and操作:
隐式and操作:
db.getCollection("the_table").find({"age":{"$gt":20},"sex":"男"}) //对age与sex这两个字段的查询条件需要同时满足
显式and操作:
db.getCollection("the_table").find({"$and":[{"age":{"$gte":20}},{"address":"里世界"}]})
显式、隐式混用:
db.getCollection("the_table").find({
"id":{"$lt": 10},
"$and": [{"age": {"$gt": 20}}, {"sex": "男"}]
})
不能写成隐式and操作的例子:
db.getCollection("the_table").find({
"$and": [
{"$or": [{"age": {"$gt": 28}}, {"salary": {"$gt": 9900}}]},
{"$or": [{"sex": "男"}, {"id": {"$lt": 20}}]}
]
})
or操作:
年龄大于28,或工资大于9900的:
db.getCollection("the_table").find({
"$or": [{"age": {"$gt": 28}},{"salary":{"$gt": 9900}}]
})
(注意:mongodb在执行or操作时会遵循一个"短路原则":只要前面的条件满足了,那后面的条件直接跳过。如果age大于28 ,那就不需要去检查salary的值是多少。只有在age不满足查询条件时,才会去检查salary的值)
OR操作一定是显式的,不存在隐式的OR操作
而这里去可以把or两边的都显示出来:
> db.getCollection("the_table").find()
......
{ "_id" : ObjectId("5d10400adc4728bc5f52f3ca"), "username" : "张三" }
{ "_id" : ObjectId("5d104011dc4728bc5f52f3cb"), "username" : "李四" }
> db.getCollection("the_table").find({"$or":[{"username":"张三"},{"username":"李四"}]})
{ "_id" : ObjectId("5d10400adc4728bc5f52f3ca"), "username" : "张三" }
{ "_id" : ObjectId("5d104011dc4728bc5f52f3cb"), "username" : "李四" }
>
嵌入式文档的查询:

嵌入字段只是定位的时候多了一步。除此之外,嵌入字段和普通字段没有区别。
查询所有followed大于10的数据:
db.getCollection("the_table").find({"user.followed": {"$gt": 10}})
如需要在返回的查询结果中只显示嵌入式文档中的部分内容,也可以使用点号来实现。例如只返回"name"和"user_id"这两个字段,查询语句:
db.getCollection("the_table").find(
{"user.followed": {"$gt": 10}},
{"_id": 0, "user.name": 1, "user.user_id": 1}
)
包含与不包含:
查出所有size包含M的数据:
db.getCollection("the_table").find({"size": "M"})

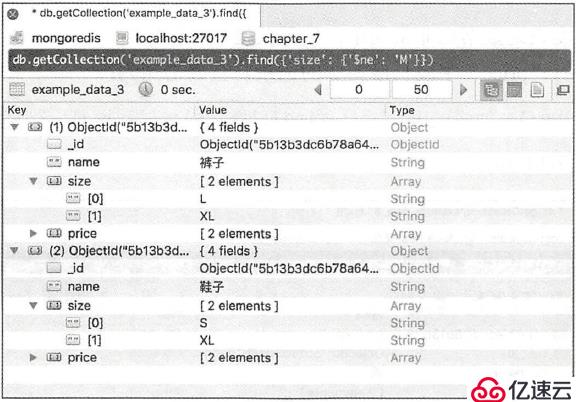
查出所有size不包含M的数据:
db.getCollection("the_table").find({"size": {"$ne": "M"}})
数组中有元素在另一个范围空间内:
db.getCollection("the_table").find({"price": {"$lt": 300, "$gt": 200}}
数组应用:
根据数组长度查询数据:
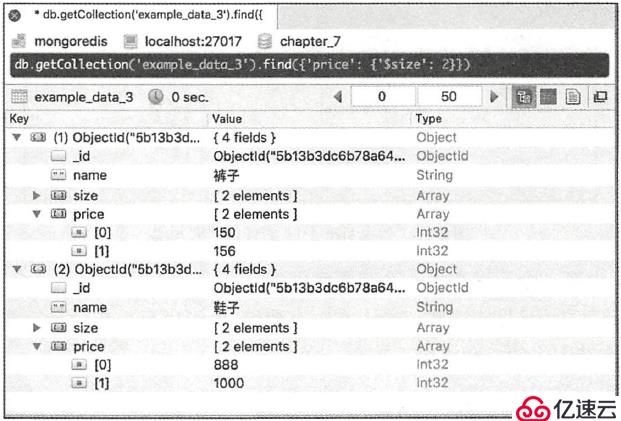
从数据集the_table中查询所有price长度为2的记录:
db.getCollection("the_table").find({"price": {"$size": 2}})
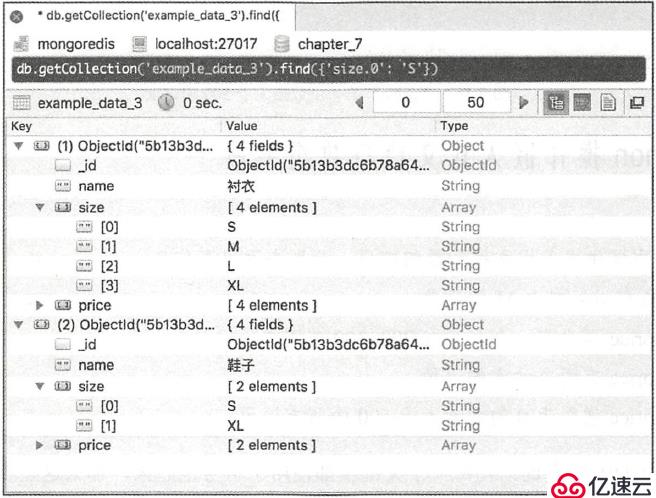
根据索引查询数据(索引是从0 开始的):
查询所有“ size ”的第1个(索引为0)数据为“ S ”的记录,查询语句为:
db.getCollection("the_table").find({"size.0": "S"})
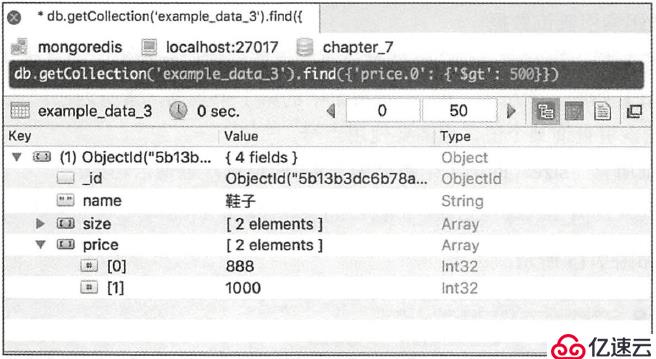
使用索引也可以比较大小。例如,查询“price ”第1 个数据大于500 的所有记录:
db.getCollection("the_table").find({"price.0": {"$gt": 500}})
高级更新:
最好用$push或$addToSet,这两个命令都是往数组中添加数据,但$addToSet是唯一的,阻止了重复数据
db.getCollection("the_table").update(
{"favorites.movies": "Cassablanca"},
{"$addToSet": {"favorites.movies": "the maltese falcon"}},
false,
true
)
第一个参数:匹配电影列表中包含Cassablanca的用户
第二个参数:使用$addToSet添加the maltese falcon到列表中
第三个参数:false,控制是否允许upsert。这个命令告诉更新操作,当一个文档不存在的时候是否插入它,这取决于更新操作是操作符更新还是替换更新
第四个参数:true,表示是否更新多个更新。默认情况下,mongodb更新只针对第一个匹配文档。如果想更新所有匹配文档,就必须显示指定这个参数。
删除数据:
db.user.remove({"favorites.cities":"Cheyenne"})
