小编给大家分享一下Python爬取《隐秘的角落》的弹幕,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨方法吧!
前言
估计最近很火的连续剧《隐秘的角落》大家趁着端午假期都看过了吧?小编也跟着潮流,一口气把12集的连续剧全部看完了。看过的人肯定对朋友圈里有人发的“一起去爬山”、“小白船”、“还有机会吗”的意思心照不宣。没看过的,如果已为人父人母的,强烈要求看一下。
剧很精彩,但追剧界有句俗话说得好:“弹幕往往比剧更精彩”,为了让精彩延续下去,咱们来看看该剧弹幕的部分。电视剧是在爱奇艺独播,因此从爱奇艺上爬虫最为合适。
爬取弹幕
爱奇艺的弹幕数据是以 .z 形式的压缩文件存在的,先获取 tvid 列表,再根据 tvid 获取弹幕的压缩文件,最后对其进行解压及存储,大概就是这样一个过程。
def get_data(tv_name,tv_id):
url = https://cmts.iqiyi.com/bullet/{}/{}/{}_300_{}.z
datas = pd.DataFrame(columns=[uid,contentsId,contents,likeCount])
for i in range(1,20):
myUrl = url.format(tv_id[-4:-2],tv_id[-2:],tv_id,i)
print(myUrl)
res = requests.get(myUrl)
if res.status_code == 200:
btArr = bytearray(res.content)
xml=zlib.decompress(btArr).decode(utf-8)
bs = BeautifulSoup(xml,"xml")
data = pd.DataFrame(columns=[uid,contentsId,contents,likeCount])
data[uid] = [i.text for i in bs.findAll(uid)]
data[contentsId] = [i.text for i in bs.findAll(contentId)]
data[contents] = [i.text for i in bs.findAll(content)]
data[likeCount] = [i.text for i in bs.findAll(likeCount)]
else:
break
datas = pd.concat([datas,data],ignore_index = True)
datas[tv_name]= str(tv_name)
return datas共爬取得到201865 条《隐秘的角落》弹幕数据。
弹幕发射器
按照用户id分组并对弹幕id计数,可以得到每位用户的累计发送弹幕数。
#累计发送弹幕数的用户 danmu_counts = df.groupby(uid)[contentsId].count().sort_values(ascending = False).reset_index() danmu_counts.columns = [用户id,累计发送弹幕数] danmu_counts.head()
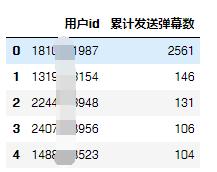
累计发送弹幕数用户top5
第一名竟然发送了2561条弹幕,这只是一部12集的网剧啊。
难道他/她是水军?每条都发的差不多?
df_top1 = df[df[uid] == 1810351987].sort_values(by="likeCount",ascending = False).reset_index() df_top1.head(10)
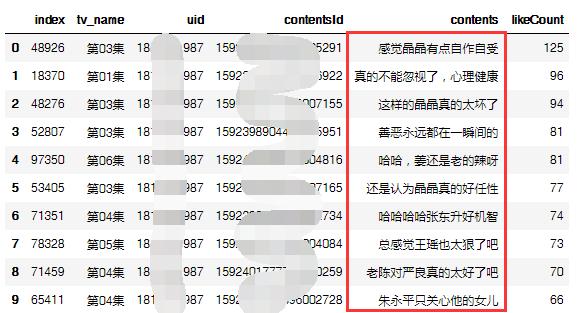
然而并不是,每一条弹幕都是这位观众的有感而发,可能他/她只是在发弹幕的同时顺便看看剧吧。
这位“弹幕发射器”朋友,在每一集的弹幕量又是如何呢?
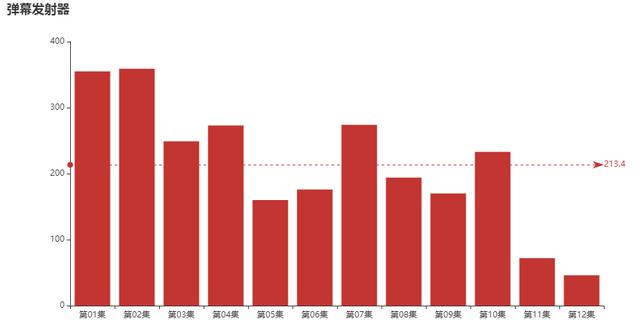
分集&平均弹幕量
是不是通过上图可以侧面说明个别剧集的戏剧冲突更大,更能引发观众吐槽呢?
“弹幕发射器”同志,11、12集请加大输出!
这些弹幕大家都认同
抛开“弹幕发射器”同志,我们继续探究一下分集的弹幕。
看看每一集当中,哪些弹幕大家都很认同(赞)?
df_like = df[df.groupby([tv_name])[likeCount].rank(method="first", ascending=False)==1].reset_index()[[tv_name,contents,likeCount]] df_like.columns = [剧集,弹幕,赞] df_like
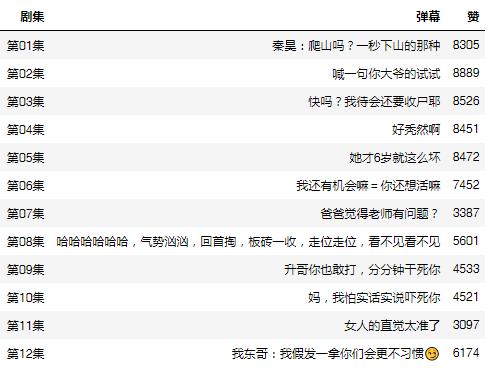
每一集中点赞最多的弹幕
每一集的最佳弹幕都是当集剧情的浓缩,这些就是观众们票选出来的梗(吐槽)啊!
应该不算剧透吧,不算吧,不算吧
实在不行我请你去爬山也可

除了剧本、音乐等,“老戏骨”和“小演员”们的演技也获得了网友的一致好评。
这部剧虽然短短12集,但故事线不仅仅在一两个人身上。每个人都有自己背后的故事,又因为种种巧合串联在一起,引发观众的持续性讨论。
我们统计一下演员们在弹幕中的出现次数,看看剧中的哪些角色大家提及最多
看完了这篇文章,相信你对Python爬取《隐秘的角落》的弹幕有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





