说到爬虫大家可能会觉得很NB的东西,可以爬小电影,羞羞图,没错就是这样的。在node爬虫方面,我也是个新人,这篇文章主要是给大家分享几种实现node
爬虫的方式。第一种方式,采用node,js中的 superagent+request + cheerio。cheerio是必须的,它相当于node版的jQuery,用过jQuery的同学会非常容易上手。它
主要是用来获取抓取到的页面元素和其中的数据信息。superagent是node里一个非常方便的、轻量的、渐进式的第三方客户端请求代理模块,用他来请求目标页面。
node中,http模块也可作为客户端使用(发送请求),第三方模块request对其使用方法进行了封装,操作更方便。以下是三者的引入方法:

接下来我们开始请求要爬取的目标页面。申明目标页面比如新浪网首页:

如新浪首页部分代码
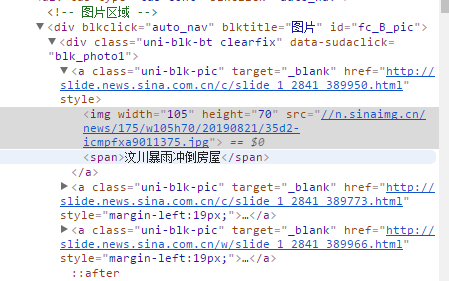
通过superagent请求目标网站,获取到网站内容,通过cheerio.load方法引入要解析的html
cheerio中的有关DOM操作的方式

此处采用 .each(function(index,element){...})方式遍历需要的元素

返回结果如下:

若要将文字内容存储可采用以下方式:
引入fs模块const fs= require("fs")
引入path模块 const path=require("path")
Node.js 内置的fs模块就是文件系统模块,负责读写文件。和所有其他JS模块不同的是,fs模块同时提供了异步和同步的方法。
在上述方法中调用存储文字内容mkdirs方法
//存放数据
mkdirs('./content2',saveContent); (注: content2是新建文件名;saveContent是回调函数)
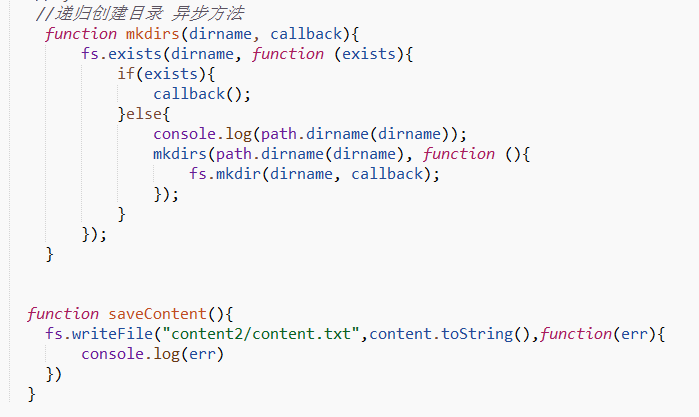
文字内容最终将存储在content2中的content.txt文件中
若想存储图片可采用以下方式:

第二种方式: 使用Nightmare自动化测试工具。
这里介绍一下nightmare工具的用途:
Electron可以让你使用纯JavaScript调用Chrome丰富的原生的接口来创造桌面应用。你可以把它看作一个专注于桌面应用的Node.js的变体,而不是Web服务器。
其基于浏览器的应用方式可以极方便的做各种响应式的交互
Nightmare是一个基于Electron的框架,针对Web自动化测试和爬虫,因为其具有跟PlantomJS一样的自动化测试的功能可以在页面上模拟用户的行为触发一些异步数据加载,
也可以跟Request库一样直接访问URL来抓取数据,并且可以设置页面的延迟时间,所以无论是手动触发脚本还是行为触发脚本都是轻而易举的。
const Nightmare=require("nightmare") //自动化测试包 ,处理动态页面
const nightmare=Nightmare({show: true}) show:true时,运行node可以显示内置模拟浏览器

运行结束后,会在image2中存储下载的图片。
好了,文章就到这里了,有什么问题欢迎小伙伴指正。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





