在GOPS2017北京站上,来自去哪儿的郑松宽演讲《 去哪儿网应用运维自动化演进之路 》,分享了 在自动化构建过程中所遇到的障碍以及我们是怎么样跨越这些障碍,我们遇到了哪些坑,以及怎么填平这些坑的过程。
我是2013年加入去哪儿网,加入之后一直在从事运维开发工作。去哪儿网运维开发有一个特点,我们所有开发既当PM,又当QA,也没有区分前端工作还是后端工作,用现在比较流行的话说,我们都是全栈工程师。加入去哪儿这几年做的工作也是比较零碎的,哪里有需求就去哪里。
概括起来主要涉及到主机管理、应用管理、监控、报警平台等设计,开发和运维这几方面的工作。下面简单介绍一下我们的运维团队。
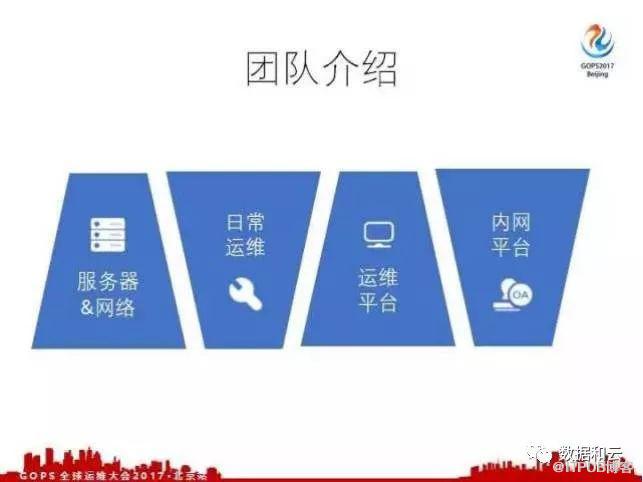
第一个方面 ,我们的运维团队负责公司所有的服务器、网络等硬件平台的运维工作;
第二个方面 ,部分人员从事日常运维,包括QVS的部署,Nginx的配置,应用上线的支持,还有存储的部署等日常的运维工作,这些运维工作还包括报警的告知、故障的通报和跟踪;
第三个方面 ,2013年左右我们开始研发自己的运维平台;
第四个方面 ,负责公司内网的应用,这些内网包括OA系统、HR系统,还有IT资产管理平台等等。
首先简单介绍一下去哪儿网应用运维平台。
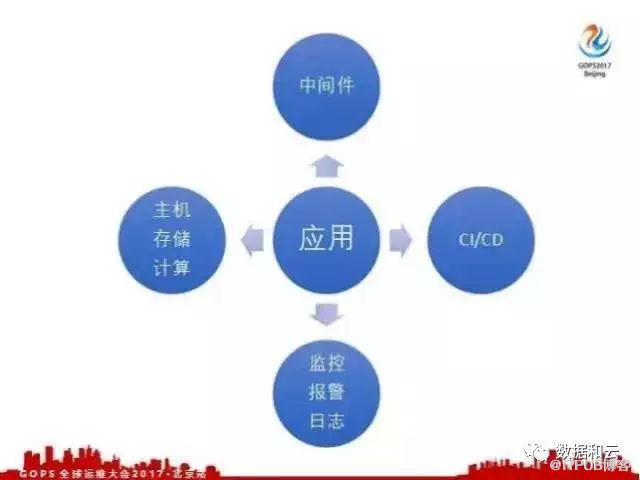
我们知道一个应用从开发到线上运行,它的生命周期主要涉及到四个部分:
第一部分 ,应用的资源管理,这些资源包括应用部署需要的主机、应用的图片、文件,对象存储所需要的存储资源,应用通信和其他的网络带宽,还有应用所需要的计算资源等等。
第二部分 ,为了提高应用开发的效率,并且去保证应用开发的规范,我们公司会提供公共的中间件,这些中间件包括日志收集、应用配置注册、监控报警指标的收集,还有应用调用路径。
第三部分 ,为了将我们的应用发布到线上,我们需要对应用进行代码管理和构建测试到发布到线上,这需要 CI/CD 持续发布和持续集成。
第四部分 ,当一个应用发布到线上之后,我们需要对这个应用的性能指标和业务指标进行监控、报警和分析,这样我们就需要大家应用相关的监控、报警和日志分析平台。
去哪儿网的业务也是一步步发展起来的,机器从几十台到上万台,在发展的过程中我们遇到了很多问题,在不同的阶段我们也提出了不同的解决方案。
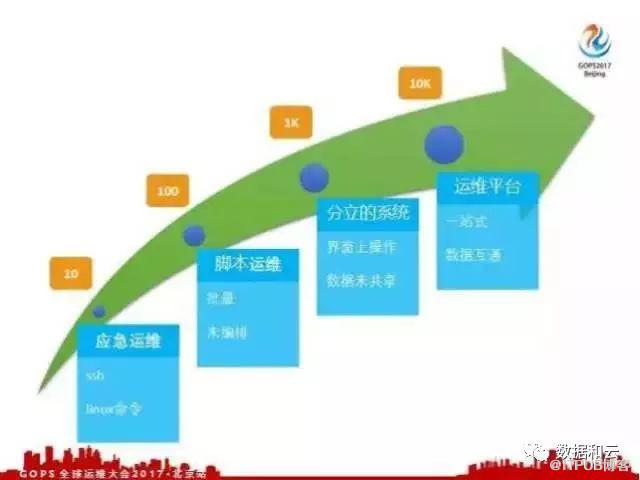
概括来说,去哪儿网经历的阶段分为四个部分:
第一个阶段 ,运维机器数量比较少,大部分的工作都是应急运维。比如我们发现一个应用有问题了,我们登录到这个应用的相关机器上,手动执行Linux命令,去查看这个机器的资源使用情况。比如CPU是不是太高了,是不是磁盘占满了,这个阶段也没有用到太复杂的脚本,基本上都是手动操作,几十台左右。
