дҪңиҖ…пјҡArseny Kravchenko
зј–иҜ‘пјҡronghuaiyang
еҜјиҜ»
з»ҷеӨ§е®¶жҖ»з»“дәҶ8дёӘи®Ўз®—жңәи§Ҷи§үж·ұеәҰеӯҰд№ дёӯзҡ„еёёи§ҒbugпјҢзӣёдҝЎеӨ§е®¶жҲ–еӨҡжҲ–е°‘йғҪйҒҮеҲ°иҝҮпјҢеёҢжңӣиғҪеё®еҠ©еӨ§е®¶йҒҝе…ҚдёҖдәӣй—®йўҳгҖӮ
дәәжҳҜдёҚе®ҢзҫҺзҡ„пјҢжҲ‘们з»ҸеёёеңЁиҪҜ件дёӯзҠҜй”ҷиҜҜгҖӮжңүж—¶иҝҷдәӣй”ҷиҜҜеҫҲе®№жҳ“еҸ‘зҺ°пјҡдҪ зҡ„д»Јз Ғж №жң¬дёҚиғҪе·ҘдҪңпјҢдҪ зҡ„еә”з”ЁзЁӢеәҸеҙ©жәғзӯүзӯүгҖӮдҪҶжҳҜжңүдәӣbugжҳҜйҡҗи—Ҹзҡ„пјҢиҝҷдҪҝеҫ—е®ғ们жӣҙеҠ еҚұйҷ©гҖӮ
еңЁи§ЈеҶіж·ұеәҰеӯҰд№ й—®йўҳж—¶пјҢз”ұдәҺдёҖдәӣдёҚзЎ®е®ҡжҖ§пјҢеҫҲе®№жҳ“еҮәзҺ°иҝҷз§Қзұ»еһӢзҡ„bugпјҡеҫҲе®№жҳ“зңӢеҲ°webеә”з”ЁзЁӢеәҸи·Ҝз”ұиҜ·жұӮжҳҜеҗҰжӯЈзЎ®пјҢиҖҢдёҚе®№жҳ“жЈҖжҹҘдҪ зҡ„жўҜеәҰдёӢйҷҚжӯҘйӘӨжҳҜеҗҰжӯЈзЎ®гҖӮ然иҖҢпјҢжңүеҫҲеӨҡй”ҷиҜҜжҳҜеҸҜд»ҘйҒҝе…Қзҡ„гҖӮ
жҲ‘жғіеҲҶдә«дёҖдәӣжҲ‘зҡ„з»ҸйӘҢпјҢе…ідәҺжҲ‘еңЁиҝҮеҺ»дёӨе№ҙзҡ„и®Ўз®—жңәи§Ҷи§үе·ҘдҪңдёӯзңӢеҲ°жҲ–еҲ¶йҖ зҡ„й”ҷиҜҜгҖӮжҲ‘(еңЁдјҡи®®дёҠ)и°ҲеҲ°иҝҮиҝҷдёӘиҜқйўҳ(https://datafest.ru/ia/)пјҢеҫҲеӨҡдәәеңЁдјҡеҗҺе‘ҠиҜүжҲ‘пјҡвҖңжҳҜзҡ„пјҢжҲ‘д№ҹжңүеҫҲеӨҡиҝҷж ·зҡ„bugгҖӮвҖқжҲ‘еёҢжңӣжҲ‘зҡ„ж–Үз« еҸҜд»Ҙеё®еҠ©дҪ иҮіе°‘йҒҝе…Қе…¶дёӯзҡ„дёҖдәӣй—®йўҳгҖӮ
1. зҝ»иҪ¬еӣҫзүҮд»ҘеҸҠе…ій”®зӮ№.
