
и®әж–Үй“ҫжҺҘпјҡhttps://static.aminer
.cn/misc/pdf/minrror.pdf
дёҖгҖҒж‘ҳиҰҒ
常规зҡ„зҘһз»ҸжңәеҷЁзҝ»иҜ‘(NMT)йңҖиҰҒеӨ§йҮҸе№іиЎҢиҜӯж–ҷпјҢиҝҷеҜ№дәҺеҫҲеӨҡиҜӯз§ҚжқҘиҜҙзңҹжҳҜеӨӘйҡҫдәҶгҖӮжүҖе№ёзҡ„жҳҜпјҢеҺҹе§Ӣзҡ„йқһе№іиЎҢиҜӯж–ҷжһҒжҳ“иҺ·еҫ—гҖӮдҪҶеҚідҫҝеҰӮжӯӨпјҢзҺ°жңүеҹәдәҺйқһе№іиЎҢиҜӯж–ҷзҡ„ж–№жі•д»Қж—§жңӘе°Ҷйқһе№іиЎҢиҜӯж–ҷеңЁи®ӯз»ғе’Ңи§Јз ҒдёӯеҸ‘жҢҘеҫ—ж·Ӣжј“е°ҪиҮҙгҖӮ
дёәжӯӨпјҢжң¬ж–ҮжҸҗеҮәдёҖз§Қй•ңеғҸз”ҹжҲҗејҸжңәеҷЁзҝ»иҜ‘жЁЎеһӢпјҡMGNMT(mirror-generative NMT)гҖӮ
MGNMTжҳҜдёҖдёӘз»ҹдёҖзҡ„жЎҶжһ¶пјҢиҜҘжЎҶжһ¶еҗҢж—¶йӣҶжҲҗдәҶsource-targetе’Ңtarget-sourceзҡ„зҝ»иҜ‘жЁЎеһӢеҸҠе…¶еҗ„иҮӘиҜӯз§Қзҡ„иҜӯиЁҖжЁЎеһӢгҖӮMGNMTдёӯзҡ„зҝ»иҜ‘жЁЎеһӢе’ҢиҜӯиЁҖжЁЎеһӢе…ұдә«йҡҗиҜӯд№үз©әй—ҙпјҢжүҖд»ҘиғҪеӨҹд»Һйқһе№іиЎҢиҜӯж–ҷдёӯжӣҙжңүж•Ҳең°еӯҰд№ дёӨдёӘж–№еҗ‘дёҠзҡ„зҝ»иҜ‘гҖӮжӯӨеӨ–пјҢзҝ»иҜ‘жЁЎеһӢе’ҢиҜӯиЁҖжЁЎеһӢиҝҳиғҪеӨҹиҒ”еҗҲеҚҸдҪңи§Јз ҒпјҢжҸҗеҚҮзҝ»иҜ‘иҙЁйҮҸгҖӮе®һйӘҢиЎЁжҳҺжң¬ж–Үж–№жі•зЎ®е®һжңүж•ҲпјҢMGNMTеңЁеҗ„з§ҚеңәжҷҜе’ҢиҜӯиЁҖ(еҢ…жӢ¬resource richе’Ң low-resourceиҜӯиЁҖ)дёӯе§Ӣз»ҲдјҳдәҺзҺ°жңүж–№жі•гҖӮ
дәҢгҖҒд»Ӣз»Қ
еҪ“дёӢзҘһз»ҸжңәеҷЁзҝ»иҜ‘еӨ§иЎҢе…¶йҒ“пјҢдҪҶдёҘйҮҚдҫқиө–дәҺеӨ§йҮҸзҡ„е№іиЎҢиҜӯж–ҷгҖӮ然иҖҢпјҢеңЁеӨ§еӨҡж•°жңәеҷЁзҝ»иҜ‘еңәжҷҜдёӯпјҢиҺ·еҸ–еӨ§йҮҸе№іиЎҢиҜӯж–ҷ并йқһжҳ“дәӢгҖӮжӯӨеӨ–пјҢз”ұдәҺйўҶеҹҹд№Ӣй—ҙе№іиЎҢиҜӯж–ҷе·®ејӮеӨӘеӨ§пјҢзү№е®ҡйўҶеҹҹеҶ…жңүйҷҗзҡ„并иЎҢиҜӯж–ҷ(дҫӢеҰӮпјҢеҢ»з–—йўҶеҹҹ)пјҢNMTйҖҡеёёеҫҲйҡҫе°Ҷе…¶еә”з”ЁдәҺе…¶д»–йўҶеҹҹгҖӮеӣ жӯӨпјҢеҪ“е№іиЎҢиҜӯж–ҷдёҚи¶іж—¶пјҢе……еҲҶеҲ©з”Ёйқһе№іиЎҢеҸҢиҜӯж•°жҚ®(йҖҡеёёиҺ·еҸ–жҲҗжң¬еҫҲдҪҺ)еҜ№дәҺиҺ·еҫ—д»Өдәәж»Ўж„Ҹзҡ„зҝ»иҜ‘жҖ§иғҪе°ұиҮіе…ійҮҚиҰҒдәҶгҖӮ