第二个阶段 ,随着规模扩大,手动写了很多脚本,有了这些脚本之后我们就可以批量去执行任务,可以在多台机器上批量部署应用和监控。这个阶段,我们称为脚本运维的阶段,这个阶段我们是利用脚本并且结合开源的系统,我们可以完成对数百台机器的运维。
第三个阶段 ,随着规模越来越大,脚本运维也不够了,脚本运维远远不能满足,脚本可能都是分类的脚本,并没有经过合理的编排,这样脚本的执行顺序就比较重要,没有合理编排可能会导致一些问题。
我们开发一些相关的系统,用系统把相关的脚本串联起来,编排好组成一个一个分离的操作。比如说一台机器的新建和删除就是单独的操作,把这些做成系统,运维人员可以在界面上操作。
这个阶段,称之为分立系统,他们的数据基本上在各个系统之间没有实现一个比较好的共享。这个阶段能运维的主机数量也比较有限,数千台的主机是比较好的。
第四个阶段 ,紧接着去哪儿网的机器规模突破了万台以上,这时候我们考虑能不能从一个比较高的角度去合理设计一下我们的运维平台。为我们的运维工作提供一站式的服务,在一站服务的基础上我们实现数据互通,这样就可以交互起来,做一些自动化的工作。在这个时期也是今天我主要要讲的内容,就是运维平台的建设。

运维平台的建设过程中我们遭遇了很多困难也遇到了很多坑,在这些困难之中总结出来三个关键点,主机管理、监控报警和数据互通。
主机管理
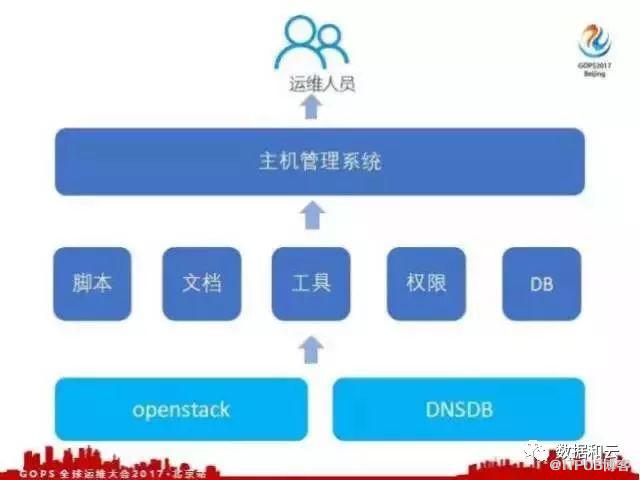
去哪儿网的主机管理系统是以 OpenStack 和 DNSDB 为核心的 , OpenStack 是调度创建虚拟机, DNSDB 是我们公司的域名管理系统。通过 DNSDB 我们就可以将一个机器的名称、部门、用途和它所在的机房组成一个唯一的域名,我们用这个唯一的域名来标识我们这台主机。
在 OpenStack 、 DNSDB 之上,我们写了大量的脚本文档和工具,将这些脚本文档和工具编排起来,封装成一个一个的操作,并且我们给这些操作赋予一些相关的权限。我们把主机的信息、流通的管理、权限的配置还有操作日志的查询都会存在日志库里。最后我们会把一个主机管理系统的界面暴露给运维人员,运维人员通过这个界面来管理我们的主机。
有了主机管理平台之后,运维人员就可以非常方便的在这个平台上创建、销毁主机,查看主机的相关信息,比如说它的配置、过保信息等等。我们在新加每台机器的过程中都会默认给这个机器加上监控报警,机器有报警的时候也会通知到相关的负责人。
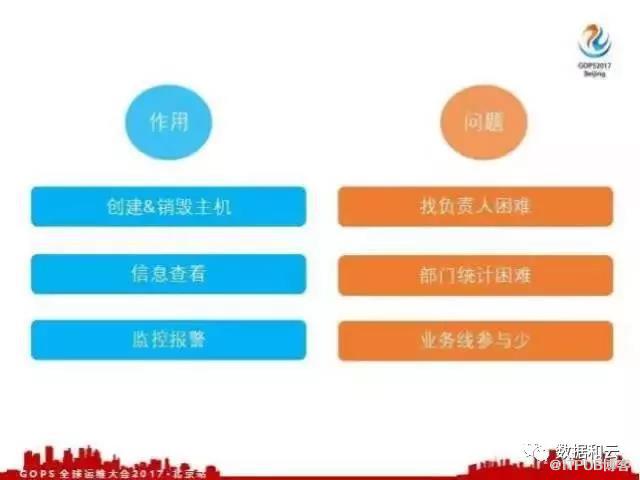
这样做其实还是有一个问题,一个比较大的问题是,我们这个系统是怎么开发给运维人员使用的,开发人员并没有权限登录这个系统。假如说开发人员提出来一个需求,我要创建一台主机,就需要给OPS发邮件,OPS创建这台主机的时候,其实并没有非常准确的记录到这个负责人是谁,他可能会写在备注里,这个备注随着时间的推移,有可能不准了。因为当时的负责人可能离职了或者转岗,这种情况都是经常发生的。
