1 什么是selenium
Selenium 是一个基于浏览器的自动化工具,它提供了一种跨平台、跨浏览器的端到端的web自动化解决方案。Selenium主要包括三部分:Selenium IDE、Selenium WebDriver 和Selenium Grid:
本文中主要使用python结合Selenium WebDriver库进行自动化测试框架的搭建。
2 自动化测试框架
一个典型的自动化测试框架一般包括用例管理模块、自动化执行控制器、报表生成模块和日志模块等,这些模块之间不是相互孤立的,而是相辅相成的。
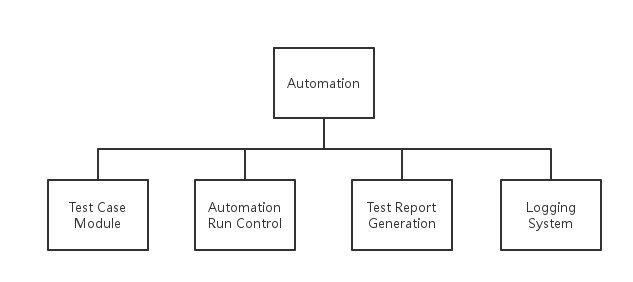
下面来介绍下每个模块的逻辑单元:
用例管理模块包括用例的添加、修改、删除等操作单元,这些单元也会涉及到用例书写的模式,测试数据的管理、可复用库等
控制器是自动化用例执行的组织模块,主要负责以什么方式去执行用例。比较典型的控制器有用户图形界面(GUI)和“commandline+文件”两种。
报表生成模块主要负责执行完用例以后生成报表,报表一般以HTML格式居多,信息主要包括用例的执行情况及相应的总结报告。另外还可以添加发送邮件功能。
日志模块主要用来记录用例的执行情况,以便于更高效的调查用例失败信息及追踪用例执行情况。
3 自动化框架的设计与实现
3.1 需求分析
测试对象是一个典型的后台系统的Web展现平台,基于此平台设计的自动化框架要包含测试用例管理、测试执行控制、测试报表及测试日志的生成,整体测试框架要轻量易用。
3.2 概要设计
概要设计包括了四个大的模块:公共库模块(可复用函数、日志管理、报表管理以及发送邮件管理)、用例仓库(具体用例的管理)、页面管理(单独对Web页面进行抽象,封装页面元素和操作方法)以及执行模块。
概要设计类图:
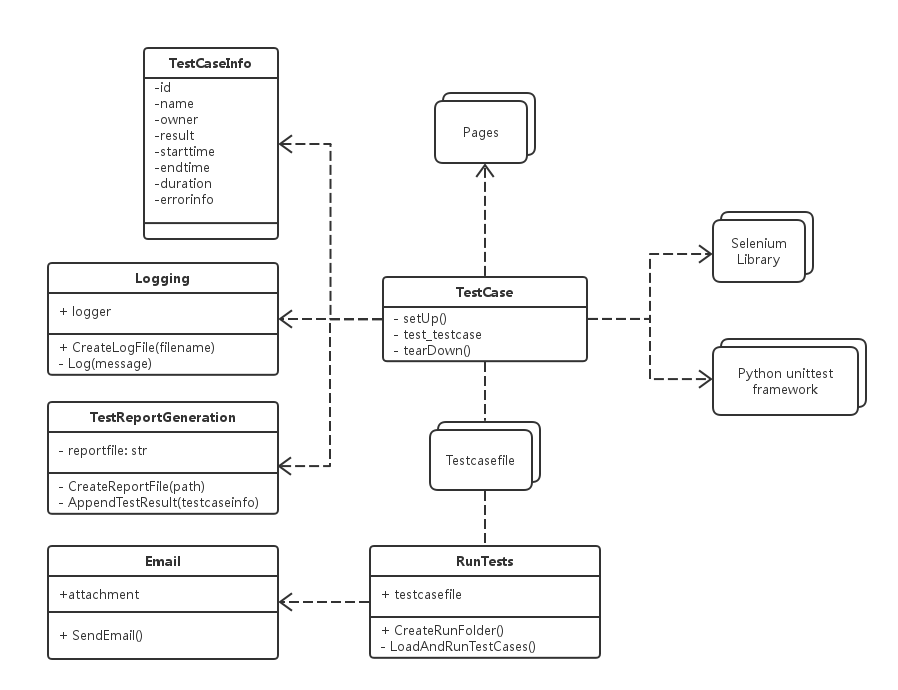
3.3 详细设计与实现
3.3.1 页面管理
测试Web对象是一个典型的单页面应用,因此采用页面模式(page pattern)来进行组织:
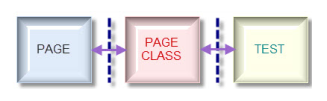
页面模式是页面与测试用例之间的桥梁,它将每个页面抽象成一个单独的页面类,为测试用例提供页面元素的定位和操作。
页面模式的类图如下:
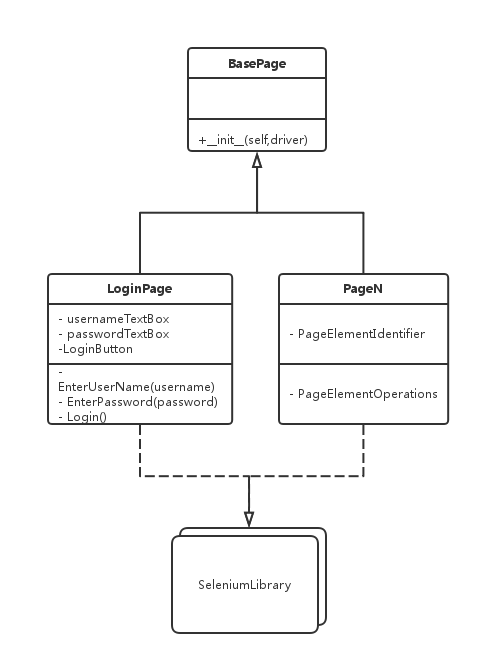
BasePage作为基类只包含一个driver成员变量,它用来标记Selenium中的WebDriver,以便在BasePage的派生类中定位页面元素。LoginPage和PageN等作为派生类,可以提供相应页面元素的定位和操作方法。比如测试对象的登录页面:
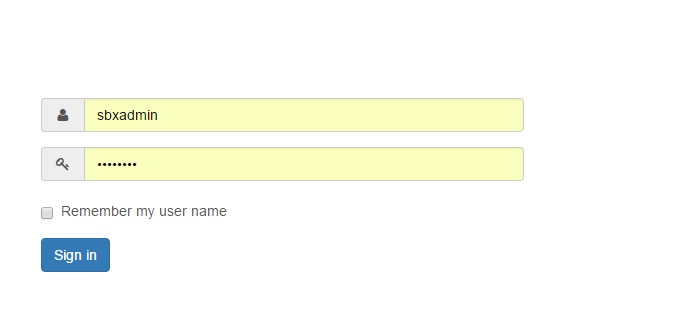
从页面可以看出,需要操作的页面元素分别为:Username,Password,remember my username checkbox和Sign in按钮,它们对应的操作为输入用户名和密码,点选checkbox和点击Sign In按钮,具体代码级别的实现如下:
页面基类BasePage.py:
class BasePage(object):
"""description of class"""
#webdriver instance
def __init__(self, driver):
self.driver = driver
LoginPage页面继承自BasePage,并进行Login Page的元素定位及操作实现。代码中定位了username和password,并且添加了设置用户名和密码的操作。
from BasePage import BasePage
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
class LoginPage(BasePage):