еҪ“дёӢзҡ„NMTзі»з»ҹеңЁи®ӯз»ғе’Ңи§Јз Ғйҳ¶ж®өдёҠйғҪе°ҡжңӘе°Ҷйқһе№іиЎҢиҜӯж–ҷеҸ‘жҢҘжһҒиҮҙгҖӮеҜ№дәҺи®ӯз»ғйҳ¶ж®өпјҢдёҖиҲ¬жҳҜз”ЁеӣһиҜ‘жі•(back-translation )гҖӮеӣһиҜ‘жі•еҲҶеҲ«жӣҙж–°дёӨдёӘж–№еҗ‘зҡ„жңәеҷЁзҝ»иҜ‘жЁЎеһӢпјҢиҝҷжҳҫеҫ—дёҚеӨҹй«ҳж•ҲгҖӮз»ҷе®ҡsourceиҜӯз§Қж•°жҚ®xе’ҢtargetиҜӯз§Қж•°жҚ®yпјҢеӣһиҜ‘жі•е…ҲеҲ©з”Ёtgt2srcзҝ»иҜ‘жЁЎеһӢе°Ҷyзҝ»иҜ‘еҲ°xЛҶгҖӮеҶҚз”ЁдёҠиҝ°з”ҹжҲҗзҡ„дјӘзҝ»иҜ‘еҜ№(xЛҶпјҢy) жӣҙж–°src2tgtзҝ»иҜ‘жЁЎеһӢгҖӮеҗҢзҗҶеҸҜд»Ҙз”Ёж•°жҚ®xжӣҙж–°еҸҚж–№еҗ‘зҡ„зҝ»иҜ‘жЁЎеһӢгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢиҝҷйҮҢдёӨдёӘж–№еҗ‘дёҠзҡ„зҝ»иҜ‘жЁЎеһӢзӣёдә’зӢ¬з«ӢпјҢеҗ„иҮӘзӢ¬з«Ӣжӣҙж–°гҖӮд№ҹе°ұжҳҜиҜҙпјҢдёҖж–№жЁЎеһӢжҜҸж¬Ўзҡ„жӣҙж–°йғҪдәҺеҸҰдёҖж–№ж— зӣҙжҺҘзӣҠеӨ„гҖӮеҜ№жӯӨпјҢжңүеӯҰиҖ…жҸҗеҮәиҒ”еҗҲеӣһиҜ‘жі•е’ҢеҜ№еҒ¶еӯҰд№ (dual learning)пјҢеңЁиҝӯд»Ји®ӯз»ғдёӯдҪҝдәҢиҖ…йҡҗеҗ«ең°зӣёдә’еҸ—зӣҠгҖӮдҪҶжҳҜпјҢиҝҷдәӣж–№жі•дёӯзҡ„зҝ»иҜ‘жЁЎеһӢд»Қ然еҗ„иҮӘзӢ¬з«ӢгҖӮзҗҶжғізҠ¶жҖҒдёӢпјҢеҪ“дёӨдёӘж–№еҗ‘зҡ„зҝ»иҜ‘жЁЎеһӢзӣёе…іпјҢеҲҷйқһе№іиЎҢиҜӯж–ҷжүҖеёҰжқҘзҡ„еўһзӣҠиғҪеӨҹиҝӣдёҖжӯҘжҸҗй«ҳгҖӮжӯӨж—¶пјҢдёҖж–№жҜҸдёҖжӯҘзҡ„жӣҙж–°йғҪиғҪеӨҹжҸҗеҚҮеҸҰдёҖж–№зҡ„жҖ§иғҪпјҢеҸҚд№ӢдәҰ然гҖӮиҝҷе°ҶжӣҙеӨ§ең°еҸ‘жҢҘйқһе№іиЎҢиҜӯж–ҷзҡ„ж•Ҳз”ЁгҖӮ
еҜ№дәҺи§Јз ҒпјҢжңүеӯҰиҖ…жҸҗеҮәеңЁзҝ»иҜ‘жЁЎеһӢx->yдёӯзӣҙжҺҘ
жҸ’е…ҘзӢ¬иҮӘеңЁtargetиҜӯз§ҚдёҠи®ӯз»ғзҡ„еӨ–йғЁиҜӯиЁҖжЁЎеһӢгҖӮиҝҷз§Қеј•е…ҘtargetиҜӯз§ҚзҹҘиҜҶзҡ„ж–№жі•зЎ®е®һиғҪеӨҹеҸ–еҫ—жӣҙеҘҪзҡ„зҝ»иҜ‘з»“жһңпјҢзү№еҲ«жҳҜеҜ№дәҺзү№е®ҡйўҶеҹҹгҖӮдҪҶжҳҜпјҢеңЁи§Јз Ғзҡ„ж—¶еҖҷзӣҙжҺҘеј•е…ҘзӢ¬з«ӢиҜӯиЁҖжЁЎеһӢдјјд№ҺдёҚжҳҜжңҖеҘҪзҡ„гҖӮеҺҹеӣ еҰӮдёӢпјҡ
(1)йҮҮз”Ёзҡ„иҜӯиЁҖжЁЎеһӢжқҘиҮӘдәҺеӨ–йғЁпјҢзӢ¬з«ӢдәҺзҝ»иҜ‘жЁЎеһӢзҡ„еӯҰд№ гҖӮиҝҷз§Қз®ҖеҚ•зҡ„
жҸ’е…Ҙж–№ејҸеҸҜиғҪдҪҝеҫ—дёӨдёӘжЁЎеһӢж— жі•иүҜеҘҪеҚҸдҪңпјҢз”ҡиҮіеёҰжқҘеҶІзӘҒпјӣ