这个机器所负责的部门也没有去很好的记录,因为这个部门很多只是体现在主机这个名称上,但是有可能这台机器在使用的过程中可能会转给其他业务线的部门使用,这样我们拿到的部门信息也是不准确的。还有一个问题DB系统只对运维人员开放,业务线参与很少,导致整个主机的相关信息其实是不够准确的,因为OPS人员毕竟有限,不可能非常准确的维护这些信息。
这样我们就想到一个方案,通过应用树去解决。
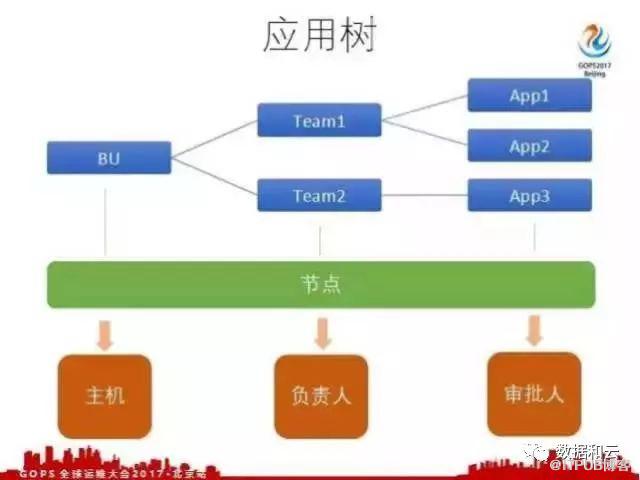
去哪儿网把业务线按照功能区划分到各个BU,应用树BU作为第一级,下面有部门,部门下面还有更小的部门,这个层级可能是多个的。最后一级是部门下面所负责的应用,应用是作为最后一级的。我们把所有的级别都作为一个节点,在每个节点上都可以绑定主机,给节点添加负责人,给节点添加审批人,下面我会介绍审批人的权限和角色。有了这个应用树之后,业务线开发参与进来,参与管理主机,他们的负责人和部门信息更加准确。
一台机器出现异常,我想非常迅速找到这个机器的负责人也非常容易。假如说宿主机马上要过保了,它上面的所有的虚机我都需要找到这个虚机的负责人,通知这些人去执行相关的操作,比如像虚机下线、应用下线,这样可以避免很多运维宿主机过保而导致的故障。因为机器的负责人比较精确了,我们的报警通知会默认把机器的监控报警都通知给相关的负责人,由负责人来处理机器相关的基础硬件报警。
每个季度都会统计资源的消耗,也会对下个季度机器的采购做规划和预算。拿到比较上级的部门,比如拿到一个BU节点,可以通过应用树很容易拿到这个部门下都有哪些机器,他这个月的增长量是多少,我们就可以很方便的预测下个季度我们需要采购多少量的机器,从而制定更加合理的预算。有了用户之后,负责人、部门和机器的关系都是比较明确的。
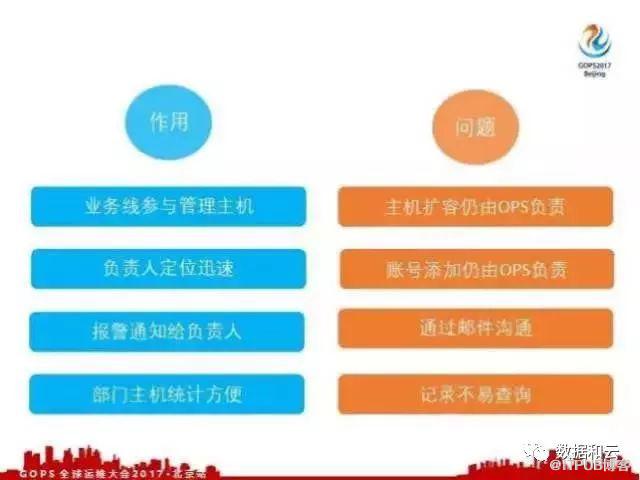
但是存在一个问题,申请资源的时候,仍然需要有OPS操作的,账号添加也是由OPS负责,一个开发人员想要扩容一台机器或者给一个机器去添加账号,要怎么做?他就需要给操作OPS的 team 发邮件,说我要给应用扩容两主机,或者给哪台主机添加一个账号。这样做有什么坏处,一是OPS不可能实时在线也不可能盯着系统,这样OPS响应非常慢,邮件查询起来非常不方便,邮件时间长了可能丢失,定位问题也不容易。
怎么解决这个问题接下来又做了两个系统,第一个是主机申请系统,第二是账号申请系统。
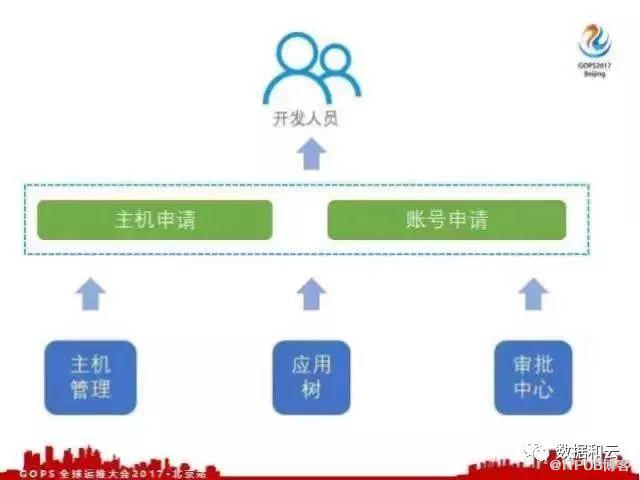
这两个系统以主机管理、应用树和审批中心为基础,调用主机管理、应用树和审批中心为接口,通过调用接口去编排一些合理的主机申请和账号申请的流程。刚才我们提到主机申请的时候,谁有权限申请,应用树上的每个节点的负责人都有权限去申请这个部门的主机或者这个应用的主机,节点上的审批人他就有权限去审批这个节点下的主机。这样OPS就不用参与太多,他们可以自动申请主机和账号。