注意:remove()操作不会删除集合,它只会删除集合中的某个文档。我们可以把它和sql中的delete命令类比。如果要删除集合以及附带的索引数据,可以用drop()方法:
db.user.drop()
MongoDB的聚合查询:
使用聚合功能,可以直接让MongoDB来处理数据。聚合功能可以把数据像放入传送带一样,先把原始数据按照一定的规则进行筛选处理,然后通过多个不同的数据处理阶段来处理数据,最终输出一个汇总的结果。
聚合操作的命令为"aggregate",基本格式为:collection.aggregate([阶段1,阶段2,阶段3, ……,阶段N])
聚合操作可以有0 个、l 个或者多个阶段。如果有0 个阶段,则查询命令写为:collection.aggregate()。那么它的作用和collection.find() 一样
如果聚合有至少一个阶段,那么每一个阶段都是一个字典。不同的阶段负责不同的事情,每一个阶段有一个关键字。有专门负责筛选数据的阶段“ $match ’3 ,有专门负责宇段相关的阶段“ $pr句ect”,有专门负责数据分组的阶段“$group"等。聚合操作有几十个不同的阶段关键字
一般情况下,并非所有的数据都需要被处理,因此大多数时候聚合的第一个阶段是数据筛选。就像find()一样,把某些满足条件的数据选出来以便后面做进一步处理。数据筛选的关键字为$match,它的用法为:collection.aggregate([{"$match":{和find 完全一样的查询表达式}}])
从the_table数据集中,查询age大于等于27,且sex为“女”的所有记录:
db.getCollection("the_table").aggregate([
{"$match": {"age": {"$gte": 27}, "sex": "女"}}
])
从查询结果来看,这一条聚合查询语句的作用完全等同于:
db.getCollection("the_table").find({"age": {"$gte": 27}, "sex": "女"})
这两种写法,核心查询语句{"age": {"$gte": 27} , "sex":"女"}完全一样。聚合查询操作中的{"$match":{和find完全一样的查询表达式}}","$match"作为一个字典的Key,字典的Value和"find()"第1个参数完全相同。"find()"第1个参数能怎么写,这里就能怎么写。
例如,查询所有age大于28或sex为男的记录,聚合查询可以写为:
db.getCollection("the_table").aggregate([
{"$match": {"$or": [{"age": {"$gt": 28}}, {"sex": "男"}]}}
])
从效果上看,使用聚合查询与直接使用“自nd()” 效果完全相同,而使用聚合查询还要多敲几次键盘,那它的好处在哪里呢?聚合操作的好处在于“ 组合” 。接下来会讲到更多的聚合关键字,把这些关键字组合起来才能体现出聚合操作的强大。
筛选与修改字段:
$project来实现一个己经有的功能一一只返回部分字段(这里的字段过滤语句与find()第2个参数完全相同)
