首先介绍一下Ceph安装部署的方法,Ceph社区提供了三种部署方法:
我们采用成熟、简单的ceph-deploy实现Ceph集群的部署,首先了解一下ceph-deploy的架构:
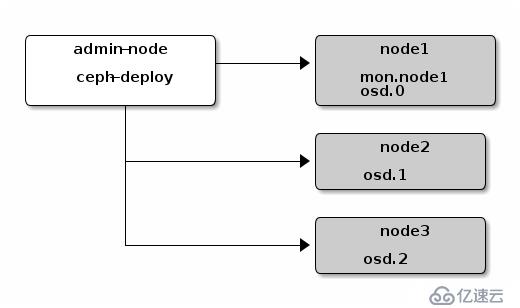
安装环境以三个节点的方式来完成Ceph集群的部署,如下是各个集群安装部署的信息:
| 节点名称 | 角色说明 | IP地址 | 备注说明 |
|---|---|---|---|
| node-1 | admin-node,monitor,OSD | 10.254.100.101 | 承担ceph-deploy安装部署admin-node角色<br>2. 充当Ceph Monitor节点<br>3. 充当Ceph OSD节点,包含一块50G磁盘 |
| node-2 | OSD | 10.254.100.102 | 充当Ceph OSD数据存储节点,包含一块50G磁盘 |
| node-3 | OSD | 10.254.100.103 | 充当Ceph OSD数据存储节点,包含一块50G磁盘 |
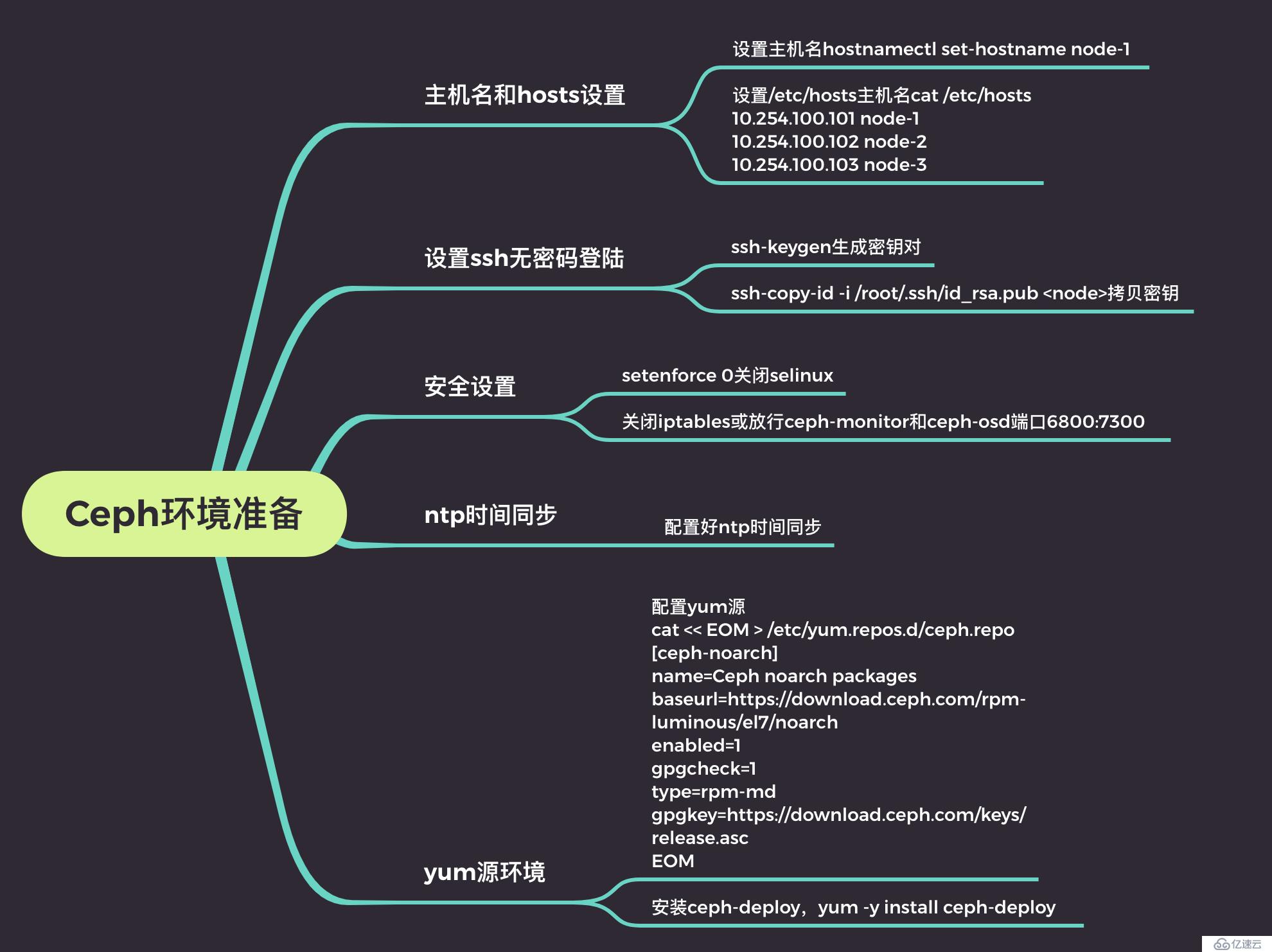
安装Ceph之前需要将环境提前部署好,部署内容参考上图内容,官方安装时推荐创建一个新的用户来实现安装部署,官方参考文档,本文直接以root的身份实现集群的安装。备注:以下操作除了ssh无密码登陆之外,其他操作均需要在所有节点上执行。
1、主机名设置,以node-1为例
[root@node-1 ~]# hostnamectl set-hostname node-1
[root@node-1 ~]# hostnamectl status
Static hostname: node-1
Icon name: computer-vm
Chassis: vm
Machine ID: 0ea734564f9a4e2881b866b82d679dfc
Boot ID: b0bc8b8c9cb541d2a582cdb9e9cf22aa
Virtualization: kvm
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-957.27.2.el7.x86_64
Architecture: x86-642、设置/etc/hosts文件,将node-1至node-3信息写入到/etc/hosts文件中
[root@node-1 ~]# cat /etc/hosts
10.254.100.101 node-1
10.254.100.102 node-2
10.254.100.103 node-33、设置ssh无密码登陆,需要需要在node-1上生成key,然后将公钥拷贝到其他节点(包括node-1节点),如下图
4、关闭Selinux默认已关闭
[root@node-1 ~]# setenforce 0
[root@node-1 ~]# getenforce 5、关闭iptables防火墙,或者放行对应的端口:Ceph monitor 6789/tcp,Ceph OSD 6800-7300/tcp
[root@node-1 ~]# systemctl stop iptables
[root@node-1 ~]# systemctl stop firewalld
[root@node-1 ~]# systemctl disable iptables
[root@node-1 ~]# systemctl disable firewalld6、配置好ntp时间同步,Ceph是分布式集群,对时间很敏感,如果时间不正确可能会导致集群奔溃,因此在Ceph集中中设置ntp同步非常关键,推荐使用内网的ntp服务器同步时间,腾讯云CVM默认会同步到内网的ntp时间同步,读者根据需要进行设定
[root@node-1 ~]# grep ^server /etc/ntp.conf
server ntpupdate.tencentyun.com iburst
[root@node-1 ~]#
[root@node-1 ~]# ntpq -pn
remote refid st t when poll reach delay offset jitter
==============================================================================
*169.254.0.2 183.3.239.152 4 u 238 1024 377 5.093 4.443 5.1457、设置Ceph安装yum源,选择安装版本为octopus
[root@node-1 ~]# cat << EOM > /etc/yum.repos.d/ceph.repo
> [ceph-noarch]
> name=Ceph noarch packages