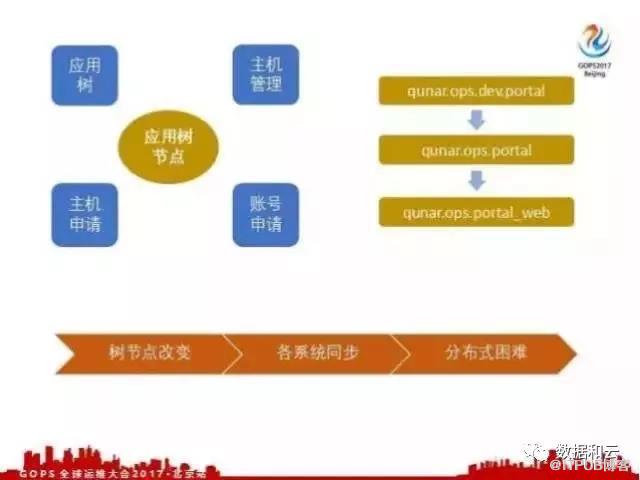
最后我们做了一个界面,把这个界面暴露给开发人员,开发人员可以去申请主机申请账号。通过应用树、主机管理、主机申请、账号申请这四个平台做了闭环,核心是应用树节点,应用树节点把四个部分串联起来。
应用树节点有什么问题,我们会改变它,比如刚开始有个 portal 应用放在OPS开发下,有一天发现这个放的位置不太对,需要直接放在OPS下面就可以了,这样就需要把 portal 从运维开发移动到OPS下面。
还有一个, portal 随着业务增长,应用越来越大,需要拆分成几个部分,比如需要拆分成 portal-web 和 portal-api ,这种树节点改变会导致什么?我们每个系统记录的都是应用树节点,每个应用树节点的改变各个系统都需要去同步,这就相当于在一个分布式系统里有一个有状态的模块,就是应用树节点这个模块。其实它是有状态的,有状态就导致我们分布式比较困难,我们想把应用树节点推广到更多的系统中,那就会非常困难,就会不断面临同步的问题。
这个问题怎么解决,比如说对于一个普通的居民来说,怎么在各个系统之间共享数据,比如我一个人怎么在公安系统在户籍系统在银行系统等等各个系统之间,怎么样共享我的信息。现实中就有一个非常好的实践,那就是使用身份证,身份证有唯一的ID,通过这样一个唯一的ID,就可以标识这个应用,并且这个ID永远不会改变。

我们怎样去找到这样一个ID,第一个方案,用数据库里的自增ID或者 UUID 来标识应用。这样可以保证应用ID唯一且不改变,但是因为自增ID和 UUID 在文字上没有明确意义,我们开发人员拿到这个ID不便于记忆,也不便于沟通。
假如要用自增ID或 UUID ,需要用另外一个系统去专门看我有多少这样的ID,先找到这个ID,再和其他系统进行交互、沟通,非常不方便。第二个方案,借鉴身份证,用数字,比如110代表北京,后面代表县区,代表自己的出生日期。
借鉴身份证ID,我们使用了这样一个叫 Appcode 的来标识应用, Appcode 基本上以下滑线分割的,第一个是应用所在的部门,第二个是应用的描述,这个层级也可以非常长。用这样一个 Appcode 去代替应用数节点,既能保证唯一且不可改变,便于大家记忆,沟通也比较方便,我们最后选的是第二套方案。
监控报警
下面看一下我们是怎么在运维平台去做监控报警的。作为一个互联网公司,保证7x24小时的提供服务是一个最基本的要求,我们要怎么去保证7x24小时服务?假如说系统有问题的时候,我们能够提前预警发现,等系统真正出现问题的时候,我们能够及时的发现。要保证这两点,我们就需要监控报警系统。
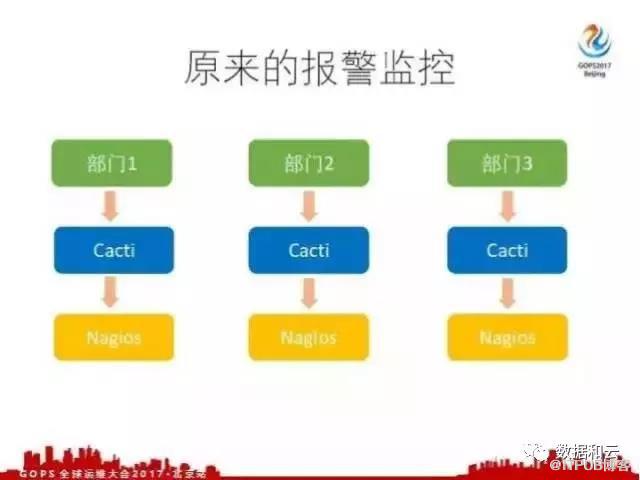
去哪儿网的监控报警系统也是经历了很长时间的挣扎,刚开始每个部门都会维护着自己一套系统,刚开始是 Cacti 和 Nagios 这两个模块去搭建的,这样存在什么问题?

