲжҜ”еҰӮеӨ–йғЁеҸӮж•°пјүпјҢе®ғзҡ„жҲҗе‘ҳеҫҲеҸҜиғҪдёҚеңЁеҲ—ж•°жҚ®дёӯгҖӮжң¬жЎҲдҫӢиҜ•еӣҫи§ЈеҶіиҝҷж ·зҡ„й—®йўҳгҖӮ
еҒҮи®ҫвҖңжҪңеҠӣе®ўжҲ·еҲ—иЎЁвҖқзҡ„еҖјдёә[ARO,BON,CHO,ZTOZ]пјҢиҜ·е°ҶsalesжҢүз…§вҖңжҪңеҠӣе®ўжҲ·еҲ—иЎЁвҖқе°Ҷж•°жҚ®еҲҶдёәеӣӣз»„пјҢ并еҜ№еҗ„з»„зҡ„AMOUNTеҲ—жұҮжҖ»жұӮе’ҢгҖӮжіЁж„ҸпјҢе®ўжҲ·ZTOZдёҚеңЁCLIENTеҲ—дёӯгҖӮ
дёҺдҫӢ1зұ»дјјзҡ„д»Јз Ғпјҡ
byFac<-factor(sales$CLIENT,levels=c("ARO","BON","CHO","ZTOZ"))
result<-aggregate(sales$AMOUNT,list(byFac),sum)
дёҠиҝ°д»Јз Ғзҡ„и®Ўз®—з»“жһңжҳҜпјҡ

еҸҜд»ҘзңӢеҲ°пјҢи®Ўз®—з»“жһңдёӯеҸӘжңүдёүз»„ж•°жҚ®пјҢзјәеӨұдәҶZTOZпјҢиҖҢдёҚжҳҜиҰҒжұӮдёӯзҡ„еӣӣз»„гҖӮжҳҫ然пјҢдёҠиҝ°д»Јз ҒдёҚиғҪе®һзҺ°жң¬жЎҲдҫӢпјҢйңҖиҰҒж”№иҝӣгҖӮ
ж”№иҝӣеҗҺзҡ„д»Јз Ғпјҡ
byFac<-factor(sales$CLIENT,levels=c("ARO","BON","CHO","ZTOZ"))
tapply(sales$AMOUNT, list(byFac),function(x) sum(x))
и®Ўз®—з»“жһңпјҡ

д»Јз Ғи§ЈиҜ»пјҡ
1.ж”№иҝӣеҗҺзҡ„д»Јз Ғжӣҙз¬ҰеҗҲдёҡеҠЎйҖ»иҫ‘пјҢеӣӣдёӘеҲҶз»„йғҪиғҪе‘ҲзҺ°еңЁз»“жһңдёӯгҖӮ
2.д»Јз ҒдёӯдҪҝз”ЁдәҶtapplyиҝӣиЎҢеҲҶз»„жұҮжҖ»пјҢиҝҷдёӘеҮҪж•°зҡ„йҖҡз”ЁжҖ§жҜ”aggregateеҘҪпјҢдҪҶtapplyзҡ„еҗҚеӯ—дёҚеҰӮaggregateзӣҙи§ӮпјҢеҲқеӯҰиҖ…еӨ§еӨҡжҗһдёҚжё…жҘҡгҖӮ
3.ZTOZзҡ„жұҮжҖ»еҖјжҳҜNAпјҢиҝҷиҜҙжҳҺZTOZдёҚеңЁCLIENTеҲ—дёӯгҖӮеҰӮжһңZTOZзҡ„жұҮжҖ»еҖјдёә0пјҢеҲҷиҜҙжҳҺZTOZеңЁCLIENTеҲ—дёӯпјҢдҪҶи®ўеҚ•йҮ‘йўқдёә0гҖӮ
