еҹәдәҺTensorflowй«ҳйҳ¶иҜ»еҶҷзҡ„зӨәдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іеҹәдәҺTensorflowй«ҳйҳ¶иҜ»еҶҷзҡ„зӨәдҫӢеҲҶжһҗзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
еүҚиЁҖ
tensorflowжҸҗдҫӣдәҶеӨҡз§ҚиҜ»еҶҷж–№ејҸпјҢжҲ‘们жңҖеёёи§Ғзҡ„е°ұжҳҜдҪҝз”Ёtf.placeholder()иҝҷз§Қж–№жі•пјҢдҪҝз”ЁиҝҷдёӘж–№жі•йңҖиҰҒжҲ‘们жҸҗеүҚеӨ„зҗҶеҘҪж•°жҚ®ж јејҸпјҢдёҚиҝҮиҝҷз§ҚеӨ„зҗҶж–№жі•д№ҹжңүзјәйҷ·пјҡдёҚдҫҝдәҺеӯҳеӮЁе’ҢдёҚеҲ©дәҺеҲҶеёғејҸеӨ„зҗҶпјҢеӣ жӯӨпјҢTensorFlowжҸҗдҫӣдәҶдёҖдёӘж ҮеҮҶзҡ„иҜ»еҶҷж јејҸе’ҢеӯҳеӮЁеҚҸи®®пјҢдёҚд»…еҰӮжӯӨпјҢTensorFlowд№ҹжҸҗдҫӣдәҶеҹәдәҺеӨҡзәҝзЁӢйҳҹеҲ—зҡ„иҜ»еҸ–ж–№ејҸпјҢй«ҳж•ҲиҖҢз®ҖжҙҒпјҢиҜ»еҸ–йҖҹеәҰд№ҹжӣҙеҝ«пјҢжҚ®дёҖдёӘеҚҡдё»иҜҙйҖҹеәҰиғҪжҸҗй«ҳ10еҖҚпјҢзӣёеҪ“зҡ„иҜұдәә.гҖҗдёӢйқўзҡ„е®һйӘҢеқҮжҳҜеңЁtensorflow1.0зҡ„зҺҜеўғдёӢиҝӣиЎҢгҖ‘
tensorflowзҡ„exampleи§Јжһҗ
exampleеҚҸи®®
еңЁTensorFlowе®ҳж–№githubж–ҮжЎЈйҮҢйқўпјҢжңүдёӘexample.protoзҡ„ж–Ү件,иҝҷдёӘж–Ү件иҜҰз»ҶиҜҙжҳҺдәҶTensorFlowйҮҢйқўзҡ„exampleеҚҸи®®пјҢдёӢйқўжҲ‘е°Ҷз®ҖиҰҒеҸҷиҝ°дёҖдёӢгҖӮ
tensorflowзҡ„exampleеҢ…еҗ«зҡ„жҳҜеҹәдәҺkey-valueеҜ№зҡ„еӯҳеӮЁж–№жі•пјҢе…¶дёӯkeyжҳҜдёҖдёӘеӯ—з¬ҰдёІпјҢе…¶жҳ е°„еҲ°зҡ„жҳҜfeatureдҝЎжҒҜпјҢfeatureеҢ…еҗ«дёүз§Қзұ»еһӢпјҡ
BytesListпјҡеӯ—з¬ҰдёІеҲ—иЎЁ
FloatListпјҡжө®зӮ№ж•°еҲ—иЎЁ
Int64Listпјҡ64дҪҚж•ҙж•°еҲ—иЎЁ
д»ҘдёҠдёүз§Қзұ»еһӢйғҪжҳҜеҲ—иЎЁзұ»еһӢпјҢж„Ҹе‘ізқҖйғҪиғҪеӨҹиҝӣиЎҢжӢ“еұ•,дҪҶжҳҜд№ҹжҳҜеӣ дёәиҝҷз§Қеј№жҖ§ж јејҸпјҢжүҖд»ҘеңЁи§Јжһҗзҡ„ж—¶еҖҷпјҢйңҖиҰҒеҲ¶е®ҡи§ЈжһҗеҸӮж•°пјҢиҝҷдёӘзЁҚеҗҺдјҡи®ІгҖӮ
еңЁTensorFlowдёӯпјҢexampleжҳҜжҢүз…§иЎҢиҜ»зҡ„пјҢиҝҷдёӘйңҖиҰҒж—¶еҲ»и®°дҪҸпјҢжҜ”еҰӮеӯҳеӮЁ 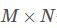 зҹ©йҳөпјҢдҪҝз”ЁByteListеӯҳеӮЁзҡ„иҜқпјҢйңҖиҰҒ еӨ§е°Ҹзҡ„еҲ—иЎЁпјҢжҢүз…§жҜҸдёҖиЎҢзҡ„иҜ»еҸ–ж–№ејҸеӯҳж”ҫгҖӮ
зҹ©йҳөпјҢдҪҝз”ЁByteListеӯҳеӮЁзҡ„иҜқпјҢйңҖиҰҒ еӨ§е°Ҹзҡ„еҲ—иЎЁпјҢжҢүз…§жҜҸдёҖиЎҢзҡ„иҜ»еҸ–ж–№ејҸеӯҳж”ҫгҖӮ
tf.tain.example
е®ҳж–№з»ҷдәҶдёҖдёӘexampleзҡ„дҫӢеӯҗпјҡ
An Example for a movie recommendation application:
features {
feature {
key: "age"
value { float_list {
value: 29.0
}}
}
feature {
key: "movie"
value { bytes_list {
value: "The Shawshank Redemption"
value: "Fight Club"
}}
}
feature {
key: "movie_ratings"
value { float_list {
value: 9.0
value: 9.7
}}
}
feature {
key: "suggestion"
value { bytes_list {
value: "Inception"
}}
}дёҠйқўзҡ„дҫӢеӯҗдёӯеҢ…еҗ«дёҖдёӘfeaturesпјҢfeaturesйҮҢйқўеҢ…еҗ«дёҖдәӣfeatureпјҢе’Ңд№ӢеүҚиҜҙзҡ„дёҖж ·пјҢжҜҸдёӘfeatureйғҪжҳҜз”ұй”®еҖјеҜ№з»„жҲҗзҡ„пјҢе…¶keyжҳҜдёҖдёӘеӯ—з¬ҰдёІпјҢе…¶valueжҳҜдёҠйқўжҸҗеҲ°зҡ„дёүз§Қзұ»еһӢд№ӢдёҖгҖӮ
ExampleдёӯжңүеҮ дёӘдёҖиҮҙжҖ§и§„еҲҷйңҖиҰҒжіЁж„Ҹпјҡ