(2)иҜӯиЁҖжЁЎеһӢд»…еңЁи§Јз ҒдёӯдҪҝз”ЁпјҢиҖҢи®ӯз»ғиҝҮзЁӢжІЎжңүгҖӮиҝҷеҜјиҮҙи®ӯз»ғе’Ңи§Јз ҒдёҚдёҖиҮҙпјҢеҸҜиғҪдјҡеҪұе“ҚжҖ§иғҪгҖӮ
жң¬ж–ҮжҸҗеҮәй•ңеғҸз”ҹжҲҗејҸNMT(MGNMT)е°қиҜ•и§ЈеҶідёҠиҝ°й—®йўҳпјҢиҝӣиҖҢжӣҙй«ҳж•Ҳең°еҲ©з”Ёйқһе№іиЎҢиҜӯж–ҷгҖӮMGNMTеңЁдёҖдёӘз»ҹдёҖзҡ„жЎҶжһ¶дёӯиҒ”еҗҲзҝ»иҜ‘жЁЎеһӢ(дёӨдёӘж–№еҗ‘)е’ҢиҜӯиЁҖжЁЎеһӢ(дёӨдёӘиҜӯз§Қ)гҖӮеҸ—з”ҹжҲҗејҸNMT(GNMT)зҡ„еҗҜеҸ‘пјҢMGNMTдёӯеј•е…ҘдёҖдёӘеңЁxе’Ңyд№Ӣй—ҙе…ұдә«зҡ„йҡҗиҜӯд№үеҸҳйҮҸzгҖӮжң¬ж–ҮеҲ©з”ЁеҜ№з§°жҖ§жҲ–иҖ…иҜҙй•ңеғҸжҖ§иҙЁжқҘеҲҶи§ЈжқЎд»¶иҒ”еҗҲжҰӮзҺҮp(x, y | z)пјҡ
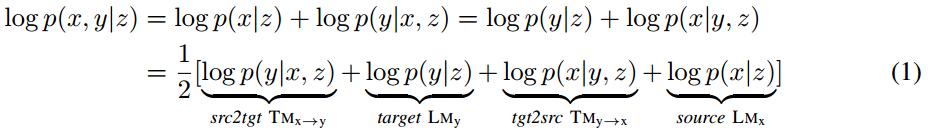
MGNMTзҡ„жҰӮзҺҮеӣҫжЁЎеһӢеҰӮFigure 1жүҖзӨәпјҡ
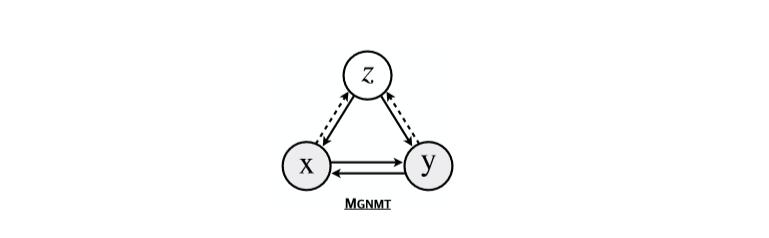
Figure 1пјҡMGNMTзҡ„жҰӮзҺҮеӣҫжЁЎеһӢ
йҖҡиҝҮе…ұдә«зҡ„йҡҗиҜӯд№үеҸҳйҮҸе°ҶдёӨдёӘиҜӯз§Қзҡ„еҸҢеҗ‘зҝ»иҜ‘жЁЎеһӢе’ҢиҜӯиЁҖжЁЎеһӢеҲҶеҲ«еҜ№йҪҗпјҢеҰӮFigure 2жүҖзӨәпјҡ
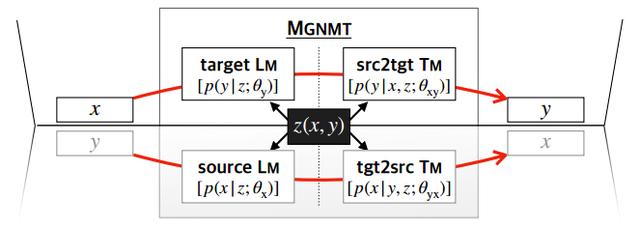
Figure 2пјҡMGNMTзҡ„й•ңеғҸжҖ§иҙЁ
еј•е…ҘйҡҗеҸҳйҮҸеҗҺпјҢе°Ҷеҗ„дёӘжЁЎеһӢе…іиҒ”иө·жқҘпјҢдё”еңЁз»ҷе®ҡzдёӢжқЎд»¶зӢ¬з«ӢгҖӮеҰӮжӯӨзҡ„MGNMTжңүеҰӮдёӢ2дёӘдјҳеҠҝпјҡ
(1)и®ӯз»ғж—¶пјҢз”ұдәҺйҡҗеҸҳйҮҸзҡ„дҪңз”ЁпјҢдёӨдёӘж–№еҗ‘зҡ„зҝ»иҜ‘жЁЎеһӢдёҚеҶҚеҗ„иҮӘзӢ¬з«ӢпјҢиҖҢжҳҜзӣёдә’е…іиҒ”гҖӮеӣ жӯӨдёҖдёӘж–№еҗ‘дёҠзҡ„жӣҙж–°зӣҙжҺҘжңүзӣҠдәҺеҸҰдёҖдёӘж–№еҗ‘зҡ„зҝ»иҜ‘жЁЎеһӢгҖӮиҝҷжҸҗеҚҮдәҶйқһе№іиЎҢиҜӯж–ҷзҡ„еҲ©з”Ёж•ҲзҺҮпјӣ
(2)и§Јз Ғж—¶пјҢMGNMTиғҪеӨҹеӨ©з„¶ең°еҲ©з”Ёе…¶еҶ…йғЁtargetз«Ҝзҡ„иҜӯиЁҖжЁЎеһӢгҖӮиҝҷдёӘиҜӯиЁҖжЁЎеһӢжҳҜдёҺзҝ»иҜ‘жЁЎеһӢиҒ”еҗҲеӯҰд№ зҡ„пјҢиҒ”еҗҲиҜӯиЁҖжЁЎеһӢе’Ңзҝ»иҜ‘жЁЎеһӢжңүеҠ©дәҺиҺ·еҫ—жӣҙеҘҪзҡ„з”ҹжҲҗз»“жһңгҖӮ