db.getCollection("the_table").aggregate([
{"$project": {"_id":0, "sex":1, "age":1}}
])
先筛选记录,再过滤字段:
db.getCollection("the_table").aggregate([
{"$match": {"age": {"$gt": 28}}}
{"$project": {"_id":0, "sex":1, "age":1}},
])
添加新字段:
db.getCollection("the_table").aggregate([
{"$project": {"_id":0, "sex":1, "age":1, "newfield": "hello world"}},
{"$match": {"age": {"$gt": 28}}}
])
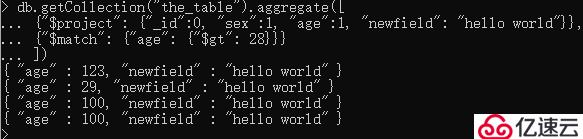
(newfield是原来没有的字段)
复制现有字段:
db.getCollection("the_table").aggregate([
{"$match": {"age": {"$gt": 28}}},
{"$project": {"_id":0, "sex":1, "age":1, "newfield": "$age"}}
])
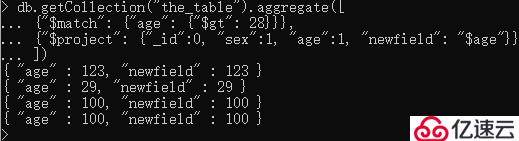
修改现有字段的数据:
db.getCollection("the_table").aggregate([
{"$match": {"age": {"$gt": 28}}},
{"$project": {"_id":0, "sex":1, "age":1, "newfield": "this is new field"}}
])
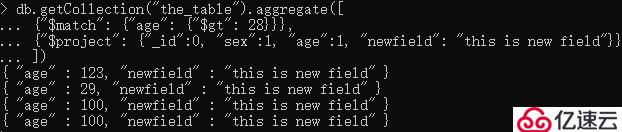
注意:这并不会改变数据库里的数据,只是改变输出的数据
(数据并没有变化)
抽取嵌套字段:
上面的:添加新字段、复制现有字段、修改现有字段的数据等,看起来并没有卵用,而下面的例子就有用了:
如果用find(),想返回user_id和name,则查询语句为:
db.getCollection("the_table").find({},{"user.name":1, "user.user_id":1})
返回结果为:
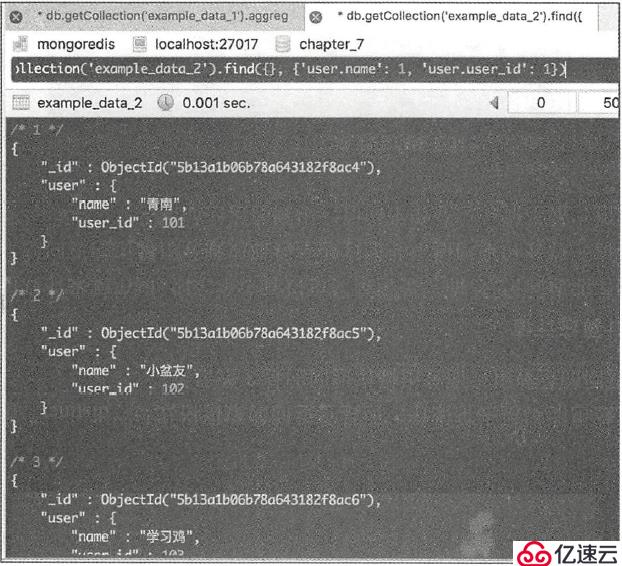
(显然,嵌套字段处理起来并不方便)
现在用$project将嵌套字段中的内容抽取:
db.getCollection("the_table").aggregate([
{"$project": {"name":"$user.name", "user_id":"$user.user_id"}}
])
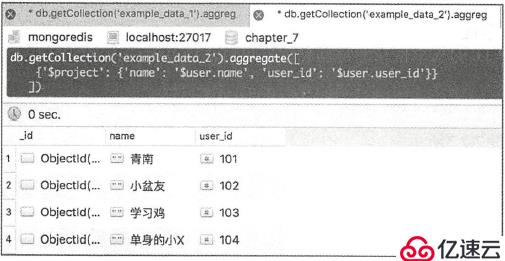
处理字段特殊值:
• 如果想添加一个字段,但是这个字段的值就是数字“ 1 ”会怎么样?
• 如果添加一个字段,这个字段的值就是一个普通的字符串,但不巧正好以“$”开头,又会怎么样呢?