"""description of class"""
#page element identifier
usename = (By.ID,'username')
password = (By.ID, 'password')
dialogTitle = (By.XPATH,"//h4[@class=\"modal-title ng-binding\"]")
cancelButton = (By.XPATH,'//button[@class=\"btn btn-warning ng-binding\"][@ng-click=\"cancel()\"]')
okButton = (By.XPATH,'//button[@class=\"btn btn-primary ng-binding\"][@ng-click=\"ok()\"]')
#Get username textbox and input username
def set_username(self,username):
name = self.driver.find_element(*LoginPage.usename)
name.send_keys(username)
#Get password textbox and input password, then hit return
def set_password(self, password):
pwd = self.driver.find_element(*LoginPage.password)
pwd.send_keys(password + Keys.RETURN)
#Get pop up dialog title
def get_DiaglogTitle(self):
digTitle = self.driver.find_element(*LoginPage.dialogTitle)
return digTitle.text
#Get "cancel" button and then click
def click_cancel(self):
cancelbtn = self.driver.find_element(*LoginPage.cancelButton)
cancelbtn.click()
#click Sign in
def click_SignIn(self):
okbtn = self.driver.find_element(*LoginPage.okButton)
okbtn.click()
采用页面模式来管理页面和测试用例有很多好处,主要体现在:
每个页面都有单独的类来封装页面元素和操作,让页面操作更加具体化,而不是相对独立的。
比如未使用页面模式,测试用例的输入用户名和密码的代码:
#enter username and password
driver.find_element_by_id("username").clear()
driver.find_element_by_id("username").send_keys("sbxadmin")
driver.find_element_by_id("password").clear()
driver.find_element_by_id("password").send_keys("password"+Keys.RETURN)
使用页面模式之后,输入用户名和密码的代码:
#Step2: Open Login page
login_page = BasePage.LoginPage(self.driver)
#Step3: Enter username
login_page.set_username("username")
#Step4: Enter password
login_page.set_password("password")