е®һйӘҢиЎЁжҳҺMGNMTеңЁе№іиЎҢиҜӯж–ҷдёҠеҸ–еҫ—е…·жңүз«һдәүеҠӣзҡ„з»“жһңпјҢз”ҡиҮіеңЁдёҖдәӣеңәжҷҜе’ҢиҜӯз§ҚеҜ№дёҠ(еҢ…жӢ¬resource-richиҜӯз§ҚгҖҒ resource-poorиҜӯз§Қе’Ңи·ЁйўҶеҹҹзҝ»иҜ‘)дјҳдәҺж•°дёӘеҒҘеЈ®зҡ„еҹәеҮҶжЁЎеһӢгҖӮжӯӨеӨ–иҝҳеҸ‘зҺ°пјҢзҝ»иҜ‘жЁЎеһӢе’ҢиҜӯиЁҖжЁЎеһӢзҡ„иҒ”еҗҲеӯҰд№ зЎ®е®һиғҪеӨҹжҸҗеҚҮMGNMTзҡ„зҝ»иҜ‘иҙЁйҮҸгҖӮжң¬ж–ҮиҝҳиҜҒжҳҺMGNMTжҳҜдёҖз§ҚиҮӘз”ұдҪ“зі»з»“жһ„пјҢеҸҜд»Ҙеә”з”ЁдәҺд»»дҪ•зҘһз»ҸеәҸеҲ—жЁЎеһӢеҰӮ Transformerе’ҢRNNгҖӮ
дёүгҖҒж–№жі•
MGNMTзҡ„ж•ҙдҪ“жЎҶжһ¶еҰӮFigure 3жүҖзӨәпјҡ
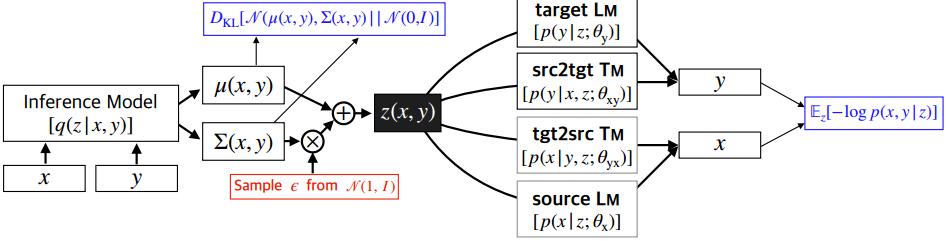
Figure 3пјҡMGNMTзҡ„жЎҶжһ¶зӨәж„Ҹеӣҫ
е…¶дёӯ(x,y)иЎЁзӨәsource-targetиҜӯиЁҖеҜ№пјҢОёиЎЁзӨәжЁЎеһӢеҸӮж•°пјҢD_xy $иЎЁзӨәе№іиЎҢиҜӯж–ҷпјҢD_xе’ҢD_yеҲҶеҲ«иЎЁзӨәеҗ„иҮӘзҡ„йқһе№іиЎҢеҚ•иҜӯиҜӯж–ҷгҖӮ
MGNMTеҜ№еҸҢиҜӯеҸҘеҜ№иҝӣиЎҢиҒ”еҗҲе»әжЁЎпјҢе…·дҪ“жҳҜеҲ©з”ЁиҒ”еҗҲжҰӮзҺҮзҡ„й•ңеғҸжҖ§иҙЁпјҡ

е…¶дёӯйҡҗеҸҳйҮҸz(жң¬ж–ҮйҖүз”Ёж ҮеҮҶй«ҳж–ҜеҲҶеёғ)иЎЁзӨәxе’Ңyд№Ӣй—ҙзҡ„иҜӯд№үе…ұдә«гҖӮйҡҗеҸҳйҮҸжЎҘжҺҘдәҶдёӨдёӘж–№еҗ‘зҡ„зҝ»иҜ‘жЁЎеһӢе’ҢиҜӯиЁҖжЁЎеһӢгҖӮдёӢйқўеҲҶеҲ«д»Ӣз»Қе№іиЎҢиҜӯж–ҷе’Ңйқһе№іиЎҢиҜӯж–ҷзҡ„и®ӯз»ғеҸҠе…¶и§Јз ҒгҖӮ
вҖў е№іиЎҢиҜӯж–ҷзҡ„и®ӯз»ғ
з»ҷе®ҡе№іиЎҢиҜӯж–ҷеҜ№(x,y)пјҢдҪҝз”ЁйҡҸжңәжўҜеәҰеҸҳеҲҶиҙқеҸ¶ж–Ҝжі•(stochastic gradient variational BayesпјҢSGVB)еҫ—еҲ°log p(x,y)зҡ„иҝ‘дјјжңҖеӨ§дјјз„¶дј°и®ЎгҖӮиҝ‘дјјеҗҺйӘҢеҸҜд»ҘеҸӮж•°еҢ–дёәпјҡ
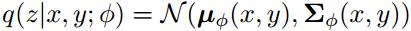
д»Һж–№зЁӢ(1)дёӯеҸҜд»Ҙеҫ—еҮәиҒ”еҗҲжҰӮзҺҮеҜ№ж•°дјјз„¶зҡ„иҜҒжҚ®дёӢз•Ң(Evidence Lower BOundпјҢELBO)пјҡ
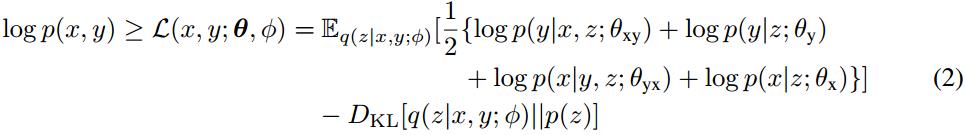
ж–№зЁӢ(2)дёӯ第дёҖйЎ№иЎЁзӨәеҸҘеӯҗеҜ№log似然зҡ„жңҹжңӣпјҢиҜҘжңҹжңӣз”Ёи’ҷзү№еҚЎжҙӣйҮҮж ·иҺ·еҫ—гҖӮ第дәҢйЎ№жҳҜйҡҗеҸҳйҮҸзҡ„иҝ‘дјјеҗҺйӘҢе’Ңе…ҲйӘҢеҲҶеёғд№Ӣй—ҙзҡ„KLж•ЈеәҰгҖӮйҖҡиҝҮйҮҚж–°еҸӮж•°еҢ–зҡ„жҠҖе·§пјҢдҪҝз”ЁеҹәдәҺжўҜеәҰзҡ„з®—жі•иҒ”еҗҲи®ӯз»ғжүҖжңүйғЁеҲҶгҖӮ
вҖў йқһе№іиЎҢиҜӯж–ҷзҡ„и®ӯз»ғ