> baseurl=https://download.ceph.com/rpm-mimic/el7/noarch
> enabled=1
> gpgcheck=1
> type=rpm-md
> gpgkey=https://download.ceph.com/keys/release.asc
> EOM
安装EPEL 仓库
[root@node-1 ~]# sudo yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm8、安装Ceph-deploy,对应版本为2.0.1,重要:默认epel源中ceph-deploy的版本是1.5,版本较老,会涉及到很多rpm依赖,安装问题,安装前检查好对应的版本,确保无误。
[root@node-1 ~]# yum install ceph-deploy -y
[root@node-1 ~]# ceph-deploy --version
2.0.1Ceph-deploy部署过程中会生成一些集群初始化配置文件和key,后续扩容的时候也需要使用到,因此,建议在admin-node上创建一个单独的目录,后续操作都进入到该目录中进行操作,以创建的ceph-admin-node为例。
1、创建一个Ceph cluster集群,可以指定cluster-network(集群内部通讯)和public-network(外部访问Ceph集群)
[root@node-1 ceph-admin ]# ceph-deploy new \
>--cluster-network 10.254.100.0/24 \
>--public-network 10.254.100.0/24 node-1 #创建集群
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy new --cluster-network 10.254.100.0/24 --public-network 10.254.100.0/24 node-1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] func : <function new at 0x7fefe8a292a8>
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fefe83a5b00>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] ssh_copykey : True
[ceph_deploy.cli][INFO ] mon : ['node-1']
[ceph_deploy.cli][INFO ] public_network : 10.254.100.0/24
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] cluster_network : 10.254.100.0/24
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] fsid : None
[ceph_deploy.new][DEBUG ] Creating new cluster named ceph
[ceph_deploy.new][INFO ] making sure passwordless SSH succeeds
[node-1][DEBUG ] connected to host: node-1
[node-1][DEBUG ] detect platform information from remote host
[node-1][DEBUG ] detect machine type
[node-1][DEBUG ] find the location of an executable
[node-1][INFO ] Running command: /usr/sbin/ip link show
[node-1][INFO ] Running command: /usr/sbin/ip addr show
[node-1][DEBUG ] IP addresses found: [u'172.17.0.1', u'10.244.0.1', u'10.244.0.0', u'10.254.100.101']
[ceph_deploy.new][DEBUG ] Resolving host node-1
[ceph_deploy.new][DEBUG ] Monitor node-1 at 10.254.100.101
[ceph_deploy.new][DEBUG ] Monitor initial members are ['node-1']
[ceph_deploy.new][DEBUG ] Monitor addrs are [u'10.254.100.101']