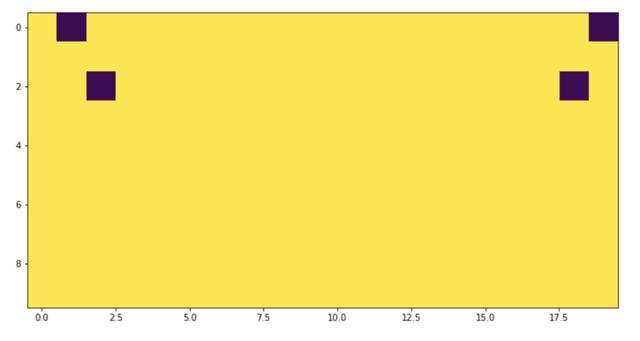
еҒҮи®ҫеңЁе…ій”®зӮ№жЈҖжөӢзҡ„й—®йўҳдёҠгҖӮж•°жҚ®зңӢиө·жқҘеғҸдёҖеҜ№еӣҫеғҸе’ҢдёҖзі»еҲ—зҡ„е…ій”®зӮ№е…ғз»„гҖӮе…¶дёӯжҜҸдёӘе…ій”®зӮ№жҳҜдёҖеҜ№xе’Ңyеқҗж ҮгҖӮ
и®©жҲ‘们еҜ№иҝҷдёӘж•°жҚ®иҝӣиЎҢеҹәзЎҖзҡ„еўһејәпјҡ
def flip_img_and_keypoints(img: np.ndarray, kpts: Sequence[Sequence[int]]):
img = np.fliplr(img)
h, w, *_ = img.shape
kpts = [(y, w - x) for y, x in kpts]
return img, kpts
зңӢиө·жқҘжҳҜжӯЈзЎ®зҡ„пјҢе—ҜпјҹжҲ‘们жҠҠе®ғеҸҜи§ҶеҢ–гҖӮ
image = np.ones((10, 10), dtype=np.float32)
kpts = [(0, 1), (2, 2)]
image_flipped, kpts_flipped = flip_img_and_keypoints(image, kpts)
img1 = image.copy()
for y, x in kpts:
img1[y, x] = 0
img2 = image_flipped.copy()
for y, x in kpts_flipped:
img2[y, x] = 0
_ = plt.imshow(np.hstack((img1, img2)))
дёҚеҜ№з§°пјҢзңӢиө·жқҘеҫҲеҘҮжҖӘпјҒеҰӮжһңжҲ‘们жЈҖжҹҘжһҒеҖје‘ўпјҹ
image = np.ones((10, 10), dtype=np.float32)
дёҚеҘҪпјҒиҝҷжҳҜдёҖдёӘе…ёеһӢзҡ„off-by-oneй”ҷиҜҜгҖӮжӯЈзЎ®зҡ„д»Јз ҒжҳҜиҝҷж ·зҡ„:
def flip_img_and_keypoints(img: np.ndarray, kpts: Sequence[Sequence[int]]):
img = np.fliplr(img)
h, w, *_ = img.shape
kpts = [(y, w - x - 1) for y, x in kpts]
return img, kpts
жҲ‘们йҖҡиҝҮеҸҜи§ҶеҢ–еҸ‘зҺ°дәҶиҝҷдёӘй—®йўҳпјҢдҪҶжҳҜпјҢдҪҝз”ЁвҖңx = 0вҖқзӮ№иҝӣиЎҢеҚ•е…ғжөӢиҜ•д№ҹдјҡжңүжүҖеё®еҠ©гҖӮдёҖдёӘжңүи¶Јзҡ„дәӢе®һжҳҜпјҡжңүдёҖдёӘеӣўйҳҹдёӯжңүдёүдёӘдәә(еҢ…жӢ¬жҲ‘иҮӘе·ұ)зӢ¬з«Ӣең°зҠҜдәҶеҮ д№ҺзӣёеҗҢзҡ„й”ҷиҜҜгҖӮ
2. 继з»ӯжҳҜе…ій”®зӮ№зӣёе…ізҡ„й—®йўҳ
еҚідҪҝеңЁдёҠйқўзҡ„еҮҪж•°иў«дҝ®еӨҚд№ӢеҗҺпјҢд»Қ然еӯҳеңЁеҚұйҷ©гҖӮзҺ°еңЁжӣҙеӨҡзҡ„жҳҜиҜӯд№үпјҢиҖҢдёҚд»…д»…жҳҜдёҖж®өд»Јз ҒгҖӮ
еҒҮи®ҫйңҖиҰҒз”ЁдёӨеҸӘжүӢжҺҢжқҘеўһејәеӣҫеғҸгҖӮзңӢиө·жқҘеҫҲе®үе…ЁпјҡжүӢжҳҜе·ҰпјҢеҸізҝ»иҪ¬гҖӮ