通过对比我们不难发现,未使用页面模式的代码组织比较混乱,步骤多,可读性非常差,不难想象,一个通篇都是find_element_by_id或者send_Keys的测试用例到底有多糟糕!而使用了页面模式之后,在哪个页面做什么操作都非常清晰,非常接近测试用例的步骤,易读性非常好。
由于页面操作都被封装在了页面类中,所以页面方法和容易调用,可复用性非常好。而未使用页面模式的用例只能每次都实现一遍。
由于测试目标页面的多变性,页面元素的定位经常需要改变,利用了页面模式后,只需要修改一遍其页面类中的定位就可以对所用用到该元素的测试用例生效;而在未使用该模式的情况下,必须修改每一个用到该元素的测试用例,非常容易遗漏,工作量也非常大。
综合以上页面模式的各种优点,我们在以后的web自动化中可以多使用该模式来组织页面。
3.3.2 公共库模块
公共库模块是为创建测试用例服务的,它主要包括常量、公共函数、日志管理、报表管理以及发送邮件管理等。
公共库模块涉及到的功能一般多而杂,在设计的时候只要遵循高内聚低耦合就可以了。比如常量、变量和一些公共函数可以放在同一个文件中Common.py:
from datetime import datetime def driverPath(): return r'C:\Users\xua\Downloads\chromedriver_win32\chromedriver.exe' def baseUrl(): return "https://xxx.xxx.xxx.xxx:9000" #change time to str def getCurrentTime(): format = "%a %b %d %H:%M:%S %Y" return datetime.now().strftime(format) # Get time diff def timeDiff(starttime,endtime): format = "%a %b %d %H:%M:%S %Y" return datetime.strptime(endtime,format) - datetime.strptime(starttime,format)
测试用例信息类用来标识测试用例,并且包括执行用例执行结果信息,主要包括以下字段:
class TestCaseInfo(object):
"""description of class"""
def __init__(self, id="",name="",owner="",result="Failed",starttime="",endtime="",secondsDuration="",errorinfo=""):
self.id = id
self.name = name
self.owner = owner
self.result = result
self.starttime = starttime
self.endtime = endtime
self.secondsDuration = secondsDuration
self.errorinfo = errorinfo
测试用例信息需要在每个测试用例中实例化,以便对测试用例进行标记,并最终体现在测试报告中。
日志主要用来记录测试用例执行步骤及产生的错误信息,不同的信息有不同的日志级别,比如Information,Warning,Critical和Debug。由于每个测试用例产生的日志条目比较少,所以在测试框架中只利用了最高级别的日志打印,即Debug级别,该级别也会将其他所有的日志级别的信息同样打印出来。在具体的实现中引用了Python标准库中的logging类库,以便更方便的控制日志输出:
import logging
import ResultFolder
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def CreateLoggerFile(filename):
try:
fulllogname = ResultFolder.GetRunDirectory()+"\\"+filename+".log"
fh = logging.FileHandler(fulllogname)
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s [line:%(lineno)d] %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh)
except Exception as err:
logger.debug("Error when creating log file, error message: {}".format(str(err)))
def Log(message):
logger.debug(message)
报表管理及发送邮件模块实现了报表(html格式)的生成及自动发送邮件的功能。报表和邮件依附于当前测试的执行,每次执行都会独立的触发报表生成和邮件发送。该模块主要运用了Python中的lxml、smtplib和email库。
3.3.3 用例仓库
用例仓库主要用来组织自动化测试用例。每条测试用例都被抽象成一个独立的类,并且均继承自unittest.TestCase类。 Python中的unittest库提供了丰富的测试框架支持,包括测试用例的setUp和tearDown方法,在实现用例的过程中可以重写。依托页面管理和公共库模块实现的页面方法和公共函数,每一个测试用例脚本的书写都会非常清晰简洁,一个简单的Floor Manager Lite的登录用例如下:
class Test_TC_Login(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(cc.driverPath())
self.base_url = cc.baseUrl()
self.testCaseInfo = TestCaseInfo(id=1,name="Test case name",owner='xua')
self.testResult = TestReport()
LogUtility.CreateLoggerFile("Test_TC_Login")
def test_A(self):
try:
self.testCaseInfo.starttime = cc.getCurrentTime()
#Step1: open base site
LogUtility.Log("Open Base site"+self.base_url)
self.driver.get(self.base_url)
#Step2: Open Login page
login_page = LoginPage(self.driver)
#Step3: Enter username & password
LogUtility.Log("Login web using username")
login_page.set_username("username")
login_page.set_password("password")
time.sleep(2)
#Checkpoint1: Check popup dialog title
LogUtility.Log("Check whether sign in dialog exists or not")
self.assertEqual(login_page.get_DiaglogTitle(),"Sign in")
#time.sleep(3)
#Step4: Cancel dialog
login_page.click_cancel()
self.testCaseInfo.result = "Pass"
except Exception as err:
self.testCaseInfo.errorinfo = str(err)