关键字:$literal
db.getCollection("the_table").aggregate([
{"$match": {"age": {"$gt": 28}}},
{"$project": {"_id":0, "id":1, "hello": {"$literal":"$normalstring"}, "abcd":{"$literal":1}}}
])

分组操作:
去重的格式:db.getCollection("the_table").aggregate([{"$group": {"_id": "$被去重的字段名"}}])
db.getCollection("the_table").aggregate([
{"$group": {"_id": "$name"}}
])
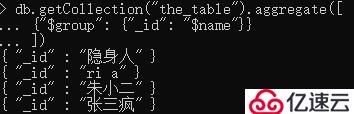
分组操作虽然也能实现去重操作,但是它返回的数据格式与distinct函数是不一样的。distinct函数返回的是数组,而分组操作返回的是几条记录
去重并统计:
db.getCollection("the_table").aggregate([
{"$group": {"_id": "$name","max_age":{"$max":"$age"},"min_age":{"$min":"$age"},"avg_age":{"$avg":"$age"},"sum_age":{"$sum":"$age"}}}
])

原则上,$sum和$avg的值对应的字段的值应该都是数字。如果强行使用值为非数字的字段,那么$sum会返回0, $avg会返回null。而字符串是可以比较大小的,所以,$max与$min可以正常应用到字符串型的字段
还可以使用$sum的值为数字1来统计多少条记录:
db.getCollection("the_table").aggregate([
{"$group": {"_id": "$name","doc_count":{"$sum":1},"max_age":{"$max":"$age"},"min_age":{"$min":"$age"},"avg_age":{"$avg":"$age"},"sum_age":{"$sum":"$age"}}}
])

分组/去重、最新一条数据:
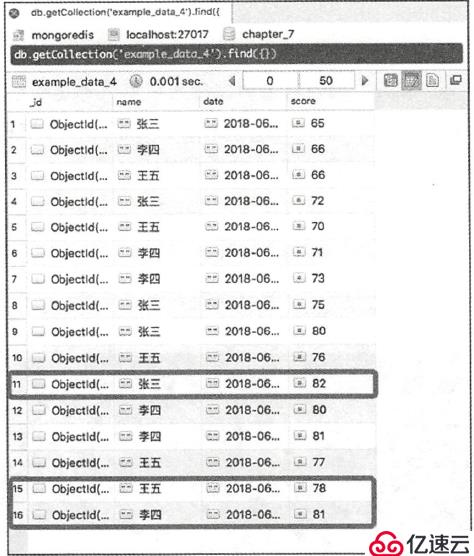
db.getCollection("the_table").aggregate([
{"$group": {"_id": "$name","age":{"$last":"$age"},"address":{"$last":"$address"}}}
])

可以取最新的数据,自然可以取最早的数据:
db.getCollection("the_table").aggregate([
{"$group": {"_id": "$name","age":{"$first":"$age"},"address":{"$first":"$address"}}}
])

拆分数组(用关键字:$unwind):
格式:collection.aggregate([{"$unwind":"$字段名"}])
db.getCollection("the_table").aggregate([
{"$unwind":"$size"}
])
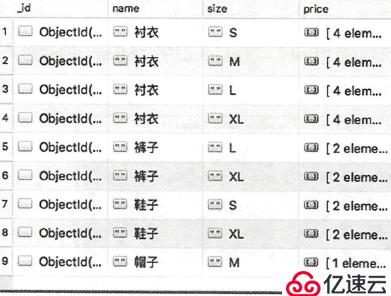
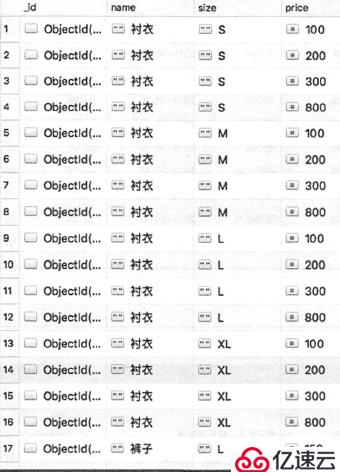
还可以把price数组也拆分:
db.getCollection("the_table").aggregate([
{"$unwind":"$size"},
{"$unwind":"$price"}
])
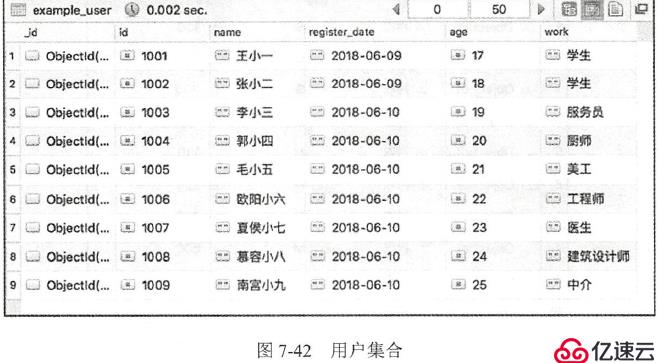
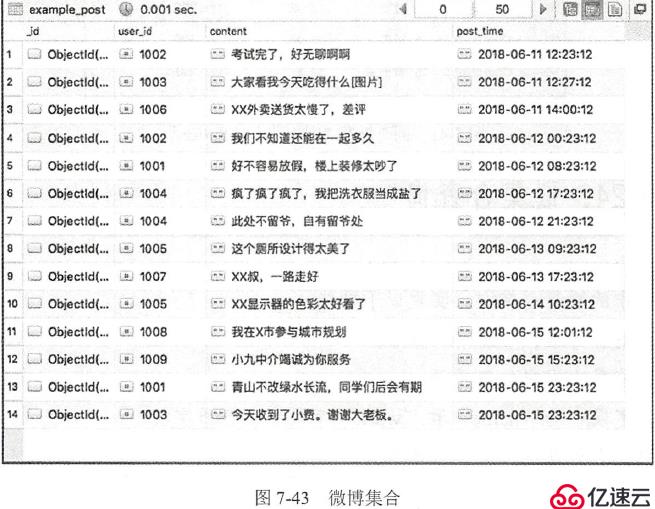
联集合查询:
主集合.aggregate([
{
"$lookup": {
"from": "被查集合名",
"localField": "主集合的字段",
"foreignField": "被查集合的字段",
"as": "保存查询结果的字段名"
}
}
])
其中的“主集合”与“被查集合”需要搞清楚。如果顺序搞反了, 则结果会不同。
例如, 现在需要在做博集合中查询用户信息, 那么主集合就是微博集合, 被查集合就是用户集合。于是查询语句可以写为以下:
db.getCollection("example_post").aggregate([
{"$lookup":{
"from": "example_user",
"localField": "user_id",
"foreignField": "id",
"as": "user_info"
}}
])
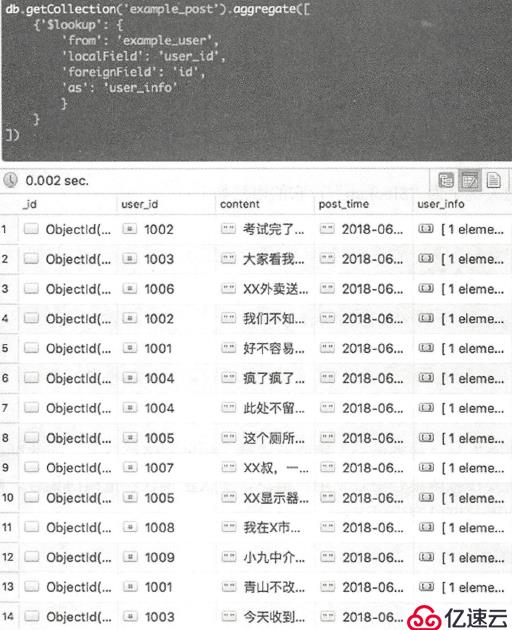
(这里user_info字段之所以会是一个数组,是因为被查询集合中可能有多条记录都满足条件,只有使用数组才能把它们都保存下来。由于用户集合每一个记录都是唯一的,所以这个数组只有一个元素)
联集合查询并美化结果:
db.getCollection("example_post").aggregate([
{"$lookup":{
"from": "example_user",
"localField": "user_id",
"foreignField": "id",