жң¬ж–ҮеңЁMGNMTдёӯи®ҫи®ЎдёҖз§Қиҝӯд»Ји®ӯз»ғж–№жі•д»ҘеҲ©з”Ёйқһе№іиЎҢиҜӯж–ҷгҖӮеңЁиҜҘи®ӯз»ғиҝҮзЁӢдёӯдёӨдёӘж–№еҗ‘зҡ„зҝ»иҜ‘йғҪиғҪеӨҹеҸ—зӣҠдәҺеҗ„иҮӘзҡ„еҚ•иҜӯз§Қж•°жҚ®йӣҶпјҢдё”иғҪеӨҹзӣёдә’дҝғиҝӣгҖӮйқһе№іиЎҢиҜӯж–ҷдёҠзҡ„и®ӯз»ғж–№жі•еҰӮ Algorithm 1жүҖзӨәпјҡ

з»ҷе®ҡдёӨдёӘйқһе№іиЎҢеҸҘеӯҗпјҡsourceиҜӯз§Қдёӯзҡ„еҸҘеӯҗx^sе’ҢtargetиҜӯз§Қдёӯзҡ„еҸҘеӯҗy^tгҖӮзӣ®ж ҮжҳҜдҪҝе®ғ们зҡ„иҫ№йҷ…еҲҶеёғ似然зҡ„дёӢз•Ңзӣёдә’жңҖеӨ§еҢ–пјҡ
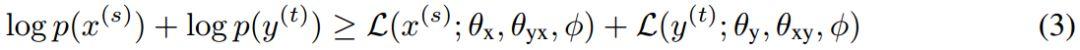
е…¶дёӯе°ҸдәҺзӯүдәҺеҸ·еҸіиҫ№зҡ„дёӨйЎ№еҲҶеҲ«иЎЁзӨәsourceе’Ңtargetзҡ„иҫ№йҷ…еҜ№ж•°дјјз„¶зҡ„дёӢз•ҢгҖӮ
д»ҘдёҠиҝ°з¬¬дәҢйЎ№дёәдҫӢгҖӮз”Ёp(x|y^t)еңЁsourceиҜӯз§ҚдёӯйҮҮж ·еҮәзҡ„xдҪңдёәy^tзҡ„зҝ»иҜ‘з»“жһң(еҚіеӣһиҜ‘)гҖӮеҰӮжӯӨеҸҜд»ҘиҺ·еҫ—дјӘе№іиЎҢеҸҘеӯҗеҜ№(x, y^t)гҖӮеңЁж–№зЁӢ(4)дёӯзӣҙжҺҘз»ҷеҮәиҜҘйЎ№зҡ„иЎЁиҫҫејҸпјҡ
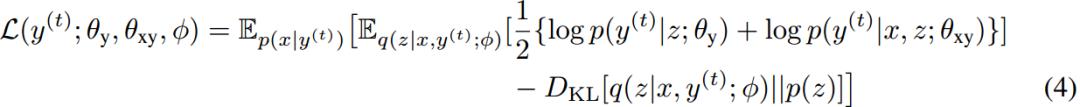
еҗҢзҗҶеҸҜд»Ҙеҫ—еҲ°еҸҰдёҖйЎ№зҡ„иЎЁиҫҫејҸпјҡ
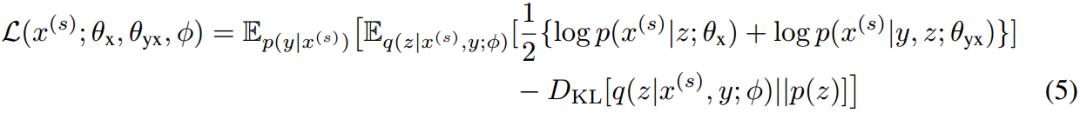
е…·дҪ“зҡ„иҜҒжҳҺиҝҮзЁӢпјҢж„ҹе…ҙи¶Јзҡ„з«ҘйһӢеҸҜд»ҘзңӢеҺҹе§Ӣи®әж–Үзҡ„йҷ„еҪ•гҖӮ
ж №жҚ®дёҠиҝ°дёӨдёӘе…¬ејҸеҸҜд»Ҙеҫ—еҲ°2дёӘж–№еҗ‘зҡ„дјӘе№іиЎҢиҜӯж–ҷпјҢеҶҚе°ҶдәҢиҖ…иҒ”еҗҲиө·жқҘи®ӯз»ғMGNMTгҖӮж–№зЁӢ(3)еҸҜд»Ҙз”ЁеҹәдәҺжўҜеәҰзҡ„ж–№жі•иҝӣиЎҢжӣҙж–°пјҢи®Ўз®—еҰӮж–№зЁӢ(6)жүҖзӨәпјҡ
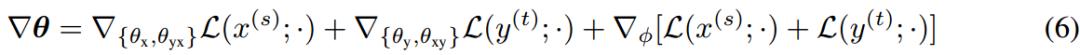
дёҠиҝ°еҲ©з”Ёйқһе№іиЎҢиҜӯж–ҷзҡ„ж•ҙдёӘи®ӯз»ғиҝҮзЁӢеңЁжҹҗз§ҚзЁӢеәҰдёҠдёҺиҒ”еҗҲеӣһиҜ‘зӣёдјјгҖӮдҪҶжҳҜиҒ”еҗҲеӣһиҜ‘жҜҸж¬Ўиҝӯд»ЈеҸӘеҲ©з”Ёйқһе№іиЎҢиҜӯж–ҷзҡ„дёҖдёӘж–№еҗ‘жқҘжӣҙж–°дёҖдёӘж–№еҗ‘зҡ„зҝ»иҜ‘жЁЎеһӢгҖӮз”ұдәҺйҡҗеҸҳйҮҸжқҘиҮӘдәҺе…ұдә«иҝ‘дјјеҗҺйӘҢq(z|x, y;ОҰ)пјҢжүҖд»ҘеҸҜе……еҪ“дҝғиҝӣMGNMTдёӯдёӨдёӘж–№еҗ‘еҚ•иҜӯз§ҚжҖ§иғҪзҡ„жЎҘжўҒгҖӮ
вҖў и§Јз Ғ