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...通过上面的输出可以看到,new初始化集群过程中会生成ssh key密钥,ceph.conf配置文件,ceph.mon.keyring认证管理密钥,配置cluster network和pubic network,此时查看目录下的文件可以看到如下内容:
[root@node-1 ceph-admin ]# ls -l
总用量 12
-rw-r--r-- 1 root root 265 3月 1 13:04 ceph.conf #配置文件
-rw-r--r-- 1 root root 3068 3月 1 13:04 ceph-deploy-ceph.log #部署日志文件
-rw------- 1 root root 73 3月 1 13:04 ceph.mon.keyring #monitor认证key
[root@node-1 ceph-admin-node]# cat ceph.conf
[global]
fsid = cfc3203b-6abb-4957-af1b-e9a2abdfe725
public_network = 10.254.100.0/24 #public网络和cluster网络
cluster_network = 10.254.100.0/24
mon_initial_members = node-1 #monitor的地址和主机名
mon_host = 10.254.100.101
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx2、安装Ceph部署相关的软件,常规通过yum进行安装,由于可能会安装错软件包,因此ceph-deploy提供了一个install的工具辅助软件包的安装,ceph-deploy install node-1 node-2 node-3
[root@node-1 ~]# ceph-deploy install node-1 node-2 node-33、初始化monitor节点,执行ceph-deploy mon create-initial做初始化
初始化完毕后会生成对应的keyring文件,用于ceph认证:
ceph.client.admin.keyringceph.bootstrap-mgr.keyringceph.bootstrap-osd.keyringceph.bootstrap-mds.keyringceph.bootstrap-rgw.keyringceph.bootstrap-rbd.keyringceph.bootstrap-rbd-mirror.keyring4、将认证密钥拷贝到其他节点,便于ceph命令行可以通过keyring和ceph集群进行交互,ceph-deploy admin node-1 node-2 node-3
此时,Ceph集群已经建立起来,包含一个monitor节点,通过ceph -s可以查看当前ceph集群的状态,由于此时并没有任何的OSD节点,因此无法往集群中写数据等操作,如下是ceph -s查看的输出结果
[root@node-1 ceph-admin]# ceph -s
cluster:
id: 760da58c-0041-4525-a8ac-1118106312de
health: HEALTH_OK
services:
mon: 1 daemons, quorum node-1
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 5、集群中目前还没有OSD节点,因此没法存储数据,接下来开始往集群中添加OSD节点,每个节点上都有一块50G的vdb磁盘,将其加入到集群中作为OSD节点,如ceph-deploy osd create node-1 --data /dev/vdb
如上已将node-1的vdb添加到ceph集群中,ceph -s可以看到当前有一个osd加入到集群中,执行相同的方法将node-2和node-3上的磁盘添加到集群中
执行完毕后,三个OSD均已加入到ceph集群中,通过ceph -s可以看到对应三个OSD节点
[root@node-1 ceph-admin]# ceph -s
cluster:
id: 760da58c-0041-4525-a8ac-1118106312de
health: HEALTH_WARN
no active mgr
services:
mon: 1 daemons, quorum node-1
mgr: no daemons active
osd: 3 osds: 3 up, 3 in #三个OSD,当前状态都是up和in状态
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 也可以通过ceph osd tree查看每隔节点上osd的情况和crush tree的情况