LogUtility.Log(("Got error: "+str(err)))
finally:
self.testCaseInfo.endtime = cc.getCurrentTime()
self.testCaseInfo.secondsDuration = cc.timeDiff(self.testCaseInfo.starttime,self.testCaseInfo.endtime)
def tearDown(self):
self.driver.close()
self.testResult.WriteHTML(self.testCaseInfo)
if __name__ == '__main__':
unittest.main()
从这个测试用例中,我们可以看到
1.Setup中定义了执行测试用例前的一些实例化工作
2.tearDown对执行完测试做了清理和写日志文件工作
3.测试步骤、测试数据和测试检查点非常清晰,易修改(比如用户名密码)
4.日志级别仅有Debug,所以写日志仅需用同一Log方法
3.3.4 用例执行模块(控制器)
执行模块主要用来控制测试用例脚本的批量执行,形成一个测试集。用例的执行引用了Python标准库中的subprocess来执行nosetests的shell命令,从而执行给定测试用例集中的用例。测试用例集是一个简单的纯文本文件,实现过程中利用了.txt文件testcases.txt:
Test_Login_pass.py Test_Login_Fail.py #Test_MainPage_CheckSecurityTableInfo.py Test_MainPage_EditSecurityInfo.py
用例前没有“#“标记的测试用例脚本会被执行,而有”#“标记的则会被忽略,这样可以很方便的控制测试集的执行,当然也可以创建不同的文件来执行不同的测试集。
具体的调用代码如下:
def LoadAndRunTestCases(self):
try:
f = open(self.testcaselistfile)
testfiles = [test for test in f.readlines() if not test.startswith("#")]
f.close()
for item in testfiles:
subprocess.call("nosetests "+str(item).replace("\\n",""),shell = True)
except Exception as err:
LogUtility.logger.debug("Failed running test cases, error message: {}".format(str(err)))
finally:
EmailUtils.send_report()
3.4 执行结果
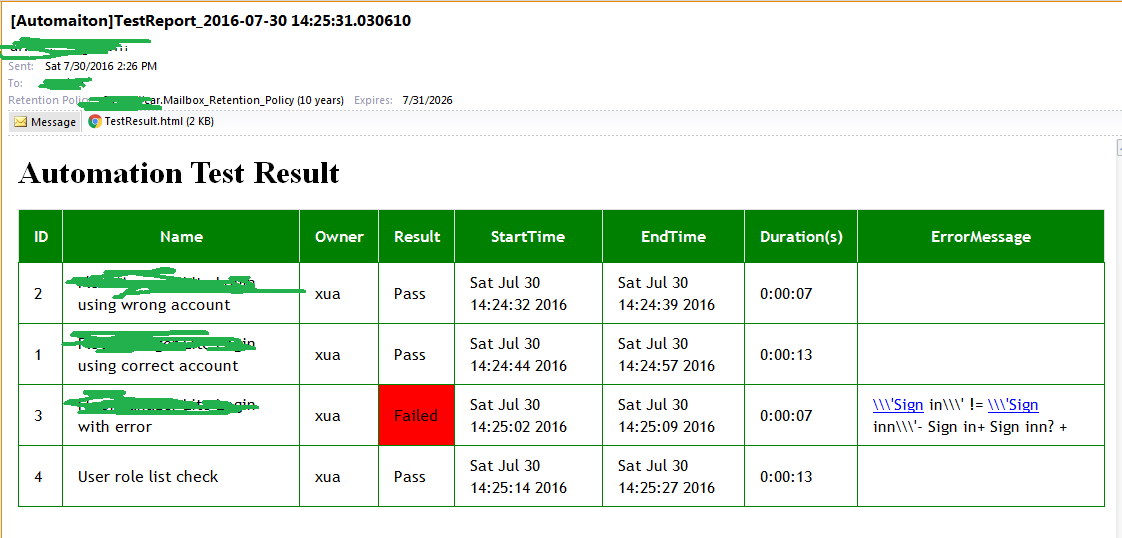
测试用例执行完毕后主要有两种输出:日志和测试报告。测试报告会html附件的形式通过邮件发出,例如:
4 需要改进的模块
对于现有实现的测试框架,已经可以满足web对象的自动化需求,但还是有些可以改进提高的地方,比如:
针对部分测试用例是否可以尝试数据驱动添加屏幕截图功能封装selenium中By库中的函数,以便更高效的定位页面元素等结合业界优秀的自动化框架和实践持续改进
5 总结
基于selenium实现的web自动化框架不仅轻量级而且灵活,可以快速的开发自动化测试用例。结合本篇中的框架设计以及一些好的实践,希望对大家以后的web自动化框架的设计和实现有所帮助。
源代码:https://github.com/AlvinXuCH/WebAutomaiton
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