第一Cacti 部署在单机上,不能横向拓展,导致性能比较差。假如单机出现异常甚至宕机,那我们的监控报警系统就完全不可用,所以这是一个非高可用的方案。
第二是每个部门都会维护一套自己的监控系统,甚至比较大的部门,像酒店机票这种大部门,他们可能会维护很多套,每一套都需要有专门的人员来运维,运维成本也非常高。
由于之前的系统没有很好的权限管理,这个系统只能有专门的人来负责,因为放开给其他人权限是比较危险的,可能有人不小心操作了什么,把报警删掉或者修改报警配置,所以只有把报警交给专人负责。
要定制一个报警监控沟通成本非常高,我们需要联系自己的相关负责人,然后再去报警配置。开发人员觉得太麻烦了,干脆不做了,或者做得非常少,导致我们监控的面不够全,可能有一些异常甚至是故障都没有及时发现,效率是比较低下的。怎么解决这个问题?我们做了一个公司级的统一监控报警平台 Watcher 。有这样几个目标:
第一是高可用,一台机器或几台机器挂了,对我们没有影响或者影响很小。
第二是比较容易的让大家去配置这个报警,我们做了一个权限管理系统,也是借鉴应用树做了一个树状的权限管理系统,把整个 Watcher 界面开放给所有的开发人员,这样大家就可以非常方便的配自己的报警和监控。
简单介绍一下 Watcher , Watcher 是基于 Graphite 深度开发的, Watcher 平台既支持主机基础监控报警同时也支持业务监控报警,都在一个统一的平台上,监控报警可以由开发人员在统一的界面上查看和配置。
Watcher 大概2014年开始做,现在有三年时间,在公司也推广得很好。现在 Watcher 已经接入1500个以上的应用, Watcher 目前的指标数量已经超过了2000万,报警数量已经超过了40万,接入了基础监控的机器数量也超过了4万台。 Watcher 这么大的规模,我们用了什么样一个架构呢?
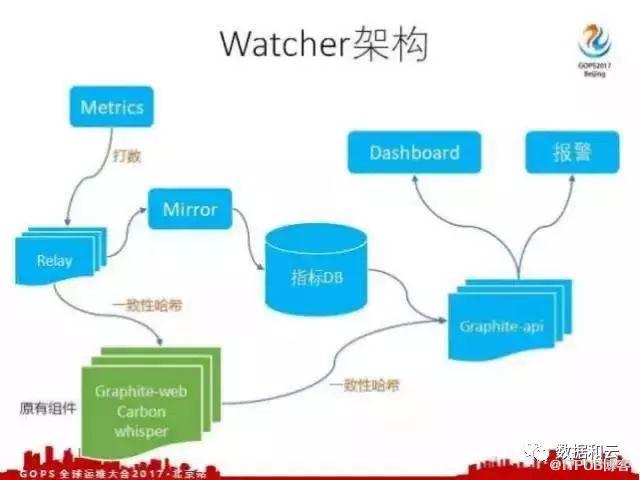
这个架构图只是我们一个 Watcher 集群的架构图,我们在打数的时候会区分每个指标要打到哪个集群上,我们怎么区分?以 Metrics 作为标识,比如所有的测试数据测试指标都以t开头,所有的主机数据都以h开头,我们用s.flat就代表机票这个部门,机票这个部门所有指标打数的时候就要配置好一个服务器,这个服务器也是用域名来表示的,它自己本身就代表一个机票的监控报警集群。
在上面的集群架构图里,最下边绿色的是 Graphite 原有的组件,在原有组件上我们自己开发了几个相关的组件。第一个是 Relay ,每个指标打过来之后,我们通过 Relay 把指标分布在多台机器上,这个是通过一致性哈希来实现的。
等我们取数的时候, Graphite-api 这部分也是我们自己开发的, Graphite-api 里也有同样的一致性哈希算法,通过这个算法找到这个指标在这个集群的哪一个机器上,调用这个机器上的 Graphite-web 下的api,然后拿相关的数据。
这是一个集群的架构,有多个集群,我们 Watcher 要做一个统一的界面,在这个界面上配置自己的监控的时候,选择数据源,对于打数的人他清楚这个指标在什么地方。能不能做一个统一的数据源,让用户来使用,这样我们就在组件里加上了一个纯指标的数据库,每次流量过来之后,我们就会把这个指标的名称写到我们数据库里一份,同时记录它在哪个集群。
这样我们就可以对外报一个统一的 Graphite-api ,假如说一个指标我们要起 s.flat-xx 的指标,首先是调用api,去找 s.flat-xx 这个指标在什么集群里,发现在机票的集群里,再通过一致性哈希就可以把这个指标取出来了。 Graphite-api 上第一部分是借这个 Dashboard ,是借这个报警。
讲完整个的 Watcher 架构,看一下主机监控怎么做的?