[root@node-1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.14369 root default
-3 0.04790 host node-1
0 hdd 0.04790 osd.0 up 1.00000 1.00000
-5 0.04790 host node-2
1 hdd 0.04790 osd.1 up 1.00000 1.00000
-7 0.04790 host node-3
2 hdd 0.04790 osd.2 up 1.00000 1.00000 6、此时Ceph的health状态为HEALTH_WARN告警状态,提示信息为“no active mgr”,因此需要部署一个mgr节点,manager节点在luminous之后的版本才可以部署(本环境部署的是M版本,因此可以支持),将mgr部署到node-1节点,执行ceph-deploy mgr create node-1
至此,Ceph集群已经部署完毕。通过ceph-deploy工具进行部署完成Ceph集群的自动化部署,后续添加monitor节点,osd节点,mgr节点也会很方便。
实战目标:Ceph集群创建资源池,创建RBD块,RBD块的使用
部署完Ceph集群之后,如何在Ceph集群中存储文件呢?ceph提供了三种接口供用户使用,分别是:
我们先以Ceph RBD的方式来介绍Ceph集群的使用,通过在Ceph集群中创建一个RBD块文件供用户进行使用,要使用Ceph,首先需要一个资源池pool,pool是Ceph中数据存储抽象的概念,其右多个pg(Placegroup)和pgp组成,创建的时候可以指定pg的数量,pg的大小一般为2^n次方,如下先创建一个pool
1、创建一个pool,其名字为happylau,包含128个PG/PGP,
[root@node-1 ~]# ceph osd pool create happylau 128 128
pool 'happylau' created可以查看pool的信息,如查看当前集群的pool列表——lspools,查看pg_num和pgp_num,副本数size大小
查看pool列表
[root@node-1 ~]# ceph osd lspools
1 happylau
查看pg和pgp数量
[root@node-1 ~]# ceph osd pool get happylau pg_num
pg_num: 128
[root@node-1 ~]# ceph osd pool get happylau pgp_num
pgp_num: 128
查看size大小,默认为三副本
[root@node-1 ~]# ceph osd pool get happylau size
size: 32、此时pool已经创建好,可以在pool中创建RBD块,通过rbd命令来实现RBD块的创建,如创建一个10G的块存储
[root@node-1 ~]# rbd create -p happylau --image ceph-rbd-demo.img --size 10G 如上创建了一个ceph-rbd-demo.img的RBD块文件,大小为10G,可以通过ls和info查看RBD镜像的列表和详情信息
查看RBD镜像列表
[root@node-1 ~]# rbd -p happylau ls
ceph-rbd-demo.img
查看RBD详情,可以看到镜像包含2560个objects,每个ojbect大小为4M,对象以rbd_data.10b96b8b4567开头
[root@node-1 ~]# rbd -p happylau info ceph-rbd-demo.img
rbd image 'ceph-rbd-demo.img':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
id: 10b96b8b4567
block_name_prefix: rbd_data.10b96b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Mon Mar 2 15:32:39 20203、RBD存储块已创建起来了,如何使用呢?如果已和虚拟化环境结合,创建好虚拟机然后在磁盘中写数据即可,但此时还未与虚拟化结合(结合难度也比较大,后续再专门讨论),rbd提供了一个map的工具,可以将一个RBD块映射到本地块进行使用,大大简化了使用过程,rbd map时候,exclusive-lock, object-map, fast-diff, deep-flatten的features不支持,因此需要先disable,否则会提示RBD image feature set mismatch报错信息
关闭默认的featrues