дҪҶжҳҜзӯүзӯүпјҒжҲ‘们еҜ№е…ій”®зӮ№зҡ„иҜӯд№ү并дёҚеҫҲдәҶи§ЈгҖӮеҰӮжһңиҝҷдёӘе…ій”®зӮ№зҡ„ж„ҸжҖқжҳҜиҝҷж ·зҡ„пјҡ
kpts = [
(20, 20), # left pinky
(20, 200), # right pinky
...
]
иҝҷж„Ҹе‘ізқҖеўһејәе®һйҷ…дёҠж”№еҸҳдәҶиҜӯд№үпјҡе·ҰеҸҳжҲҗеҸіпјҢеҸіеҸҳжҲҗе·ҰпјҢдҪҶжҲ‘们дёҚдәӨжҚўж•°з»„дёӯзҡ„е…ій”®зӮ№зҙўеј•гҖӮе®ғдјҡз»ҷи®ӯз»ғеёҰжқҘеӨ§йҮҸзҡ„еҷӘйҹіе’Ңжӣҙзіҹзі•зҡ„еәҰйҮҸгҖӮ
жҲ‘们еә”иҜҘеҗёеҸ–дёҖдёӘж•ҷи®ӯпјҡ
-
еңЁеә”з”ЁеўһејәжҲ–е…¶д»–иҠұе“Ёзҡ„еҠҹиғҪд№ӢеүҚпјҢдәҶ解并иҖғиҷ‘ж•°жҚ®з»“жһ„е’ҢиҜӯд№ү
-
дҝқжҢҒдҪ зҡ„е®һйӘҢеҺҹеӯҗжҖ§пјҡж·»еҠ дёҖдёӘе°Ҹзҡ„еҸҳеҢ–(дҫӢеҰӮдёҖдёӘж–°зҡ„еҸҳжҚў)пјҢжЈҖжҹҘе®ғеҰӮдҪ•иҝӣиЎҢпјҢеҰӮжһңеҲҶж•°жҸҗй«ҳжүҚеҠ иҝӣеҺ»гҖӮ
3. зј–еҶҷиҮӘе·ұзҡ„жҚҹеӨұеҮҪж•°
зҶҹжӮүиҜӯд№үеҲҶеүІй—®йўҳзҡ„дәәеҸҜиғҪзҹҘйҒ“IoUжҢҮж ҮгҖӮдёҚе№ёзҡ„жҳҜпјҢжҲ‘们дёҚиғҪзӣҙжҺҘз”ЁSGDжқҘдјҳеҢ–е®ғпјҢжүҖд»Ҙеёёз”Ёзҡ„ж–№жі•жҳҜз”ЁеҸҜеҫ®жҚҹеӨұеҮҪж•°жқҘиҝ‘дјје®ғгҖӮ
def iou_continuous_loss(y_pred, y_true):
eps = 1e-6
def _sum(x):
return x.sum(-1).sum(-1)
numerator = (_sum(y_true * y_pred) + eps)
denominator = (_sum(y_true ** 2) + _sum(y_pred ** 2)
- _sum(y_true * y_pred) + eps)
return (numerator / denominator).mean()
зңӢиө·жқҘдёҚй”ҷпјҢжҲ‘们е…ҲеҒҡдёӘе°Ҹзҡ„жЈҖжҹҘпјҡ
In [3]: 3, 10, 10))
...: x1 = iou_continuous_loss(ones * 0.01, ones)
...: x2 = iou_continuous_loss(ones * 0.99, ones)
In [4]: x1, x2
Out[4]: (0.010099999897990103, 0.9998990001020204)
еңЁ x1дёӯпјҢжҲ‘们计算дәҶдёҖдәӣдёҺground truthе®Ңе…ЁдёҚеҗҢзҡ„дёңиҘҝзҡ„жҚҹеӨұпјҢиҖҢ x2еҲҷжҳҜйқһеёёжҺҘиҝ‘ground truthзҡ„дёңиҘҝзҡ„з»“жһңгҖӮжҲ‘们预计 x1дјҡеҫҲеӨ§пјҢеӣ дёәйў„жөӢжҳҜй”ҷиҜҜзҡ„пјҢ x2еә”иҜҘжҺҘиҝ‘дәҺйӣ¶гҖӮжҖҺд№ҲдәҶ?