еҰӮжһңдёҖдёӘexampleзҡ„feature K зҡ„ж•°жҚ®зұ»еһӢжҳҜ TTпјҢйӮЈд№ҲжүҖжңүе…¶д»–зҡ„жүҖжңүfeature KйғҪеә”иҜҘжҳҜиҝҷдёӘж•°жҚ®зұ»еһӢ
feature K зҡ„value listзҡ„itemдёӘж•°еҸҜиғҪеңЁдёҚеҗҢзҡ„exampleдёӯжҳҜдёҚдёҖж ·еӨҡзҡ„пјҢиҝҷдёӘеҸ–еҶідәҺдҪ зҡ„йңҖжұӮ
еҰӮжһңеңЁдёҖдёӘexampleдёӯжІЎжңүfeature kпјҢйӮЈд№ҲеҰӮжһңеңЁи§Јжһҗзҡ„ж—¶еҖҷжҢҮе®ҡдёҖдёӘй»ҳи®ӨеҖјзҡ„иҜқпјҢйӮЈд№Ҳе°Ҷдјҡиҝ”еӣһдёҖдёӘй»ҳи®ӨеҖј
еҰӮжһңдёҖдёӘfeature k дёҚеҢ…еҗ«д»»дҪ•зҡ„valueеҖјпјҢйӮЈд№Ҳе°Ҷдјҡиҝ”еӣһдёҖдёӘз©әзҡ„tensorиҖҢдёҚжҳҜй»ҳи®ӨеҖј
tf.train.SequenceExample
sequence_exampleиЎЁзӨәзҡ„жҳҜдёҖдёӘжҲ–иҖ…еӨҡдёӘsequencesпјҢеҗҢж—¶иҝҳеҢ…жӢ¬дёҠдёӢж–ҮcontextпјҢе…¶дёӯпјҢcontextиЎЁзӨәзҡ„жҳҜfeature_listsзҡ„жҖ»дҪ“зү№еҫҒпјҢеҰӮж•°жҚ®йӣҶзҡ„й•ҝеәҰзӯүпјҢfeature_listеҢ…еҗ«дёҖдёӘkeyпјҢдёҖдёӘvalueпјҢvalueиЎЁзӨәзҡ„жҳҜfeaturesйӣҶеҗҲ(feature_lists)пјҢеҗҢж ·пјҢе®ҳж–№жәҗз Ғд№ҹз»ҷеҮәдәҶsequence_exampleзҡ„дҫӢеӯҗпјҡ
//ontext: {
feature: {
key : "locale"
value: {
bytes_list: {
value: [ "pt_BR" ]
}
}
}
feature: {
key : "age"
value: {
float_list: {
value: [ 19.0 ]
}
}
}
feature: {
key : "favorites"
value: {
bytes_list: {
value: [ "Majesty Rose", "Savannah Outen", "One Direction" ]
}
}
}
}
feature_lists: {
feature_list: {
key : "movie_ratings"
value: {
feature: {
float_list: {
value: [ 4.5 ]
}
}
feature: {
float_list: {
value: [ 5.0 ]
}
}
}
}
feature_list: {
key : "movie_names"
value: {
feature: {
bytes_list: {
value: [ "The Shawshank Redemption" ]
}
}
feature: {
bytes_list: {
value: [ "Fight Club" ]
}
}
}
}
feature_list: {
key : "actors"
value: {
feature: {
bytes_list: {
value: [ "Tim Robbins", "Morgan Freeman" ]
}
}
feature: {
bytes_list: {
value: [ "Brad Pitt", "Edward Norton", "Helena Bonham Carter" ]
}
}
}
}
}дёҖиҮҙжҖ§зҡ„sequence_exampleйҒөеҫӘд»ҘдёӢ规еҲҷпјҡ
1гҖҒcontextдёӯпјҢжүҖжңүfeature kиҰҒдҝқжҢҒж•°жҚ®зұ»еһӢдёҖиҮҙжҖ§
2гҖҒдёҖдәӣexampleдёӯзҡ„жҹҗдәӣfeature_lists LеҸҜиғҪдјҡдёўеӨұпјҢеҰӮжһңеңЁи§Јжһҗзҡ„ж—¶еҖҷе…Ғи®ёдёәз©әзҡ„иҜқпјҢйӮЈд№ҲеңЁи§Јжһҗзҡ„ж—¶еҖҷеӣһиҝ”еӣһдёҖдёӘз©әзҡ„list
3гҖҒfeature_listsеҸҜиғҪжҳҜз©әзҡ„
4гҖҒеҰӮжһңдёҖдёӘfeature_listжҳҜйқһз©әзҡ„пјҢйӮЈд№Ҳе…¶йҮҢйқўзҡ„жүҖжңүfeatureйғҪеҝ…йЎ»жҳҜдёҖдёӘж•°жҚ®зұ»еһӢ
5гҖҒеҰӮжһңдёҖдёӘfeature_listжҳҜйқһз©әзҡ„пјҢйӮЈд№ҲеҜ№дәҺйҮҢйқўзҡ„featureзҡ„й•ҝеәҰжҳҜдёҚжҳҜйңҖиҰҒдёҖж ·зҡ„пјҢиҝҷдёӘеҸ–еҶідәҺи§Јжһҗж—¶еҖҷзҡ„еҸӮж•°
tensorflow зҡ„parse exampleи§Јжһҗ
еңЁе®ҳж–№д»Јз Ғ*[parsing_ops.py]*дёӯжңүе…ідәҺparse exampleзҡ„иҜҰз»Ҷд»Ӣз»ҚпјҢжҲ‘еңЁиҝҷйҮҢеҶҚеҸҷиҝ°дёҖдёӢгҖӮ
tf.parse_example