4.жң¬жЎҲдҫӢдёӯпјҢеҲҶз»„жұҮжҖ»зҡ„з»“жһңеҸӘжңүеӣӣз»„пјҢеӨҡдҪҷзҡ„е®ўжҲ·дёҚеә”иҜҘеҮәзҺ°пјҢиҝҷдәӣе®ўжҲ·еҸҜд»Ҙз§°дёәвҖңеӨҡдҪҷз»„вҖқгҖӮи®Ўз®—еӨҡдҪҷз»„зҡ„жұҮжҖ»еҖјдёҚиғҪеңЁеҪ“еүҚз®—жі•дёҠз®ҖеҚ•ж”№йҖ пјҢйңҖиҰҒдҪҝз”Ёж–°зҡ„еҮҪж•°пјҡ
filtered<-sales[!is.element(sales$CLIENT,byFac),]
redundant<-sum(filtered$AMOUNT)
иҝҷж®өд»Јз Ғ并дёҚеӨҚжқӮпјҢдҪҶе®һзҺ°жҖқи·Ҝе’Ңд№ӢеүҚзҡ„д»Јз ҒжҳҺжҳҫдёҚеҗҢгҖӮ
жҖ»з»“пјҡдҪҝз”ЁtapplyеҸҜд»ҘиҪ»жқҫе®һзҺ°жң¬жЎҲдҫӢгҖӮ
дҫӢ3пјҡеҲҶз»„жқЎд»¶дёҚйҮҚеҸ
д»ҘжқЎд»¶дҪңдёәеҲҶз»„дҫқжҚ®пјҢиҝҷд№ҹжҳҜеӣәе®ҡеҲҶз»„зҡ„дёҖз§ҚпјҢжҜ”еҰӮпјҡе°Ҷи®ўеҚ•йҮ‘йўқжҢүз…§1000гҖҒ2000гҖҒ4000еҲ’еҲҶдёәеӣӣдёӘеҢәй—ҙпјҢжҜҸдёӘеҢәй—ҙдёҖз»„и®ўеҚ•пјҢз»ҹи®Ўеҗ„з»„и®ўеҚ•зҡ„йҮ‘йўқгҖӮ
д»Јз Ғ
byFac<-cut(sales$AMOUNT,breaks=c(0,1000,2000,4000,Inf))
result<-tapply(sales$AMOUNT, list(byFac),function(x) sum(x))
и®Ўз®—з»“жһңпјҡ

д»Јз Ғи§ЈиҜ»пјҡеҮҪж•°cutе°Ҷж•°жҚ®жЎҶеҲ’еҲҶдёәеӣӣдёӘеҢәй—ҙпјҢеҮҪж•°tapplyе°Ҷж•°жҚ®жЎҶжҢүз…§еҢәй—ҙеҲҶз»„пјҢ并жұҮжҖ»еҮәеҗ„з»„з»“жһңгҖӮ
жҖ»з»“пјҡcutе’Ңtapplyй…ҚеҗҲеҸҜд»ҘиҪ»жқҫе®һзҺ°жңҖз®ҖеҚ•зҡ„жқЎд»¶еҲҶз»„гҖӮ
дҫӢ4пјҡеҲҶз»„жқЎд»¶жңүйҮҚеҸ пјҢйҮҚеӨҚи®Ўз®—з»“жһң
еңЁжңҖз®ҖеҚ•зҡ„жқЎд»¶еҲҶз»„дёӯпјҢжқЎд»¶жІЎжңүеҸ‘з”ҹйҮҚеҸ пјҢдҪҶе®һйҷ…дёҠеҸ‘з”ҹйҮҚеҸ зҡ„жғ…еҶөеҫҲеёёи§ҒпјҢжҜ”еҰӮе°Ҷи®ўеҚ•йҮ‘йўқжҢүз…§еҰӮдёӢ规еҲҷеҲҶз»„пјҡ
1000иҮі4000пјҡ常规订еҚ•r14
2000д»ҘдёӢпјҡйқһйҮҚзӮ№и®ўеҚ•r2
3000д»ҘдёҠпјҡйҮҚзӮ№и®ўеҚ•r3
иҝҷйҮҢзҡ„常规订еҚ•е°ұдјҡе’ҢеҸҰеӨ–дёӨз»„еҸ‘з”ҹйҮҚеҸ гҖӮеҸ‘з”ҹйҮҚеҸ ж—¶е°ұжңүжҳҜеҗҰиҰҒжҠҠйҮҚеҸ зҡ„ж•°жҚ®йҮҚеӨҚи®Ўз®—зҡ„й—®йўҳпјҢжң¬жЎҲдҫӢе…Ҳи§ЈеҶійҮҚеӨҚи®Ўз®—зҡ„жғ…еҶөгҖӮ