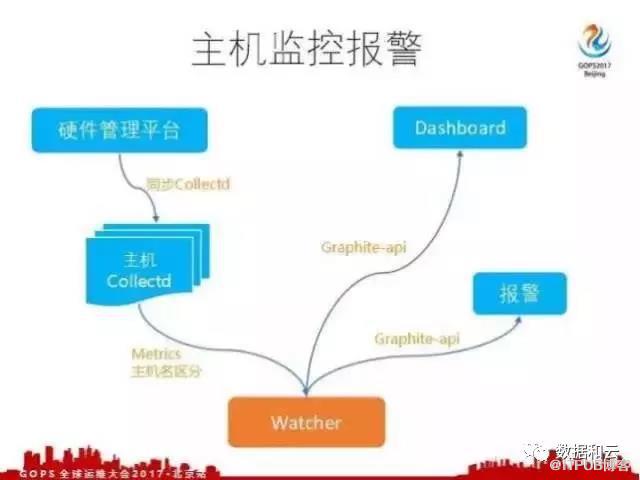
首先有一个硬件管理平台,维护着主机监控的相关信息。最主要的是会编排代理,去维护代理的版本配置,会不停的去扫描这个主机,往主机上部署,也会定时检查指标是否收集了。假如这个主机指标出现断点了或者有问题了,会报警去检查,到底是 Collectd 出问题了还是系统出问题了还是网络出问题了。
每个主机上部署 Collectd 之后会根据不同的配置打不同的指标,比如CPU的使用情况,内存的使用情况,网络带宽的使用情况,这些都将指标打成了 Watcher 。每个主机的指标可能都是相同的,怎么区分不同主机的指标,我们就以主机的名称作为区分。接入到 Watcher 之后,我们就可以调用api,在 Dashboard 上调用。
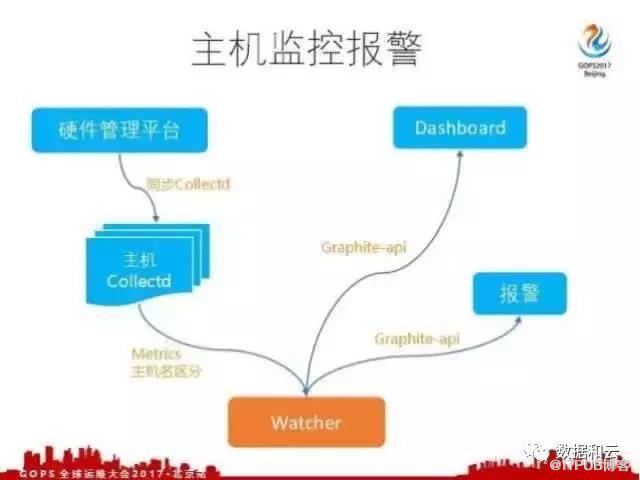
业务监控也是比较类似的,应用接入之后会暴露出api,里面就是最近1分钟之内应用的监控数据,每分钟 Qmonitor server从所有的机器上去拉这个文件,拿了文件之后做集中的分析,分析完之后做相应的处理。比如说对应用进行计数,算完之后以 Appcode 作为标识来区分不同的指标,将指标推送到 Watcher 。推送到 Watcher 之后,同样可以查询监控,检查应用指标的健康状态。
数据互通
下面讲一下我们怎么在整个运维平台实现数据互通的。我们在监控报警和主机管理里都提到了一个 Appcode ,在去哪儿网 Appcode 到底是什么?