дёҠйқўзҡ„еҮҪж•°жҳҜеҜ№metricзҡ„дёҖдёӘеҫҲеҘҪзҡ„иҝ‘дјјгҖӮmetricдёҚжҳҜдёҖз§ҚжҚҹеӨұпјҡе®ғйҖҡеёё(еҢ…жӢ¬иҝҷз§Қжғ…еҶө)и¶Ҡй«ҳи¶ҠеҘҪгҖӮеҪ“жҲ‘们дҪҝз”ЁSGDжқҘжңҖе°ҸеҢ–жҚҹеӨұж—¶пјҢжҲ‘们еә”иҜҘдҪҝз”ЁдёҖдәӣзӣёеҸҚзҡ„дёңиҘҝпјҡ
def iou_continuous(y_pred, y_true):
eps = 1e-6
def _sum(x):
return x.sum(-1).sum(-1)
numerator = (_sum(y_true * y_pred) + eps)
denominator = (_sum(y_true ** 2) + _sum(y_pred ** 2)
- _sum(y_true * y_pred) + eps)
return (numerator / denominator).mean()
def iou_continuous_loss(y_pred, y_true):
return 1 - iou_continuous(y_pred, y_true)
иҝҷдәӣй—®йўҳеҸҜд»Ҙд»ҺдёӨдёӘж–№йқўжқҘзЎ®е®ҡпјҡ
-
зј–еҶҷдёҖдёӘеҚ•е…ғжөӢиҜ•пјҢжЈҖжҹҘжҚҹеӨұзҡ„ж–№еҗ‘пјҡеҪўејҸеҢ–зҡ„жңҹжңӣпјҢжӣҙжҺҘиҝ‘ground truthеә”иҜҘиҫ“еҮәжӣҙдҪҺзҡ„жҚҹеӨұгҖӮ
-
иҝҗиЎҢдёҖдёӘеҒҘе…Ёзҡ„жЈҖжҹҘпјҢи®©дҪ зҡ„жЁЎеһӢеңЁеҚ•дёӘbatchдёӯиҝҮжӢҹеҗҲгҖӮ
4. еҪ“жҲ‘们дҪҝз”ЁPytorchзҡ„ж—¶еҖҷ
еҒҮи®ҫжңүдёҖдёӘйў„е…Ҳи®ӯз»ғеҘҪзҡ„жЁЎеһӢпјҢејҖе§ӢеҒҡinferгҖӮ
from ceevee.base import AbstractPredictor
class MySuperPredictor(AbstractPredictor):
def __init__(self,
weights_path: str,
):
super().__init__()
self.model = self._load_model(weights_path=weights_path)
def process(self, x, *kw):
with torch.no_grad():
res = self.model(x)
return res
@staticmethod
def _load_model(weights_path):
model = ModelClass()
weights = torch.load(weights_path, map_location='cpu')
model.load_state_dict(weights)
return model
иҝҷдёӘд»Јз ҒжӯЈзЎ®еҗ—пјҹд№ҹи®ёпјҒиҝҷзЎ®е®һйҖӮз”ЁдәҺжҹҗдәӣжЁЎеһӢгҖӮдҫӢеҰӮпјҢеҪ“жЁЎеһӢжІЎжңүdropoutжҲ–normеұӮпјҢеҰӮ torch.nn.BatchNorm2dгҖӮжҲ–иҖ…еҪ“жЁЎеһӢйңҖиҰҒдёәжҜҸдёӘеӣҫеғҸдҪҝз”Ёе®һйҷ…зҡ„normз»ҹи®ЎйҮҸж—¶(дҫӢеҰӮпјҢи®ёеӨҡеҹәдәҺpix2pixзҡ„жһ¶жһ„йңҖиҰҒе®ғ)гҖӮ