MGNMTеңЁи§Јз ҒдёӯеҗҢж—¶еҜ№зҝ»иҜ‘жЁЎеһӢе’ҢиҜӯиЁҖжЁЎеһӢе»әжЁЎпјҢжүҖд»ҘеңЁи§Јз Ғж—¶иғҪеӨҹиҺ·еҫ—жӣҙжөҒз•…жӣҙй«ҳиҙЁйҮҸзҡ„зҝ»иҜ‘з»“жһңгҖӮз»ҷе®ҡеҸҘеӯҗx(жҲ–иҖ…targetеҸҘеӯҗy)пјҢйҖҡиҝҮy=argmax_{y} p(y|x)=argmax_{y} p(x, y)жүҫеҲ°зӣёеә”зҡ„зҝ»иҜ‘з»“жһңгҖӮе…·дҪ“зҡ„и§Јз ҒжөҒзЁӢеҰӮ Algorithm 2жүҖзӨәпјҡ

д»Ҙsrg2tgtзҝ»иҜ‘жЁЎеһӢдёәдҫӢгҖӮеҜ№з»ҷе®ҡзҡ„sourceеҸҘеӯҗxеҒҡеҰӮдёӢж“ҚдҪңпјҡ
(1)д»Һж ҮеҮҶй«ҳж–Ҝе…ҲйӘҢеҲҶеёғдёӯйҮҮж ·дёҖдёӘеҲқе§ӢеҢ–зҡ„йҡҗеҸҳйҮҸzпјҢ然еҗҺеҫ—еҲ°дёҖдёӘеҲқе§Ӣзҝ»иҜ‘y~=arg max_y p(y| x, z);
(2)д»ҺеҗҺйӘҢиҝ‘дјјеҲҶеёғq(z|x, y~; ОҰ)дёҚж–ӯйҮҮж ·йҡҗеҸҳйҮҸпјҢз”Ёbeam searchйҮҚи§Јз Ғд»ҘжңҖеӨ§еҢ–ELBOгҖӮд»ҺиҖҢиҝӯд»Јз”ҹжҲҗy~пјҡ

жҜҸдёӘжӯҘйӘӨзҡ„и§Јз Ғеҫ—еҲҶз”ұx->yзҝ»иҜ‘жЁЎеһӢе’Ңyзҡ„иҜӯиЁҖжЁЎеһӢеҶіе®ҡпјҢиҝҷжңүеҠ©дәҺзҝ»иҜ‘з»“жһңжӣҙеғҸtargetиҜӯз§ҚгҖӮйҮҚе»әзҡ„йҮҚжҺ’еҫ—еҲҶз”ұy->xе’Ңxзҡ„иҜӯиЁҖжЁЎеһӢеҶіе®ҡгҖӮйҮҚжҺ’жҳҜжҢҮзҝ»иҜ‘еҗҺеҜ№еҖҷйҖүзҡ„йҮҚж–°жҺ’еәҸгҖӮеңЁйҮҚжҺ’дёӯеј•е…ҘйҮҚе»әеҫ—еҲҶзЎ®е®һжңүеҠ©дәҺзҝ»иҜ‘ж•Ҳжһңзҡ„жҸҗеҚҮгҖӮ
еӣӣгҖҒе®һйӘҢ
е®һйӘҢж•°жҚ®йӣҶпјҡWMT16 En-RoпјҢIWSLT16 EN-DE, WMT14 EN-DE е’Ң NIST EN-ZHгҖӮ
вҖў MGNMTиғҪжӣҙе……еҲҶең°еҲ©з”Ёйқһе№іиЎҢиҜӯж–ҷ
еҜ№жүҖжңүзҡ„иҜӯиЁҖпјҢдҪҝз”Ёзҡ„йқһе№іиЎҢиҜӯж–ҷеҰӮдёӢTable 1жүҖзӨәпјҡ

Table 1пјҡжҜҸдёӘзҝ»иҜ‘д»»еҠЎж•°жҚ®йӣҶзҡ„з»ҹи®Ўз»“жһң
дёӢйқўдёӨдёӘTableжҳҜжЁЎеһӢеңЁеҗ„дёӘж•°жҚ®йӣҶдёҠзҡ„е®һйӘҢз»“жһңгҖӮеҸҜд»ҘзңӢеҮәпјҢMGNMT+йқһе№іиЎҢиҜӯж–ҷеңЁжүҖжңүе®һйӘҢдёҠеҸ–еҫ—жңҖеҘҪз»“жһңгҖӮ
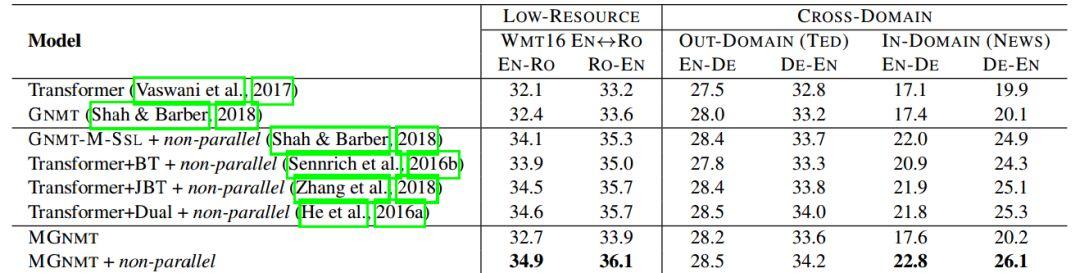
Table 2пјҡеңЁlow-resourceе’Ңи·ЁйўҶеҹҹзҝ»иҜ‘д»»еҠЎдёҠзҡ„BLEUеҫ—еҲҶ
еңЁTable 2дёӯеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢеңЁи·ЁйўҶеҹҹж•°жҚ®йӣҶдёӯдҪҝз”Ёйқһе№іиЎҢиҜӯж–ҷзҡ„MGNMTеҸ–еҫ—дәҶжңҖеҘҪзҡ„з»“жһңгҖӮ
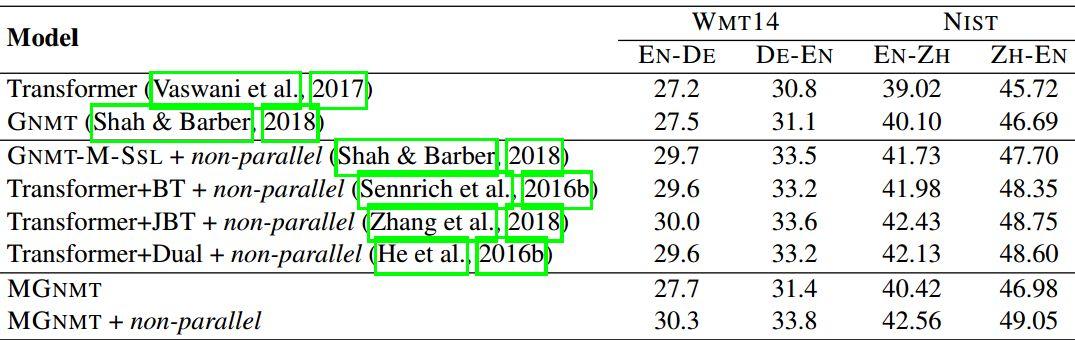
Table 3пјҡresource-richиҜӯз§Қж•°жҚ®йӣҶдёҠзҡ„BLEUеҫ—еҲҶ