жқҘзңӢtf.parse_exampleзҡ„ж–№жі•е®ҡд№үпјҡ
def parse_example(serialized, features, name=None, example_names=None)
parse_exampleжҳҜжҠҠexampleи§ЈжһҗдёәиҜҚе…ёеһӢзҡ„tensor
еҸӮж•°еҗ«д№үпјҡ
serialized:дёҖдёӘbatchзҡ„еәҸеҲ—еҢ–зҡ„example
features:и§Јжһҗexampleзҡ„规еҲҷ
nameпјҡеҪ“еүҚж“ҚдҪңзҡ„еҗҚеӯ—
example_name:еҪ“еүҚи§Јжһҗexampleзҡ„protoеҗҚз§°
иҝҷйҮҢйҮҚзӮ№иҰҒиҜҙзҡ„жҳҜ第дәҢдёӘеҸӮж•°пјҢд№ҹе°ұжҳҜfeaturesпјҢfeaturesжҳҜжҠҠserializedзҡ„exampleдёӯжҢүз…§й”®еҖјжҳ е°„еҲ°дёүз§Қtensor: 1,VarlenFeature 2, SparseFeature 3,FixedLenFeature
дёӢйқўеҜ№иҝҷдёүз§Қжҳ е°„ж–№ејҸеҒҡдёҖдёӘз®ҖиҰҒзҡ„еҸҷиҝ°пјҡ
VarlenFeature
жҳҜжҢүз…§й”®еҖјжҠҠexampleзҡ„valueжҳ е°„еҲ°SpareTensorеҜ№иұЎпјҢеҒҮи®ҫжҲ‘们жңүеҰӮдёӢзҡ„serializedж•°жҚ®пјҡ
serialized = [
features
{ feature { key: "ft" value { float_list { value: [1.0, 2.0] } } } },
features
{ feature []},
features
{ feature { key: "ft" value { float_list { value: [3.0] } } }
]дҪҝз”ЁVarLenFeaturesж–№жі•пјҡ
features={
"ft":tf.VarLenFeature(tf.float32)
}йӮЈд№ҲжҲ‘们е°Ҷеҫ—еҲ°зҡ„жҳҜпјҡ
{"ft": SparseTensor(indices=[[0, 0], [0, 1], [2, 0]],
values=[1.0, 2.0, 3.0],
dense_shape=(3, 2)) }еҸҜи§ҒпјҢжҳҫзӨәзҡ„indicesжҳҜftеҖјзҡ„зҙўеј•пјҢvaluesжҳҜеҖјпјҢdense_shapeжҳҜindicesзҡ„shape
FixedLenFeature
иҖҢFixedLenFeatureжҳҜжҢүз…§й”®еҖјеҜ№е°Ҷfeaturesжҳ е°„еҲ°еӨ§е°Ҹдёә[serilized.size(),df.shape]зҡ„зҹ©йҳөпјҢиҝҷйҮҢзҡ„FixLenFeatureжҢҮзҡ„жҳҜжҜҸдёӘй”®еҖјеҜ№еә”зҡ„featureзҡ„sizeжҳҜдёҖж ·зҡ„гҖӮеҜ№дәҺдёҠйқўзҡ„дҫӢеӯҗпјҢеҰӮжһңдҪҝз”Ёпјҡ
features: {
"ft": FixedLenFeature([2], dtype=tf.float32, default_value=-1),
}йӮЈд№ҲжҲ‘们е°Ҷеҫ—еҲ°пјҡ
{"ft": [[1.0, 2.0], [3.0, -1.0]]}еҸҜи§Ғиҝ”еӣһзҡ„еҖјжҳҜдёҖдёӘ[2,2]зҡ„зҹ©йҳөпјҢеҰӮжһңиҝ”еӣһзҡ„й•ҝеәҰдёҚи¶із»ҷе®ҡзҡ„й•ҝеәҰпјҢйӮЈд№Ҳе°ҶдјҡдҪҝз”Ёй»ҳи®ӨеҖјеҺ»еЎ«е……гҖӮ
гҖҗжіЁж„ҸпјҡгҖ‘
дәӢе®һдёҠпјҢеңЁTensorFlow1.0зҺҜеўғдёӢпјҢж №жҚ®е®ҳж–№ж–ҮжЎЈдёҠзҡ„еҶ…е®№пјҢжҲ‘们жҳҜиғҪеӨҹеҫ—еҲ°VarLenFeatureзҡ„еҖјпјҢдҪҶжҳҜеҫ—дёҚеҲ°FixLenFeatureзҡ„еҖјпјҢеӣ жӯӨе»әи®®еҰӮжһңдҪҝз”Ёе®ҡй•ҝзҡ„FixedLenFeatureпјҢдёҖе®ҡиҰҒдҝқиҜҒеҜ№еә”зҡ„ж•°жҚ®жҳҜзӯүй•ҝзҡ„гҖӮ
еҒҡдёӘиҜ•йӘҢжқҘиҜҙжҳҺпјҡ
#coding=utf-8
import tensorflow as tf
import os
keys=[[1.0],[],[2.0,3.0]]
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def make_example(key):
example = tf.train.Example(features=tf.train.Features(
feature={
'ft':tf.train.Feature(float_list=tf.train.FloatList(value=key))
}
))
return example
filename="tmp.tfrecords"
if os.path.exists(filename):
os.remove(filename)
writer = tf.python_io.TFRecordWriter(filename)
for key in keys:
ex = make_example(key)
writer.write(ex.SerializeToString())
writer.close()
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(["tmp.tfrecords"],num_epochs=1)
_,serialized_example =reader.read(filename_queue)
# coord = tf.train.Coordinator()
# threads = tf.train.start_queue_runners(sess=sess,coord=coord)
batch = tf.train.batch(tensors=[serialized_example],batch_size=3)
features={
"ft":tf.VarLenFeature(tf.float32)
}
#key_parsed = tf.parse_single_example(make_example([1,2,3]).SerializeToString(),features)
key_parsed = tf.parse_example(batch,features)
#start the queue
print tf.contrib.learn.run_n(key_parsed)
#[]means scalar
features={
"ft":tf.FixedLenFeature(shape=[2],dtype=tf.float32)
}
key_parsed = tf.parse_example(batch,features)
print tf.contrib.learn.run_n(key_parsed)з»“жһңиҝ”еӣһеҰӮдёӢпјҡ
[{'ft': SparseTensorValue(indices=array([[0, 0],
[2, 0],
[2, 1]]), values=array([ 1., 2., 3.], dtype=float32), dense_shape=array([3, 2]))}]
InvalidArgumentError (see above for traceback): Name: <unknown>, Key: ft, Index: 0. Number of float values != expected. Values size: 1 but output shape: [2]еҸҜи§ҒпјҢеҜ№дәҺVarLenFeatureпјҢжҳҜиғҪиҝ”еӣһжӯЈеёёз»“жһңзҡ„пјҢдҪҶжҳҜеҜ№дәҺFixedLenFeatureеҲҷиҝ”еӣһsizeдёҚеҜ№пјҢеҸҜи§ҒеҰӮжһңеҜ№дәҺиҫ№й•ҝзҡ„ж•°жҚ®иҝҳжҳҜдёҚиҰҒдҪҝз”ЁFixedLenFeatureдёәеҘҪгҖӮ
еҰӮжһңжҠҠж•°жҚ®и®ҫзҪ®дёә[[1.0,2.0],[2.0,3.0]],йӮЈд№ҲFixedLenFeatureиҝ”еӣһзҡ„жҳҜпјҡ
[{'ft': array([[ 1., 2.],
[ 2., 3.]], dtype=float32)}]иҝҷжҳҜжӯЈзЎ®зҡ„з»“жһңгҖӮ
SparseFeatureеҸҜд»Ҙд»ҺдёӢйқўзҡ„дҫӢеӯҗжқҘиҜҙжҳҺпјҡ
`serialized`:
```
[
features {
feature { key: "val" value { float_list { value: [ 0.5, -1.0 ] } } }
feature { key: "ix" value { int64_list { value: [ 3, 20 ] } } }
},
features {
feature { key: "val" value { float_list { value: [ 0.0 ] } } }
feature { key: "ix" value { int64_list { value: [ 42 ] } } }
}
]
```
And arguments
```
example_names: ["input0", "input1"],
features: {
"sparse": SparseFeature(
index_key="ix", value_key="val", dtype=tf.float32, size=100),
}
```
Then the output is a dictionary:
```python
{
"sparse": SparseTensor(
indices=[[0, 3], [0, 20], [1, 42]],
values=[0.5, -1.0, 0.0]
dense_shape=[2, 100]),
}
```зҺ°еңЁжҳҺзҷҪдәҶExampleзҡ„еҚҸи®®е’Ңtf.parse_exampleзҡ„ж–№жі•д№ӢеҗҺпјҢжҲ‘们еҶҚзңӢзңӢзңӢеҮ дёӘз®ҖеҚ•зҡ„parse_example
tf.parse_single_example
еҢәеҲ«дәҺtf.parse_exampleпјҢtf.parse_single_exampleеҸӘжҳҜе°‘дәҶдёҖдёӘbatchиҖҢе·ІпјҢе…¶дҪҷзҡ„йғҪжҳҜдёҖж ·зҡ„пјҢжҲ‘们зңӢд»Јз Ғпјҡ
#coding=utf-8