дҪҶжҳҜеҜ№дәҺеӨ§еӨҡж•°и®Ўз®—жңәи§Ҷи§үеә”з”ЁзЁӢеәҸжқҘиҜҙпјҢд»Јз ҒеҝҪз•ҘдәҶдёҖдәӣйҮҚиҰҒзҡ„дёңиҘҝ:еҲҮжҚўеҲ°иҜ„дј°жЁЎејҸгҖӮ
еҰӮжһңиҜ•еӣҫе°ҶеҠЁжҖҒPyTorchеӣҫиҪ¬жҚўдёәйқҷжҖҒPyTorchеӣҫпјҢиҝҷдёӘй—®йўҳеҫҲе®№жҳ“иҜҶеҲ«гҖӮ torch.jitз”ЁдәҺиҝҷз§ҚиҪ¬жҚўгҖӮ
In [3]: model = nn.Sequential(
...: nn.Linear(10, 10),
...: nn.Dropout(.5)
...: )
...:
...: traced_model = torch.jit.trace(model, torch.rand(10))
/Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/jit/__init__.py:914: TracerWarning: Trace had nondeterministic nodes. Did you forget call .eval() on your model? Nodes:
%12 : Float(10) = aten::dropout(%input, %10, %11), scope: Sequential/Dropout[1] # /Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/nn/functional.py:806:0
This may cause errors in trace checking. To disable trace checking, pass check_trace=False to torch.jit.trace()
check_tolerance, _force_outplace, True, _module_class)
/Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/jit/__init__.py:914: TracerWarning: Output nr 1. of the traced function does not match the corresponding output of the Python function. Detailed error:
Not within tolerance rtol=1e-05 atol=1e-05 at input[5] (0.0 vs. 0.5454154014587402) and 5 other locations (60.00%)
check_tolerance, _force_outplace, True, _module_class)
з®ҖеҚ•зҡ„дҝ®еӨҚдёҖдёӢпјҡ
In [4]: model = nn.Sequential(
...: nn.Linear(10, 10),
...: nn.Dropout(.5)
...: )
...:
...: traced_model = torch.jit.trace(model.eval(), torch.rand(10))