д»Јз Ғпјҡ
r14<-subset(sales,AMOUNT>=1000 & AMOUNT<=4000 )
r2<-subset(sales,AMOUNT<2000)
r3<-subset(sales,AMOUNT>3000 )
grouped<-list(r14=r14,r2=r2,r3=r3)
result<-lapply(grouped,FUN=function(x) sum(x$AMOUNT))
и®Ўз®—з»“жһңпјҡ

иҜҙжҳҺпјҡr2е’Ңr3еҢ…еҗ«дәҶr14зҡ„йғЁеҲҶж•°жҚ®гҖӮ
д»Јз Ғи§ЈиҜ»пјҡ
1.дёҠиҝ°д»Јз ҒеҸҜд»Ҙи§ЈеҶіжң¬жЎҲдҫӢпјҢдҪҶе·Із»Ҹжҳҫеҫ—еҫҲйә»зғҰдәҶпјҢеҰӮжһңжқЎд»¶жӣҙеӨҡжӣҙеӨҚжқӮпјҢдёҠйқўзҡ„д»Јз Ғе°Ҷдјҡжӣҙй•ҝгҖӮ
2.иҝҷйҮҢз”ЁеҲ°дәҶдёҖдёӘж–°зҡ„еҮҪж•°lapplyгҖӮиҝ„д»ҠдёәжӯўпјҢдёәдәҶе®һзҺ°еӣәе®ҡеҲҶз»„пјҢжҲ‘们已з»ҸдҪҝз”ЁдәҶеҫҲеӨҡеҮҪж•°пјҢеҢ…жӢ¬пјҡfactorгҖҒaggregateгҖҒlistгҖҒtapplyгҖҒcutгҖҒsubsetгҖҒlapplyзӯүзӯүгҖӮиҖҢдё”еҗҢдёәжқЎд»¶еҲҶз»„пјҢд»…д»…еӣ дёәжқЎд»¶жҳҜеҗҰйҮҚеҸ пјҢжҲ‘们е°ұйңҖиҰҒз”ЁдёҚеҗҢзҡ„еҮҪж•°е’ҢдёҚеҗҢзҡ„жҖқи·ҜеҺ»е®һзҺ°пјҢжҺҢжҸЎиҝҷдәӣз”Ёжі•иҝҳжҳҜзӣёеҪ“еӣ°йҡҫзҡ„гҖӮ
3.дёҠиҝ°д»Јз Ғзҡ„и®Ўз®—з»“жһңжҳҜlistпјҢеүҚйқўеҮ дёӘжЎҲдҫӢжңүзҡ„жҳҜdata.frameпјҢжңүзҡ„еҲҷжҳҜarrayпјҢиҝҷдәӣдёҚдёҖиҮҙзҡ„ең°ж–№еңЁе®һйҷ…дҪҝз”Ёдёӯд№ҹдјҡйҖ жҲҗйә»зғҰгҖӮ
жҖ»з»“пјҡеҸҜд»Ҙе®һзҺ°жң¬жЎҲдҫӢпјҢдҪҶд»Јз ҒиҫғеӨҚжқӮпјҢйңҖиҰҒжҺҢжҸЎеҫҲеӨҡеҮҪж•°гҖӮ
дҫӢ5пјҡеҲҶз»„жқЎд»¶жңүйҮҚеҸ пјҢз»“жһңдёҚйҮҚеӨҚ
д№ӢеүҚзҡ„жЎҲдҫӢи§ЈеҶідәҶж•°жҚ®йҮҚеӨҚж—¶зҡ„й—®йўҳпјҢдҪҶжңүж—¶жҲ‘们йңҖиҰҒдёҚйҮҚеӨҚзҡ„и®Ўз®—з»“жһңпјҢеҚіпјҡеүҚйқўеҲҶз»„дёӯеҮәзҺ°иҝҮзҡ„ж•°жҚ®дёҚиғҪеҮәзҺ°еңЁеҗҺйқўпјҢй’ҲеҜ№жң¬жЎҲдҫӢпјҢе…·дҪ“зҡ„з®—жі•е°ұжҳҜпјҡr2дёҚеә”иҜҘеҢ…еҗ«r14дёӯзҡ„ж•°жҚ®пјҢr3дёҚеә”еҪ“еҢ…еҗ«r2е’Ңr14дёӯзҡ„ж•°жҚ®гҖӮ