import tensorflow as tf
import os
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def make_example(key):
example = tf.train.Example(features=tf.train.Features(
feature={
'ft':tf.train.Feature(float_list=tf.train.FloatList(value=key))
}
))
return example
features={
"ft":tf.FixedLenFeature(shape=[3],dtype=tf.float32)
}
key_parsed = tf.parse_single_example(make_example([1.0,2.0,3.0]).SerializeToString(),features)
print tf.contrib.learn.run_n(key_parsed)з»“жһңиҝ”еӣһдёәпјҡ
[{'ft': array([ 1., 2., 3.], dtype=float32)}]tf.parse_single_sequence_example
tf.parse_single_sequence_exampleеҜ№еә”зҡ„жҳҜtf.train,SequenceExample,жҲ‘们д»ҘдёӢйқўд»Јз ҒиҜҙжҳҺпјҢsingle_sequence_exampleзҡ„з”Ёжі•пјҡ
#coding=utf-8
import tensorflow as tf
import os
keys=[[1.0,2.0],[2.0,3.0]]
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def make_example(locale,age,score,times):
example = tf.train.SequenceExample(
context=tf.train.Features(
feature={
"locale":tf.train.Feature(bytes_list=tf.train.BytesList(value=[locale])),
"age":tf.train.Feature(int64_list=tf.train.Int64List(value=[age]))
}),
feature_lists=tf.train.FeatureLists(
feature_list={
"movie_rating":tf.train.FeatureList(feature=[tf.train.Feature(float_list=tf.train.FloatList(value=score)) for i in range(times)])
}
)
)
return example.SerializeToString()
context_features = {
"locale": tf.FixedLenFeature([],dtype=tf.string),
"age": tf.FixedLenFeature([],dtype=tf.int64)
}
sequence_features = {
"movie_rating": tf.FixedLenSequenceFeature([3], dtype=tf.float32,allow_missing=True)
}
context_parsed, sequence_parsed = tf.parse_single_sequence_example(make_example("china",24,[1.0,3.5,4.0],2),context_features=context_features,sequence_features=sequence_features)
print tf.contrib.learn.run_n(context_parsed)
print tf.contrib.learn.run_n(sequence_parsed)з»“жһңжү“еҚ°дёәпјҡ
[{'locale': 'china', 'age': 24}]
[{'movie_rating': array([[ 1. , 3.5, 4. ],
[ 1. , 3.5, 4. ]], dtype=float32)}]tf.parse_single_sequence_exampleзҡ„иҮӘеҠЁиЎҘйҪҗ
еңЁеёёз”Ёзҡ„ж–Үжң¬еӨ„зҗҶж–№йқўпјҢз”ұдәҺж–Үжң¬з»ҸеёёжҳҜйқһе®ҡй•ҝзҡ„пјҢеӣ жӯӨйңҖиҰҒз»ҸеёёиЎҘйҪҗж“ҚдҪңпјҢдҫӢеҰӮдҪҝз”ЁCNNиҝӣиЎҢж–Үжң¬еҲҶзұ»зҡ„ж—¶еҖҷе°ұйңҖиҰҒиҝӣиЎҢpaddingж“ҚдҪңпјҢйҖҡеёёжҲ‘们жҠҠpaddingзҡ„зҙўеј•и®ҫзҪ®дёә0пјҢиҖҢдё”еңЁж–Үжң¬йў„еӨ„зҗҶзҡ„ж—¶еҖҷд№ҹйңҖиҰҒйўқеӨ–зҡ„д»Јз ҒиҝӣиЎҢеӨ„зҗҶпјҢиҖҢTensorFlowжҸҗдҫӣдәҶдёҖдёӘжҜ”иҫғеҘҪзҡ„иҮӘеҠЁиЎҘйҪҗе·Ҙе…·пјҢе°ұжҳҜеңЁtf.train.batchйҮҢйқўжҠҠеҸӮж•°dynamic_padи®ҫзҪ®жҲҗTrueпјҢж ·дҫӢеҰӮдёӢпјҡ