"as": "user_info"
}},
{"$unwind":"$user_info"}
])
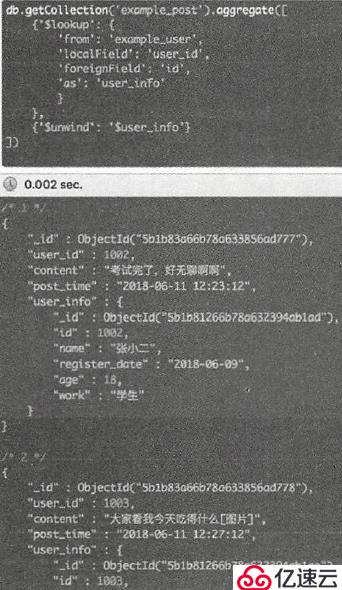
当然,还可以将联集合查询拆分结果返回特定内容:
db.getCollection("example_post").aggregate([
{"$lookup":{
"from": "example_user",
"localField": "user_id",
"foreignField": "id",
"as": "user_info"
}},
{"$unwind":"$user_info"},
{"$project":{
"content": 1,
"post_time": 1,
"name": "$user_info.name",
"work": "$user_info.work"
}}
])
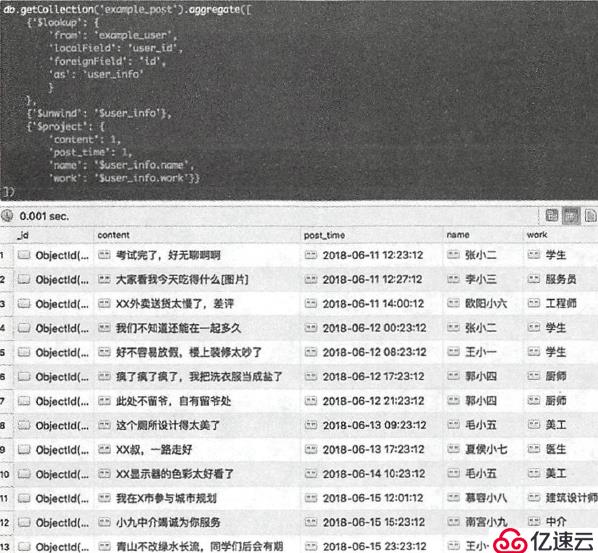
以用户为基准联集合查询:
db.getCollection("example_user").aggregate([
{"$lookup":{
"from": "example_post",
"localField": "id",
"foreignField": "user_id",
"as": "weibo_info"
}},
{"$unwind":"$weibo_info"},
{"$project":{
"name": 1,
"work": 1,
"content": "$weibo_info.name",
"post_time": "$weibo_info.work"
}}
])
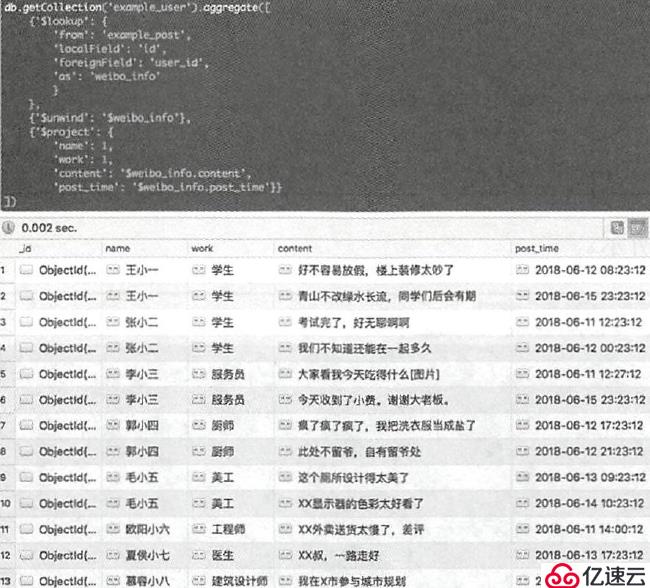
还可以指定只查某人的:
db.getCollection("example_user").aggregate([
{"$match": {"name": "张三疯"}},
{"$lookup":{
"from": "example_post",
"localField": "id",
"foreignField": "user_id",
"as": "weibo_info"
}},
{"$unwind":"$weibo_info"},
{"$project":{
"content": 1,
"post_time": 1,
"name": "$weibo_info.name",
"work": "$weibo_info.work"
}}
])
(从性能上讲,建议把$match放在最前面,这样可以充分用到mongodb的索引)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