д»Јз Ғпјҡ
r14<-subset(sales,AMOUNT>=1000 & AMOUNT<=4000 )
r2<-subset(sales,AMOUNT<2000 & !(AMOUNT>=1000 & AMOUNT<=4000))
r3<-subset(sales,AMOUNT>3000 & !((AMOUNT>=1000 & AMOUNT<=4000)) & !(AMOUNT<2000))
grouped<-list(r14=r14,r2=r2,r3=r3)
result<-lapply(grouped,FUN=function(x) sum(x$AMOUNT))
и®Ўз®—з»“жһң

жіЁж„ҸпјҡдёҚйҮҚеӨҚи®Ўз®—ж•°жҚ®ж—¶пјҢr2е’Ңr3зҡ„еҖјжҜ”д№ӢеүҚи®Ўз®—еҮәзҡ„з»“жһңе°ҸгҖӮ
д»Јз Ғи§ЈиҜ»пјҡдёәдәҶе®һзҺ°дёҚйҮҚеӨҚи®Ўз®—пјҢдёҠиҝ°д»Јз ҒеҠ е…ҘдәҶжӣҙеӨҡзҡ„йҖ»иҫ‘еҲӨж–ӯпјҢиҝҷе°ұдҪҝд»Јз ҒеӨҚжқӮеәҰиҝӣдёҖжӯҘеҠ еӨ§гҖӮеҸҜд»ҘжғіиұЎпјҢеҪ“еҲҶз»„ж•°йҮҸиҫғеӨҡпјҢеҲҶз»„жқЎд»¶д№ҹжҜ”иҫғеӨҚжқӮж—¶пјҢжүҖиҰҒд№ҰеҶҷзҡ„д»Јз ҒйҮҸдјҡзӣёеҪ“еӨ§гҖӮ
жҖ»з»“пјҡеҸҜд»Ҙе®һзҺ°жң¬жЎҲдҫӢпјҢдҪҶд»Јз ҒеӨҚжқӮзЁҚжҳҫеӨҚжқӮгҖӮ
第дёүж–№и§ЈеҶіж–№жЎҲ
дёҠиҝ°дҫӢеӯҗд№ҹеҸҜд»Ҙз”ЁPythonгҖҒйӣҶз®—еҷЁгҖҒPerlзӯүиҜӯиЁҖжқҘе®һзҺ°гҖӮе’ҢRиҜӯиЁҖдёҖж ·пјҢиҝҷеҮ з§ҚиҜӯиЁҖйғҪеҸҜд»Ҙе®һзҺ°еӣәе®ҡеҲҶз»„жұҮжҖ»е’Ңз»“жһ„еҢ–ж•°жҚ®зҡ„и®Ўз®—пјҢдёӢйқўз®ҖеҚ•д»Ӣз»ҚйӣҶз®—еҷЁзҡ„и§ЈеҶіж–№жЎҲгҖӮ
дҫӢ1пјҡ
byFac=["ARO","BON","CHO"]
grouped=sales.align@a(byFac, CLIENT)
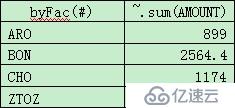
grouped.new(byFac(#), ~.sum(AMOUNT))
и®Ўз®—з»“жһңпјҡ

дҫӢ2пјҡ
д»Јз Ғе’ҢдҫӢ1е®Ңе…ЁдёҖж ·пјҢжӯӨеӨ„зңҒз•ҘгҖӮ
и®Ўз®—з»“жһңпјҡ