#coding=utf-8
import tensorflow as tf
import os
keys=[[1,2],[2]]
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def make_example(key):
example = tf.train.SequenceExample(
context=tf.train.Features(
feature={
"length":tf.train.Feature(int64_list=tf.train.Int64List(value=[len(key)]))
}),
feature_lists=tf.train.FeatureLists(
feature_list={
"index":tf.train.FeatureList(feature=[tf.train.Feature(int64_list=tf.train.Int64List(value=[key[i]])) for i in range(len(key))])
}
)
)
return example.SerializeToString()
filename="tmp.tfrecords"
if os.path.exists(filename):
os.remove(filename)
writer = tf.python_io.TFRecordWriter(filename)
for key in keys:
ex = make_example(key)
writer.write(ex)
writer.close()
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(["tmp.tfrecords"],num_epochs=1)
_,serialized_example =reader.read(filename_queue)
# coord = tf.train.Coordinator()
# threads = tf.train.start_queue_runners(sess=sess,coord=coord)
context_features={
"length":tf.FixedLenFeature([],dtype=tf.int64)
}
sequence_features={
"index":tf.FixedLenSequenceFeature([],dtype=tf.int64)
}
context_parsed, sequence_parsed = tf.parse_single_sequence_example(
serialized=serialized_example,
context_features=context_features,
sequence_features=sequence_features
)
batch_data = tf.train.batch(tensors=[sequence_parsed['index']],batch_size=2,dynamic_pad=True)
result = tf.contrib.learn.run_n({"index":batch_data})
print resultжү“еҚ°з»“жһңеҰӮдёӢпјҡ
[{'index': array([[1, 2],
[2, 0]])}]еҸҜи§ҒиҝҳжҳҜжҜ”иҫғеҘҪз”Ёзҡ„еҠҹиғҪ
tensorflowзҡ„TFRecordsиҜ»еҸ–
еңЁдёҠйқўзҡ„йғЁеҲҶпјҢжҲ‘们еұ•зӨәдәҶе…ідәҺtensorflowзҡ„exampleзҡ„з”Ёжі•е’Ңи§ЈжһҗиҝҮзЁӢпјҢйӮЈд№ҲжҲ‘们иҜҘеҰӮдҪ•дҪҝз”Ёе®ғ们呢пјҹе…¶е®һеңЁдёҠйқўзҡ„еҮ ж®өд»Јз ҒйҮҢйқўд№ҹжңүдҪ“зҺ°пјҢе°ұжҳҜTFRecordsиҝӣиЎҢиҜ»еҶҷпјҢTFRecordsиҜ»еҶҷе…¶е®һеҫҲз®ҖеҚ•,tensorflowжҸҗдҫӣдәҶдёӨдёӘж–№жі•пјҡ
tf.TFRecordReader
tf.TFRecordWriter
йҰ–е…ҲжҲ‘们зңӢдёӢ第дәҢдёӘпјҢд№ҹе°ұжҳҜtf.TFRecordWritreпјҢд№ӢжүҖд»Ҙе…ҲзңӢ第дәҢдёӘзҡ„еҺҹеӣ жҳҜ第дёҖдёӘReaderе°Ҷе’ҢbatchдёҖиө·еңЁдёӢдёҖиҠӮи®Іиҝ°гҖӮ
е…ідәҺTFRecordWriter,еҸҜд»Ҙз”ЁдёӢйқўд»Јз ҒиҜҙжҳҺ,еҒҮи®ҫserilized_objectжҳҜдёҖдёӘе·Із»ҸеәҸеҲ—еҢ–еҘҪзҡ„exampleпјҢйӮЈд№Ҳе…¶еҶҷзҡ„иҝҮзЁӢеҰӮдёӢпјҡ
writer = tf.python_io.TFRecordWriter(filename)
writer.write(serilized_object)
writer.close()
tensorflowзҡ„еӨҡзәҝзЁӢbatchиҜ»еҸ–
иҝҷдёҖиҠӮдё»иҰҒе…іжіЁзҡ„жҳҜеҹәдәҺTFRecordsзҡ„иҜ»еҸ–зҡ„ж–№жі•е’Ңbatchж“ҚдҪңпјҢжҲ‘们еҸҜд»ҘеӣһзңӢдёҖдёӢд№ӢеүҚзҡ„ж–Үз« зҡ„batchж“ҚдҪңпјҡ
