本文实例讲述了Python机器学习k-近邻算法。分享给大家供大家参考,具体如下:
存在一份训练样本集,并且每个样本都有属于自己的标签,即我们知道每个样本集中所属于的类别。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后提取样本集中与之最相近的k个样本。观察并统计这k个样本的标签,选择数量最大的标签作为这个新数据的标签。
用以下这幅图可以很好的解释kNN算法:
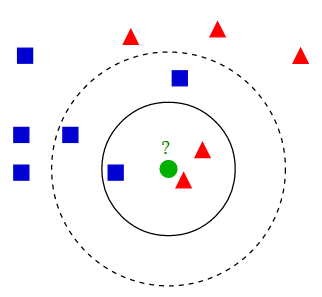
不同形状的点,为不同标签的点。其中绿色点为未知标签的数据点。现在要对绿色点进行预测。由图不难得出:
伪代码
对未知属性的数据集中的每个点执行以下操作
1. 计算已知类型类别数据集中的点与当前点之间的距离
2. 按照距离递增次序排序
3. 选取与当前点距离最小的k个点
4. 确定前k个点所在类别的出现频率
5. 返回前k个点出现频率最高的类别作为当前点的预测分类
欧式距离(计算两点之间的距离公式)
计算点x与点y之间欧式距离
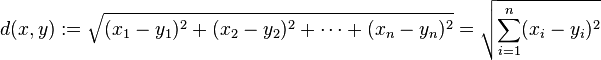
python代码实现
# -*- coding:utf-8 -*-
#! python2
import numpy as np
import operator
# 训练集
data_set = np.array([[1., 1.1],
[1.0, 1.0],
[0., 0.],
[0, 0.1]])
labels = ['A', 'A', 'B', 'B']
def classify_knn(in_vector, training_data, training_label, k):
"""
:param in_vector: 待分类向量
:param training_data: 训练集向量
:param training_label: 训练集标签
:param k: 选择最近邻居的数目
:return: 分类器对 in_vector 分类的类别
"""
data_size = training_data.shape[0] # .shape[0] 返回二维数组的行数
diff_mat = np.tile(in_vector, (data_size, 1)) - data_set # np.tile(array, (3, 2)) 对 array 进行 3×2 扩展为二维数组
sq_diff_mat = diff_mat ** 2
sq_distances = sq_diff_mat.sum(axis=1) # .sum(axis=1) 矩阵以列求和
# distances = sq_distances ** 0.5 # 主要是通过比较求最近点,所以没有必要求平方根
distances_sorted_index = sq_distances.argsort() # .argsort() 对array进行排序 返回排序后对应的索引
class_count_dict = {} # 用于统计类别的个数
for i in range(k):
label = training_label[distances_sorted_index[i]]
try:
class_count_dict[label] += 1
except KeyError:
class_count_dict[label] = 1
class_count_dict = sorted(class_count_dict.iteritems(), key=operator.itemgetter(1), reverse=True) # 根据字典的value值对字典进行逆序排序
return class_count_dict[0][0]
if __name__ == '__main__':
vector = [0, 0] # 待分类数据集
print classify_knn(in_vector=vector, training_data=data_set, training_label=labels, k=3)
运行结果:B
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