еҰӮжһңжғіз»ҹи®ЎеӨҡдҪҷз»„зҡ„жұҮжҖ»еҖјпјҢеҲҷд»Јз ҒеҸӘйңҖзЁҚдҪңж”№еҠЁпјҡ
byFac=["ARO","BON","CHO","ZTOZ"]
grouped=sales.align@a@n(byFac,CLIENT)
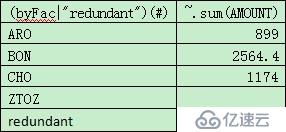
grouped.new((byFac|"redundant")(#), ~.sum(AMOUNT))
зәўиүІйғЁеҲҶеҚіж”№еҠЁпјҢе…¶дёӯ@nиЎЁзӨәеңЁз»“жһңйӣҶдёӯеўһеҠ еӨҡдҪҷзҡ„дёҖз»„пјҢеҸҜд»ҘзңӢеҲ°пјҢиҝҷз§ҚеҶҷжі•иҰҒжҜ”Rзҡ„д»Јз Ғжҳ“дәҺжҺҢжҸЎгҖӮ
и®Ўз®—з»“жһңпјҡ
дҫӢ3
еҜ№дәҺз®ҖеҚ•зҡ„жқЎд»¶еҲҶз»„пјҢйӣҶз®—еҷЁеҸӘйңҖе°Ҷд№ӢеүҚзҡ„alignеҮҪж•°жҚўдёәenumпјҢе…¶д»–ең°ж–№дёҚеҸҳгҖӮ
byFac=["?<=1000" ,"?>1000 && ?<=2000","?>2000 && ?<=4000","?>4000"]
grouped=sales.enum(byFac,AMOUNT)
grouped.new(byFac(#),~.sum(AMOUNT))
и®Ўз®—з»“жһңпјҡ

йӣҶз®—еҷЁ
йңҖиҰҒи®Ўз®—йҮҚеӨҚзҡ„ж•°жҚ®ж—¶пјҢеҸӘйңҖиҰҒеңЁд№ӢеүҚзҡ„д»Јз ҒдёӯеҠ е…Ҙ@rйҖүйЎ№гҖӮ
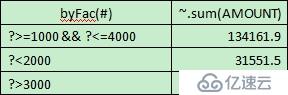
byFac=["?>=1000 && ?<=4000","?<2000" ,"?>3000"]
grouped=sales.enum@r(byFac,AMOUNT)
grouped.new(byFac(#),~.sum(AMOUNT))
и®Ўз®—з»“жһңпјҡ

йӣҶз®—еҷЁ
дёҚйңҖиҰҒи®Ўз®—йҮҚеӨҚзҡ„ж•°жҚ®ж—¶пјҢеҺ»жҺү@rйҖүйЎ№еҚіеҸҜпјҢе’Ңз®ҖеҚ•жқЎд»¶еҲҶз»„е®Ңе…ЁдёҖж ·гҖӮ
byFac=["?>=1000 && ?<=4000","?<2000" ,"?>3000"]
grouped=sales.enum(byFac,AMOUNT)
grouped.new(byFac(#),~.sum(AMOUNT))
и®Ўз®—з»“жһңпјҡ
еҸҜд»ҘзңӢеҲ°пјҢйӣҶз®—еҷЁеҸӘйңҖиҰҒalignе’ҢenumиҝҷдёӨдёӘеҮҪж•°е°ұеҸҜд»Ҙе®һзҺ°жүҖжңүзұ»еһӢзҡ„еӣәе®ҡеҲҶз»„жұҮжҖ»пјҢд»Јз Ғз»“жһ„дёҖиҮҙпјҢи§ЈеҶіжҖқи·Ҝз®ҖеҚ•гҖӮ