Batching
def read_my_file_format(filename_queue):
reader = tf.SomeReader()
key, record_string = reader.read(filename_queue)
example, label = tf.some_decoder(record_string)
processed_example = some_processing(example)
return processed_example, label
def input_pipeline(filenames, batch_size, num_epochs=None):
filename_queue = tf.train.string_input_producer(
filenames, num_epochs=num_epochs, shuffle=True)
example, label = read_my_file_format(filename_queue)
# min_after_dequeue defines how big a buffer we will randomly sample
# from -- bigger means better shuffling but slower start up and more
# memory used.
# capacity must be larger than min_after_dequeue and the amount larger
# determines the maximum we will prefetch. Recommendation:
# min_after_dequeue + (num_threads + a small safety margin) * batch_size
min_after_dequeue = 10000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch(
[example, label], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch
иҝҷйҮҢжҲ‘们жҠҠtf.SomeReader()жҚўжҲҗtf.TFRecordReader()еҚіеҸҜпјҢ然еҗҺеҶҚжҠҠtf.some_decoderжҚўжҲҗжҲ‘们иҮӘе®ҡд№үзҡ„decoderпјҢеҪ“然еңЁdecoderйҮҢйқўжҲ‘们еҸҜд»ҘиҮӘе·ұжҢҮе®ҡparserпјҲд№ҹе°ұжҳҜдёҠж–ҮжҸҗеҲ°зҡ„еҶ…е®№пјүпјҢ然еҗҺжҲ‘们дҪҝз”Ёtf.train.batchжҲ–иҖ…tf.train.shuffle_batchзӯүж“ҚдҪңиҺ·еҸ–еҲ°жҲ‘们йңҖиҰҒйҖҒе…ҘзҪ‘з»ңи®ӯз»ғзҡ„batchеҸӮж•°еҚіеҸҜгҖӮ
еӨҡзәҝзЁӢиҜ»еҸ–batchе®һдҫӢ
жҲ‘дҪҝз”ЁдәҶsoftmaxеӣһеҪ’еҒҡдёҖдёӘз®ҖеҚ•зҡ„зӨәдҫӢпјҢдёӢйқўжҳҜдёҖдёӘеӨҡзәҝзЁӢиҜ»еҸ–batchзҡ„е®һдҫӢдё»иҰҒд»Јз Ғпјҡ
#coding=utf-8
"""
author:luchi
date:24/4/2017
desc:training logistic regression
"""
import tensorflow as tf
from model import Logistic
def read_my_file_format(filename_queue):
reader = tf.TFRecordReader()
_,serilized_example = reader.read(filename_queue)
#parsing example
features = tf.parse_single_example(serilized_example,
features={
"data":tf.FixedLenFeature([2],tf.float32),
"label":tf.FixedLenFeature([],tf.int64)
}
)
#decode from raw data,there indeed do not to change ,but to show common step , i write a case here
# data = tf.cast(features['data'],tf.float32)
# label = tf.cast(features['label'],tf.int64)
return features['data'],features['label']
def input_pipeline(filenames, batch_size, num_epochs=100):
filename_queue = tf.train.string_input_producer([filenames],num_epochs=num_epochs)
data,label=read_my_file_format(filename_queue)
datas,labels = tf.train.shuffle_batch([data,label],batch_size=batch_size,num_threads=5,