[root@node-1 ~]# rbd -p happylau --image ceph-rbd-demo.img feature disable deep-flatten
[root@node-1 ~]# rbd -p happylau --image ceph-rbd-demo.img feature disable fast-diff
[root@node-1 ~]# rbd -p happylau --image ceph-rbd-demo.img feature disable object-map
[root@node-1 ~]# rbd -p happylau --image ceph-rbd-demo.img feature disable exclusive-lock
查看校验featrue信息
[root@node-1 ~]# rbd -p happylau info ceph-rbd-demo.img
rbd image 'ceph-rbd-demo.img':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
id: 10b96b8b4567
block_name_prefix: rbd_data.10b96b8b4567
format: 2
features: layering
op_features:
flags:
create_timestamp: Mon Mar 2 15:32:39 2020
将RBD块map到本地,此时map后,可以看到RBD块设备映射到了本地的一个/dev/rbd0设备上
[root@node-1 ~]# rbd map -p happylau --image ceph-rbd-demo.img
/dev/rbd0
[root@node-1 ~]# ls -l /dev/rbd0
brw-rw---- 1 root disk 251, 0 3月 2 15:58 /dev/rbd04、RBD块设备已映射到本地的/dev/rbd0设备上,因此可以对设备进行格式化操作使用
通过device list可以查看到当前机器RBD块设备的映射情况
[root@node-1 ~]# ls -l /dev/rbd0
brw-rw---- 1 root disk 251, 0 3月 2 15:58 /dev/rbd0
该设备可以像本地的一个盘来使用,因此可以对其进行格式化操作
[root@node-1 ~]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=16, agsize=163840 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=2621440, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@node-1 ~]# blkid /dev/rbd0
/dev/rbd0: UUID="35f63145-0b62-416d-81f2-730c067652a8" TYPE="xfs"
挂载磁盘到系统中
[root@node-1 ~]# mkdir /mnt/ceph-rbd
[root@node-1 ~]# mount /dev/rbd0 /mnt/ceph-rbd/
[root@node-1 ~]# df -h /mnt/ceph-rbd/
文件系统 容量 已用 可用 已用% 挂载点
/dev/rbd0 10G 33M 10G 1% /mnt/ceph-rbd
[root@node-1 ~]# cd /mnt/ceph-rbd/
[root@node-1 ceph-rbd]# echo "testfile for ceph rbd" >rbd.log本文通过ceph-deploy完成一个1mon节点+1mgr节点+3个osd节点的集群,ceph-deploy安装简化了集群的部署,我在安装过程中遇到了不少报错(主要是rpm版本问题,尤其是ceph-deploy的包,EPEL默认的是1.5版本,需要用到ceph官网的2.0.1,否则会遇到各种各样的问题,1年未安装Ceph,变化很大,不得不感慨社区的发展速度)。
除此之外,介绍了Ceph中RBD的使用方式,资源池pool的创建,rbd镜像创建接口,rbd存储映射的使用,通过接口的使用,演示了Ceph中RBD块存储的使用,如和虚拟化对接,虚拟化产品会调用接口实现相同功能。章节中未介绍object storage对象存储的使用和cephfs文件存储的使用,由于相关组件未安装,后续章节中再做介绍。
另外,还介绍了Ceph另外当前集群只有一个monitor节点,存在单点故障,当node-1节点故障时,整个集群都会处于不可用状态,因此需要部署高可用集群,以避免集群存在单点故障,保障业务的高可用性,下个章节来介绍monitor节点的扩容。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