з»јеҗҲиҝҷдёӨеј TableпјҢж— и®әжҳҜlow-resourceиҝҳжҳҜresource-richпјҢMG-NMTйғҪиғҪеҸ–еҫ—еҫҲеҘҪзҡ„ж•ҲжһңпјҢе°Өе…¶жҳҜеҠ дәҶйқһе№іиЎҢиҜӯж–ҷд№ӢеҗҺгҖӮ
вҖў MGNMTдёӯеј•е…ҘиҜӯиЁҖжЁЎеһӢжҖ§иғҪжӣҙеҘҪ
Table 4еұ•зӨәеңЁи§Јз Ғдёӯеј•е…ҘиҜӯиЁҖжЁЎеһӢзҡ„еҪұе“ҚгҖӮиЎЁдёӯзҡ„LM-FUSIONиЎЁзӨә
жҸ’е…ҘдёҖдёӘйў„и®ӯз»ғзҡ„иҜӯиЁҖжЁЎеһӢпјҢиҖҢдёҚжҳҜеғҸMG-NMTдёҖж ·дёҖиө·и®ӯз»ғгҖӮеҸҜд»ҘзңӢеҲ°пјҢ常规зӣҙжҺҘ
жҸ’е…ҘLMзҡ„ж•ҲжһңдёҚеҰӮжң¬ж–Үзҡ„ж–№жі•гҖӮ

Table 4пјҡеңЁи§Јз Ғдёӯеј•е…ҘиҜӯиЁҖжЁЎеһӢзҡ„е®һйӘҢз»“жһң
вҖў йқһе№іиЎҢиҜӯж–ҷзҡ„еҪұе“Қ
ж— и®әжҳҜTransformerиҝҳжҳҜMGNMTпјҢйғҪиғҪд»ҺжӣҙеӨҡзҡ„йқһе№іиЎҢиҜӯж–ҷдёӯиҺ·зӣҠпјҢдҪҶжҖ»зҡ„жқҘзңӢпјҢMGNMTд»ҺдёӯжұІеҸ–зҡ„收зӣҠжӣҙеӨ§гҖӮ
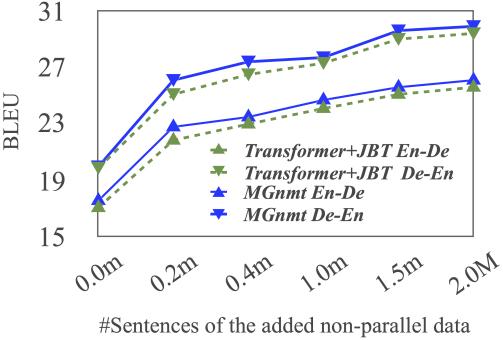
Figure 4пјҡBLEUеҸ—йқһе№іиЎҢиҜӯж–ҷж•°жҚ®йӣҶ规模зҡ„еҪұе“Қ
еҶҚжқҘзңӢзңӢеҸӘз”ЁеҚ•иҜӯйқһе№іиЎҢиҜӯж–ҷжҳҜеҗҰд№ҹеҗҢж—¶жңүеҠ©дәҺMGNMTдёӨдёӘж–№еҗ‘дёҠзҡ„зҝ»иҜ‘гҖӮд»Һе®һйӘҢз»“жһңеҸҜд»ҘзңӢеҲ°пјҢеҸӘж·»еҠ еҚ•иҜӯйқһе№іиЎҢиҜӯж–ҷпјҢжЁЎеһӢзҡ„BLEUеҖјзЎ®е®һеҫ—еҲ°жҸҗеҚҮгҖӮиҝҷиҜҙжҳҺиҝҷдёӨдёӘж–№еҗ‘зҡ„зҝ»иҜ‘жЁЎеһӢзҡ„зЎ®зӣёдә’дҝғиҝӣгҖӮ
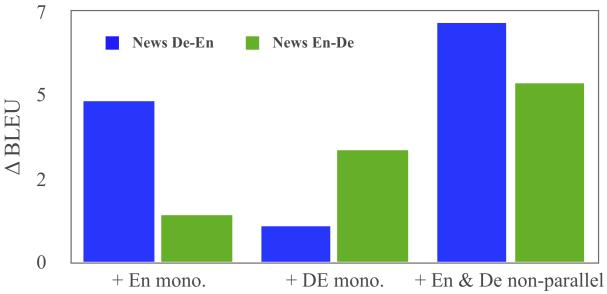
Figure 5пјҡеҚ•иҜӯйқһе№іиЎҢиҜӯж–ҷеҜ№BLEUзҡ„еҪұе“Қ
дә”гҖҒжҖ»з»“
жң¬ж–ҮжҸҗеҮәдәҶдёҖдёӘй•ңеғҸз”ҹжҲҗејҸзҡ„жңәеҷЁзҝ»иҜ‘жЁЎеһӢMGNMTд»Ҙжӣҙй«ҳж•Ҳең°еҲ©з”Ёйқһе№іиЎҢиҜӯж–ҷгҖӮ
иҜҘжЁЎеһӢйҖҡиҝҮдёҖдёӘе…ұдә«еҸҢиҜӯйҡҗиҜӯд№үз©әй—ҙеҜ№еҸҢеҗ‘зҝ»иҜ‘жЁЎеһӢе’Ңеҗ„иҮӘзҡ„иҜӯиЁҖжЁЎеһӢиҝӣиЎҢиҒ”еҗҲеӯҰд№ гҖӮеңЁMGNMTдёӯдёӨдёӘзҝ»иҜ‘ж–№еҗ‘йғҪеҸҜеҗҢж—¶еҸ—зӣҠдәҺйқһе№іиЎҢиҜӯж–ҷгҖӮжӯӨеӨ–пјҢMGNMTеңЁи§Јз Ғж—¶еӨ©з„¶еҲ©з”ЁеӯҰд№ еҲ°зҡ„targetиҜӯиЁҖжЁЎеһӢпјҢиҝҷиғҪзӣҙжҺҘжҸҗеҚҮзҝ»иҜ‘иҙЁйҮҸгҖӮе®һйӘҢиҜҒжҳҺжң¬ж–ҮMGNMTеңЁеҗ„дёӘиҜӯз§Қзҝ»иҜ‘еҜ№дёӯйғҪдјҳдәҺе…¶д»–ж–№жі•гҖӮ
вҖў жңӘжқҘж–№еҗ‘
жңӘжқҘзҡ„з ”з©¶ж–№еҗ‘пјҢжҳҜиҰҒе°ҶMGNMTз”ЁдәҺе®Ңе…Ёж— зӣ‘зқЈжңәеҷЁзҝ»иҜ‘дёӯгҖӮ
AAAI 2020 и®әж–ҮйӣҶпјҡ
AAAI 2020 и®әж–Үи§ЈиҜ»дјҡ @ жңӣдә¬пјҲйҷ„PPT
дёӢиҪҪпјү
AAAI 2020 и®әж–Үи§ЈиҜ»зі»еҲ—пјҡ
01. [дёӯ科йҷўиҮӘеҠЁеҢ–жүҖ] йҖҡиҝҮиҜҶеҲ«е’Ңзҝ»иҜ‘дәӨдә’жү“йҖ жӣҙдјҳзҡ„иҜӯйҹізҝ»иҜ‘жЁЎеһӢ
02. [дёӯ科йҷўиҮӘеҠЁеҢ–жүҖ] е…Ёж–°и§Ҷи§’пјҢжҺўз©¶гҖҢзӣ®ж ҮжЈҖжөӢгҖҚдёҺгҖҢе®һдҫӢеҲҶеүІгҖҚзҡ„дә’жғ е…ізі»
03. [еҢ—зҗҶе·Ҙ] ж–°и§’еәҰзңӢеҸҢзәҝжҖ§жұ еҢ–пјҢеҶ—дҪҷгҖҒзӘҒеҸ‘жҖ§й—®йўҳжң¬иҙЁжәҗдәҺе“ӘйҮҢпјҹ
04. [еӨҚж—ҰеӨ§еӯҰ] еҲ©з”ЁеңәжҷҜеӣҫй’ҲеҜ№еӣҫеғҸеәҸеҲ—иҝӣиЎҢж•…дәӢз”ҹжҲҗ
05. [и…ҫи®Ҝ AI Lab] 2100еңәзҺӢиҖ…иҚЈиҖҖпјҢ1v1иғңзҺҮ99.8%пјҢи…ҫи®Ҝз»қжӮҹ AI жҠҖжңҜи§ЈиҜ»
06. [еӨҚж—ҰеӨ§еӯҰ] еӨҡд»»еҠЎеӯҰд№ пјҢеҰӮдҪ•и®ҫи®ЎдёҖдёӘжӣҙеҘҪзҡ„еҸӮж•°е…ұдә«жңәеҲ¶пјҹ
07. [жё…еҚҺеӨ§еӯҰ] иҜқеҲ°еҳҙиҫ№еҚҙеҝҳдәҶпјҹиҝҷдёӘжЁЎеһӢиғҪеё®дҪ | еӨҡйҖҡйҒ“еҸҚеҗ‘иҜҚе…ёжЁЎеһӢ
08. [еҢ—иҲӘзӯү] DualVDпјҡдёҖз§Қи§Ҷи§үеҜ№иҜқж–°жЎҶжһ¶
09. [жё…еҚҺеӨ§еӯҰ] еҖҹеҠ©BabelNetжһ„е»әеӨҡиҜӯиЁҖд№үеҺҹзҹҘиҜҶеә“
10. [еҫ®иҪҜдәҡз ”] жІҹеЈ‘жҳ“еЎ«пјҡз«ҜеҲ°з«ҜиҜӯйҹізҝ»иҜ‘дёӯйў„и®ӯз»ғе’Ңеҫ®и°ғзҡ„иЎ”жҺҘж–№жі•
11. [еҫ®иҪҜдәҡз ”] ж—¶й—ҙеҸҜд»ҘжҳҜдәҢз»ҙзҡ„еҗ—пјҹеҹәдәҺдәҢз»ҙж—¶й—ҙеӣҫзҡ„и§Ҷйў‘еҶ…е®№зүҮж®өжЈҖжөӢ
12. [жё…еҚҺеӨ§еӯҰ] з”ЁдәҺе°‘ж¬Ўе…ізі»еӯҰд№ зҡ„зҘһз»ҸзҪ‘з»ңйӣӘзҗғжңәеҲ¶
13. [дёӯ科йҷўиҮӘеҠЁеҢ–жүҖ] йҖҡиҝҮи§Јзә зј жЁЎеһӢжҺўжөӢиҜӯд№үе’ҢиҜӯжі•зҡ„еӨ§и„‘иЎЁеҫҒжңәеҲ¶
14. [дёӯ科йҷўиҮӘеҠЁеҢ–жүҖ] еӨҡжЁЎжҖҒеҹәеҮҶжҢҮеҜјзҡ„з”ҹжҲҗејҸеӨҡжЁЎжҖҒиҮӘеҠЁж–Үж‘ҳ
15. [еҚ—дә¬еӨ§еӯҰ] еҲ©з”ЁеӨҡеӨҙжіЁж„ҸеҠӣжңәеҲ¶з”ҹжҲҗеӨҡж ·жҖ§зҝ»иҜ‘
16. [UCSB зҺӢеЁҒе»үз»„] йӣ¶ж ·жң¬еӯҰд№ пјҢжқҘжү©е……зҹҘиҜҶеӣҫи°ұпјҲи§Ҷйў‘и§ЈиҜ»пјү





