这篇文章给大家分享的是有关python怎么判断txt每行内容中是否包含子串并重新写入保存的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
假设需要批量处理多个txt文件,然后将包含子串的内容写入一个txt文件中,这里假设我的子串为"_9"和“_10”
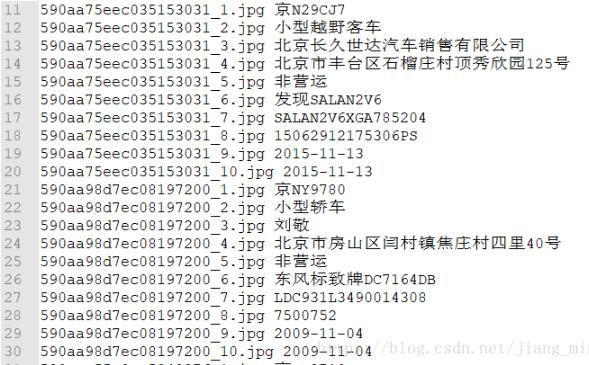
下面就是我想要得到的其中两行内容(实际上还有很多行哈哈):

直接上代码:
#! /usr/bin/python # -*- coding:UTF-8 -*- import os import os.path import string
txt文件所在的路径和需要保存的目标路径(根据自己的实际目录进行更改即可):
Crop-Ocr_txt文件夹内放置了我需要批量处理的所有txt,我在同级目录下新建一个文件夹名为1000_simple_Ocrtxts,这里目标路径随意就好,能方便找到就行
txt_path = 'D:/youxinProjections/trafic-youxin/MobileNet_v1/obtain_qq_json_new/Crop_Ocr_txt/' des_txt_path = 'D:/youxinProjections/trafic-youxin/MobileNet_v1/obtain_qq_json_new/1000_simple_OCRtxts/' txt_files = os.listdir(txt_path) #txt_files能得到该目录下的所有txt文件的文件名
定义一个函数专门用来取包含子串的内容并写入到新的txt文件中,在后边的主函数中直接调用这个函数就行就行:
def select_simples():
for txtfile in txt_files:
if not os.path.isdir(txtfile):
in_file = open(txt_path + txtfile, 'r')
out_file = open(des_txt_path + txtfile, 'a') # 此处自动新建一个文件夹和txtfile的文件名相同,'a'为自动换行写入
lines = in_file.readlines()
for line in lines:
str_name = line.split(" ")[0] # 这里获取的是txt文件中每行内容以空格隔开的第一个元素,也就是我自己txt文件中的*.jpg那一块内容str1 = '_9' # 这就是我要判断的子串 str2 = '_10' # 这也是子串 #if (string.find(str_name, str1)!=-1) or (string.find(str_name, str2)): if (str1 in str_name) or (str2 in str_name): # in 可以判断在str_name中是否包含有两个子串, out_file.write(line) # 若包含子串,则将该行内容全部重新写入新的txt文件 print(str_name) out_file.close()
主函数到了!:
if __name__ == '__main__':
select_simples()
晒一下最后的结果:
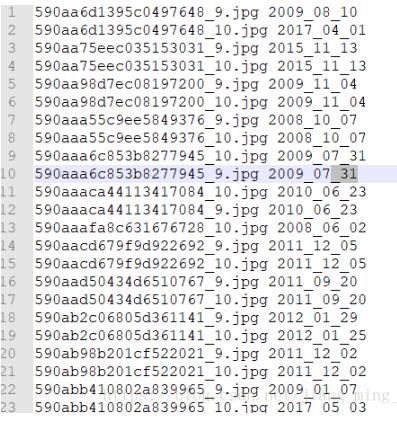
完美有没有!!!
补充知识:python判断文件中有否重复行,逐行读文件检测另一文件中是否存在所读内容
我就废话不多说了,还是直接看代码吧!
#!/bin/env python
# coding:utf-8
#程序功能是为了完成判断文件中是否有重复句子
#并将重复句子打印出来
res_list = []
f = open('./downloadmd5.txt','r')
res_dup = []
index = 0
file_dul = open('./r_d.txt', 'w')
file_last = open('./r_nd.txt','w')
for line in f.readlines():
index = index + 1
if line in res_list:
temp_str = ""
#temp_str = temp_str + str(index) + ',' #要变为str才行
temp_line = ''.join(line)
temp_str = temp_str+temp_line
#最终要变为str类型
file_dul.write(temp_str); #将重复的存入到文件中
else:
res_list.append(line)
file_last.write(line)#!/bin/env python
# coding:utf-8
import re
res_list = []
f = open('./md5.txt','r')
f2 = open('./virus.conf','r')
index = 0
#没重复的文件名
file_dul = open('./m_nd.txt', 'w')
#重复的文件名
file_ex = open('./m_d.txt', 'w')
virstr = f2.read();
for line in f.readlines():
line=line.strip('\n')
if(re.search(line, virstr)):
line = line + '\n'
file_ex.write(line);
#调用删除rm -rf filename
else:
line = line+'\n'
file_dul.write(line);感谢各位的阅读!关于“python怎么判断txt每行内容中是否包含子串并重新写入保存”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