capacity=1000+3*batch_size,min_after_dequeue=1000)
return datas,labels
class config():
data_dim=2
label_num=2
learining_rate=0.1
init_scale=0.01
def run_training():
with tf.Graph().as_default(), tf.Session() as sess:
datas,labels = input_pipeline("reg.tfrecords",32)
c = config()
initializer = tf.random_uniform_initializer(-1*c.init_scale,1*c.init_scale)
with tf.variable_scope("model",initializer=initializer):
model = Logistic(config=c,data=datas,label=labels)
fetches = [model.train_op,model.accuracy,model.loss]
feed_dict={}
#init
init_op = tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer())
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
try:
while not coord.should_stop():
# fetches = [model.train_op,model.accuracy,model.loss]
# feed_dict={}
# feed_dict[model.data]=sess.run(datas)
# feed_dict[model.label]=sess.run(labels)
# _,accuracy,loss= sess.run(fetches,feed_dict)
_,accuracy,loss= sess.run(fetches,feed_dict)
print("the loss is %f and the accuracy is %f"%(loss,accuracy))
except tf.errors.OutOfRangeError:
print("done training")
finally:
coord.request_stop()
coord.join(threads)
sess.close()
def main():
run_training()
if __name__=='__main__':
main()иҝҷйҮҢжңүеҮ дёӘеқ‘йңҖиҰҒиҜҙжҳҺдёҖдёӢпјҡ
дҪҝз”ЁдәҶstring_input_producerжҢҮе®ҡnum_epochsд№ӢеҗҺпјҢеңЁеҲқе§ӢеҢ–зҡ„ж—¶еҖҷйңҖиҰҒдҪҝз”Ёпјҡ
init_op = tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer())
sess.run(init_op)
иҰҒдёҚ然дјҡжҠҘй”ҷ
2. дҪҝз”ЁдәҶд»Һж–Ү件иҜ»еҸ–batchд№ӢеҗҺпјҢе°ұдёҚйңҖиҰҒи®ҫзҪ®tf.placeholderдәҶгҖҗйқһеёёйҮҚиҰҒгҖ‘пјҢжҲ‘еңЁиҝҷдёӘеқ‘йҮҢе‘ҶдәҶеҘҪд№…пјҢеҰӮжһңдҪҝз”ЁдәҶtf.placeholderдёҖжҳҜдјҡжҠҘй”ҷдёәtensorеҜ№иұЎиғҪйҖҒе…ҘеҲ°tf.placeholderдёӯпјҢеҸҰеӨ–дёҖдёӘжҳҜе°ұз®—дҪҝз”Ёsess.run(batch_data),д№ҹдјҡеӯҳеңЁжЁЎеһӢдёҚиғҪ收ж•ӣзҡ„й—®йўҳпјҢжүҖд»ҘеҲҮи®°еҲҮи®°
з»“жһңжҳҫзӨәеҰӮдёӢпјҡ
the loss is 0.156685 and the accuracy is 0.937500
the loss is 0.185438 and the accuracy is 0.968750
the loss is 0.092628 and the accuracy is 0.968750
the loss is 0.059271 and the accuracy is 1.000000
the loss is 0.088685 and the accuracy is 0.968750
the loss is 0.271341 and the accuracy is 0.968750
the loss is 0.244190 and the accuracy is 0.968750
the loss is 0.136841 and the accuracy is 0.968750
the loss is 0.115607 and the accuracy is 0.937500
the loss is 0.080254 and the accuracy is 1.000000
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңеҹәдәҺTensorflowй«ҳйҳ¶иҜ»еҶҷзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ