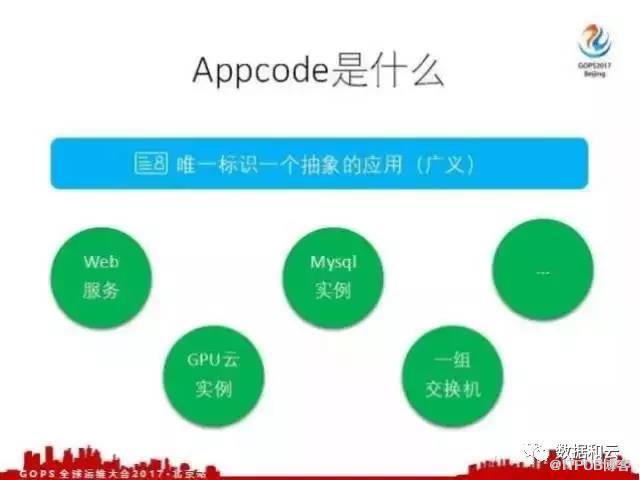
其实它就是唯一的一个标识应用,我们将一个应用进行了抽象化,意思其实是更加广义。在去哪儿网一个应用可以是一个Web服务,也可以是一个GPU云实例,也可以是 MySQL 实例,甚至可以是一组交换机,还可以是其他的。

为什么要对应用做这样的抽象化,做抽象化的好处就是我们不用去考虑服务和资源的具体细节,就用一个App代表一个服务或者代表一个资源,在这个抽象化的过程中可以不考虑这个服务到底做什么,这个资源到底什么样。给广义的应用定义共同的属性,包括这个应用的负责人、应用的权限、应用的账单等等。
有了这些共同的属性,我们就可以将 Appcode 在多个系统中进行扩展,分布在各个系统中去共享数据。这样做的作用是什么?有了 Appcode 之后,我们就可以在我们的各个系统中形成一种共同的语言,这个共同语言就是 Appcode 。有了这个共同语言之后,我们就可以把各个系统之间的数据连接起来,最后实现一个数据的互通。实现数据互通之后有什么好处?
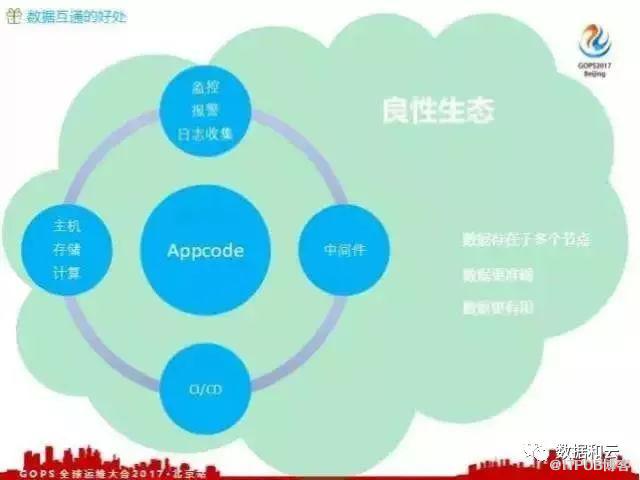
第一个方面,我们把 Appcode 放在各个系统之中监控 ,比如说主机、存储、计算,这是应用的资源部分。 Appcode 分布在多个系统之中,多个系统中相互作用,一个数据只有分布的节点越多,对这个数据的准确性要求越高,因为这个数据可能在多个系统间使用,它的负责人就会更加重视这份数据,所以他们更愿意让这个数据变得更加准确。
数据更准确之后,它就变得更加有用,各个系统之间因为数据准确了,都愿意使用这份数据,形成比较良性的生态循环。因为数据互通了,我们就可以做一个 Portal 平台,对外暴露一个统一的界面,可以对我们应用所涉及的所有部分进行一站式管理。
第二是CI/CD部分 ,应用发布的主机也是和 Appcode 相关联的,应有扩容之后发布的主机也是同样同步过来,发布选择这些主机直接发布就可以了,不需要手动再在去填写这些主机列表。
第三是监控分为两个方面,一个是基础监控,一个是业务监控 。基础监控也是通过 Appcode 维度可以查看相关的主机的基础监控。对于业务监控在应用监控指标的收集,也可以通过 Appcode 来拿到它的主机列表,自动去给业务监控指标收集添加这些机器列表,添加完之后收集上来这些应用相关主机的监控指标和日志。
第四是报警系统 ,因为有了 Appcode 之后, Appcode 它会对应着一些共同的监控报警项,比如像 JAVA 里的GC报警。我们有了 Appcode 之后,就可以给每个 Appcode 上的所有机器都默认添加GC报警。这个GC报警联系人就是 Appcode 一个负责人,每台机器扩容之后它的GC报警也就自动添加了。日志收集也是一样的,之前我们可能还是需要在这个平台手动维护,有了 Appcode 就可以同步这个列表。
Portal 平台简介
简单介绍一下 Portal 平台,现在也是正在开发中的平台。
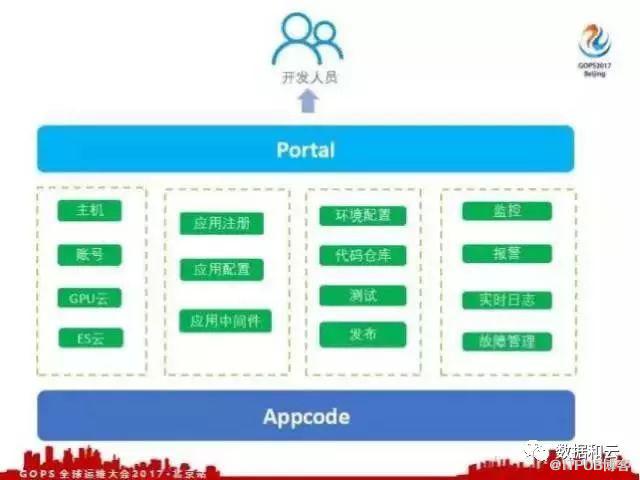
Portal 就是以 Appcode 为基础,在 Appcode 的基础上连接了各个运维系统,比如说主机、账号、GPU云、ES云,应用注册、应用配置、应用中间件,环境配置、代码仓库、测试、发布、监控、报警、日志收集,故障管理。我们把这些系统都汇总到一个 Portal 界面上暴露给开发人员,开发人员进入这个系统之后就可以一站式的把应用相关的想做的事情都做完,这样开发人员也非常方便。
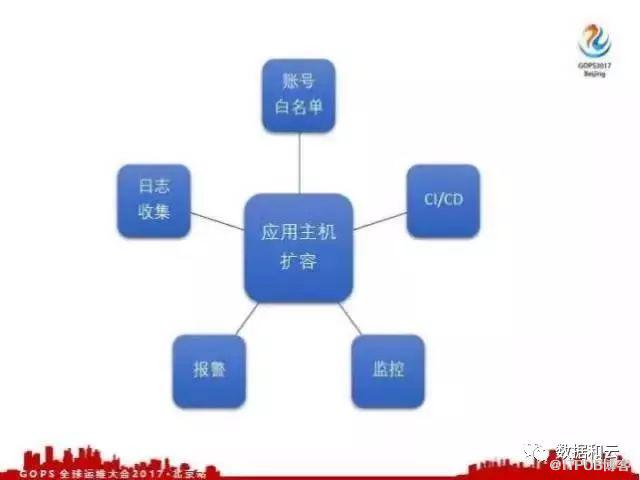
