人脸检测中的AdaBoost算法,供大家参考,具体内容如下
第一章:引言
2017.7.31。英国测试人脸识别技术,不需要排队购票就能刷脸进站。据BBC新闻报道,这项英国政府铁路安全标准委员会资助的新技术,由布里斯托机器人实验室(Bristol Robotics Laboratory) 负责开发。这个报道可能意味着我们将来的生活方式。虽然人脸识别技术已经研究了很多年了,比较成熟了,但是还远远不够,我们以后的目标是通过识别面部表情来获得人类心理想法。 长期以来,计算机就好像一个盲人,需要被动地接受由键盘、文件输入的信息,而不能主动从这个世界获取信息并自主处理。人们为了让计算机看到这个世界并主动从这个世界寻找信息,发展了机器视觉;为了让计算机自主处理和判断所得到的信息,发展了人工智能科学。人们梦想,终有一天,人机之间的交流可以像人与人之间的交流一样畅通和友好。 而这些技术实现的基础是在人脸检测上实现的,下面是我通过学习基于 AdaBoost 算法的人脸检测,赵楠的论文的学习心得。
第二章:关于Adaptive Boosting
AdaBoost 全称为Adaptive Boosting。Adaptively,即适应地,该方法根据弱学习的结果反馈适应地调整假设的错误率,所以Adaboost不需要预先知道假设的错误率下限。Boosting意思为提升、加强,现在一般指将弱学习提升为强学习的一类算法。实质上,AdaBoost算法是通过机器学习,将弱学习提升为强学习的一类算法的最典型代表。
第三章:AdaBoost算法检测人脸的过程
先上一张完整的流程图,下面我将对着这张图作我的学习分享:

1.术语名词解析:
弱学习,强学习:随机猜测一个是或否的问题,将会有50%的正确率。如果一个假设能够稍微地提高猜测正确的概率,那么这个假 设就是弱学习算法,得到这个算法的过程称为弱学习。可以使用半自动化的方法为好几个任务构造弱学习算法,构造过程需要数量巨大的假设集合,这个假设集合是基于某些简单规则的组合和对样本集的性能评估而生成的。如果一个假设能够显著地提高猜测正确的概率,那么这个假设就称为强学习。特征模版:我们将使用简单矩形组合作为我们的特征模板。这类特征模板都是由两个或多个全等的矩形相邻组合而成,特征模板内有白色和黑色两种矩形(定义左上角的为白色,然后依次交错),并将此特征模板的特征值定义为白色矩形像素和减去黑色矩形像素和。最简单的 5 个特征模板:
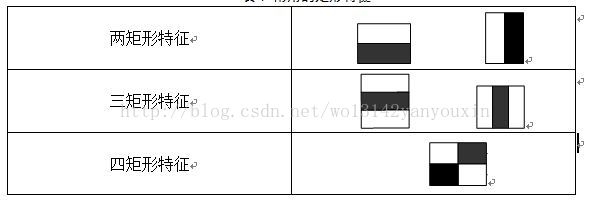
下面列出了,在不同子窗口大小内,特征的总数量:

积分图:主要是为了利用积分图计算矩形特征值,提高程序运行效率。下面给出非常形象的积分图的来计算矩形特征值:
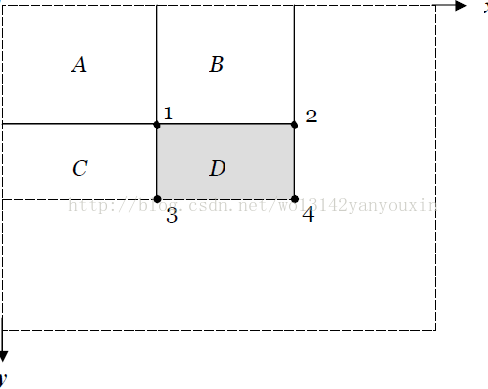
区域 D 的像素和可以用积分图计算为: K1+K4 - (K2+K3)
K1=区域A 的像素值
K2=区域A 的像素值+区域B 的像素值
K3=区域A 的像素值+区域C 的像素值
K4 =区域A 的像素值+区域B 的像素值+区域C 的像素值+区域D 的像素值
2.算法基本描述
对照上面的流程图:A给定一系列训练样本,B初始化权重,C归一化权重,都挺好理解的。我现在需要着重说的是接下来的步骤,即如何选取,训练弱分类器:
现在我们假设我们的计算机读取一张图片进来,在这张图片上遍历所有的特征,(例如20X20像素的图片,一共有78460个特征),当遍历到x个特征时,计算该特征在所有的训练样本中(人脸和非人脸图)的特征值。并且将这些特征值排序,通过扫描一遍排好序的特征值,可以为这个特征确定一个最优的阈值,从而训练成一个弱分类器。那么为什么扫描一遍就可以得出最优阈值?因为在扫描到每一个特征值时,当选取当前元素的特征值和它前面的一个特征值 之间的数作为阈值时,计算这个阈值所带来的分类误差为
e = min( S 1+ (T 2- S 2 ), S2 + (T 1- S 1 ))
其中:
全部人脸样本的权重的和T 1
全部非人脸样本的权重的和T 2
在此元素之前的人脸样本的权重的和S 1
在此元素之前的非人脸样本的权重的和S 2
将最小误差记录下来,选取该最小误差的特征值,选取当前元素的特征值和它前面的一个特征值 之间的数作为阈值,那么x特征的最小误差的弱分类器将出来了!以此类推,当遍历了所以的特征了,就在这些弱分类器中找到误差最小的分类器,就是最佳弱分类器。
接下来,就进入到调整最佳弱分类器的权重了。设置一个循环,用刚刚得到的最佳弱分类器去分类所有的训练样本,按照最上面的流程图中的调整权重的部分来调整权重。
以上的步骤就是一个完整的adaboost算法的训练过程!
最后,实验结果表明,当T=200 时,构成的强分类器可以获得很好的检测效果。经过 200次迭代后,获得了 200个最佳弱分类器 ,可以按照下面的方式组合成一个强分类器:
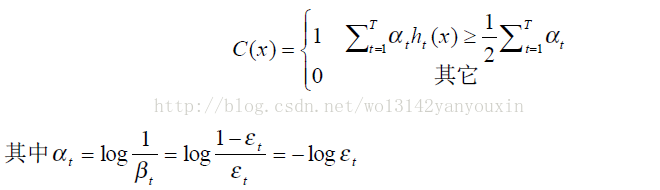
那么,这个强分类器对待一幅待检测图像时,相当于让所有弱分类器投票,再对投票结果按照弱分类器的错误率加权求和,将投票加权求和的结果与平均投票结果比较得出最终的结果。
第4章、个人总结
前前后后将近花了3天时间来学习adaboost算法的人脸识别。在网上找了很多的资料,发现大部分关于每一个特征的弱分类器和所有图像的最佳弱分类器的概念含糊不清,以及怎么用编程的思想来解读这个算法的意识不明确,具体来说,只考虑算法的过程,而不考虑怎么用编程来实现这些过程。这也是我写这个博客的主要目的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