数据互通另外一个好处,刚才讲主机管理,主机可能会有不同维度来解释这个主机是不太一样的。比如应用发布,有发布主机列表,算账单的时候有个账单主机列表,收集日志的时候也有主机列表,收集监控报警也有主机列表。
只要数据互通之后,我们就可以将这些数据串联起来。比如我们应用,它的主机需要扩容了,扩容两台主机,扩容之后我们就可以自动根据这个应用上的负责人去为主机添加对应的账号,这样它的负责人就可以利用这个账号登录相应的系统,进行相应的操作。
数据库还有其他的有IP白名单限制,有了数据互通之后,一个应用它的白名单配置就没必要记录每一个主机了,就记录 Appcode 就可以了。
数据互通还有另外一个好处,有 Appcode 之后我们就可以非常方便的去计算这个应用所耗费的账单。为什么要计算一个应用的账单?

一方面,让我们提高一下成本意识,成本意识在选的过程中也是需要考虑的。比如一个业务线它有一些数据需要记录下来,它可以选择任何系统,也可以选择数据库,也可以选择 Watcher 。假如说这个业务访问的频率非常低,比如一天就几次、十几次,把这个数据记录到 Watcher 其实成本非常高昂,因为 Watcher 数据膨胀非常厉害,选择数据库或者日志其实更划算。
第二可以优化实现,假如你由于算法导致机器资源大量使用,有了账单之后,他们会去节约成本。有了成本意识之后,我们可以更加合理的分配资源。比如有的应用本身不是很重要,还申请了特别多的机器,机器使用率也不高,拿到账单一看,这么一个不重要的应用竟然耗费这么大的账单,然后他们就会回收一部分。
目前我们也在不断的去接入各种各样的应用账单,比如说主机账单、网络带宽账单、监控报警、日志收集、大量的存储,还有计算资源账单,还有其他的一系列的账单,都会慢慢接入进来。
最后做一下总结,在去哪儿网运维自动化历程中,我们经历了不同的阶段。我们发现等应用扩大到一定规模的时候,需要运维平台化,自动的或者半自动的方式是非常耗费人力资源的,并且它也会大致发现一些错误甚至是故障。去哪儿网运维自动化也是做得非常不错的,怎么来体现?
我入职的时候日常运维的人员大概有五六个,现在我们日常运维的人员仍然是六个,我们又推了一个运维机器人,运维第七人。我们其实还是保持在六人的状态,我们规模扩大了很多倍,从百台到万台,扩大了上百倍的规模,但是我们日常运维人员并没有增加,这是运维平台自动化带来的好处。
应用的可用性需要监控报警系统的保证,基本上在一个应用上线之前就会去把它所有关键的报警和监控架好,这样应用有问题的话就会迅速回滚或者去 debug 。因为我们有完善的监控报警系统,所以去哪儿网的故障还算比较少的,平均来说一天也就两三个故障。
但是去哪儿网的故障和其他的故障可能不太一样,去哪儿网的故障要求比较苛刻,一次网络故障我们就会记录批次的故障。比如 Watcher 的监控系统不出图了,超过5分钟了,我们可能会深究P1和P2的故障。在这样的严格要求下,我们的故障也不会太高,我入职四年来,现在累计的故障数也就3000个左右。

要保证我们整个运维生态的发展,我们需要将数据打通,打通需要给应用一个ID,有了这个ID之后,我们就可以在各个运维系统和平台上共享数据,形成一个良性的生态循环。
作者介绍 :郑松宽, 去哪儿网 高级运维工程师。2013年加入去哪儿网平台事业部,从事运维开发工作。工作中主要负责公司监控系统的开发,应用管理平台Portal的设计、开发和运维
转自 :【高效运维

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