# No more warnings!
еңЁиҝҷз§Қжғ…еҶөдёӢпјҢ torch.jit.traceе°ҶжЁЎеһӢиҝҗиЎҢеҮ 次并жҜ”иҫғз»“жһңгҖӮиҝҷйҮҢзҡ„е·®еҲ«жҳҜеҸҜз–‘зҡ„гҖӮ
然иҖҢ torch.jit.traceеңЁиҝҷйҮҢдёҚжҳҜдёҮиғҪиҚҜгҖӮиҝҷжҳҜдёҖз§Қеә”иҜҘзҹҘйҒ“е’Ңи®°дҪҸзҡ„з»Ҷеҫ®е·®еҲ«гҖӮ
5. еӨҚеҲ¶зІҳиҙҙзҡ„й—®йўҳ
еҫҲеӨҡдёңиҘҝйғҪжҳҜжҲҗеҜ№еӯҳеңЁзҡ„пјҡи®ӯз»ғе’ҢйӘҢиҜҒгҖҒе®ҪеәҰе’Ңй«ҳеәҰгҖҒзә¬еәҰе’Ңз»ҸеәҰвҖҰвҖҰ
def make_dataloaders(train_cfg, val_cfg, batch_size):
train = Dataset.from_config(train_cfg)
val = Dataset.from_config(val_cfg)
shared_params = {'batch_size': batch_size, 'shuffle': True, 'num_workers': cpu_count()}
train = DataLoader(train, **shared_params)
val = DataLoader(train, **shared_params)
return train, val
дёҚд»…д»…жҳҜжҲ‘зҠҜдәҶж„ҡи ўзҡ„й”ҷиҜҜгҖӮдҫӢеҰӮпјҢеңЁйқһеёёжөҒиЎҢзҡ„albumentationsеә“д№ҹжңүдёҖдёӘзұ»дјјзҡ„зүҲжң¬гҖӮ
# https://github.com/albu/albumentations/blob/0.3.0/albumentations/augmentations/transforms.py
def apply_to_keypoint(self, keypoint, crop_height=0, crop_width=0, h_start=0, w_start=0, rows=0, cols=0, **params):
keypoint = F.keypoint_random_crop(keypoint, crop_height, crop_width, h_start, w_start, rows, cols)
scale_x = self.width / crop_height
scale_y = self.height / crop_height
keypoint = F.keypoint_scale(keypoint, scale_x, scale_y)
return keypoint
еҲ«жӢ…еҝғпјҢе·Із»Ҹдҝ®ж”№еҘҪдәҶгҖӮ
еҰӮдҪ•йҒҝе…ҚпјҹдёҚиҰҒеӨҚеҲ¶е’ҢзІҳиҙҙд»Јз ҒпјҢе°ҪйҮҸд»ҘдёҚйңҖиҰҒеӨҚеҲ¶е’ҢзІҳиҙҙзҡ„ж–№ејҸзј–еҶҷд»Јз ҒгҖӮ
datasets = []
data_a = get_dataset(MyDataset(config['dataset_a']), config['shared_param'], param_a)
datasets.append(data_a)
data_b = get_dataset(MyDataset(config['dataset_b']), config['shared_param'], param_b)
datasets.append(data_b)
datasets = []
for name, param in zip(('dataset_a', 'dataset_b'),
(param_a, param_b),
):
datasets.append(get_dataset(MyDataset(config[name]), config['shared_param'], param))
6. еҗҲйҖӮзҡ„ж•°жҚ®зұ»еһӢ
и®©жҲ‘们编еҶҷдёҖдёӘж–°зҡ„еўһејә
def add_noise(img: np.ndarray) -> np.ndarray:
mask = np.random.rand(*img.shape) + .5
img = img.astype('float32') * mask
return img.astype('uint8')
еӣҫеғҸе·Іиў«жӣҙж”№гҖӮиҝҷжҳҜжҲ‘们жүҖжңҹжңӣзҡ„еҗ—?е—ҜпјҢд№ҹи®ёе®ғж”№еҸҳеҫ—еӨӘеӨҡдәҶгҖӮ
иҝҷйҮҢжңүдёҖдёӘеҚұйҷ©зҡ„ж“ҚдҪңпјҡе°Ҷ float32 иҪ¬жҚўдёә uint8гҖӮе®ғеҸҜиғҪдјҡеҜјиҮҙжәўеҮәпјҡ
def add_noise(img: np.ndarray) -> np.ndarray:
mask = np.random.rand(*img.shape) + .5
img = img.astype('float32') * mask
return np.clip(img, 0, 255).astype('uint8')
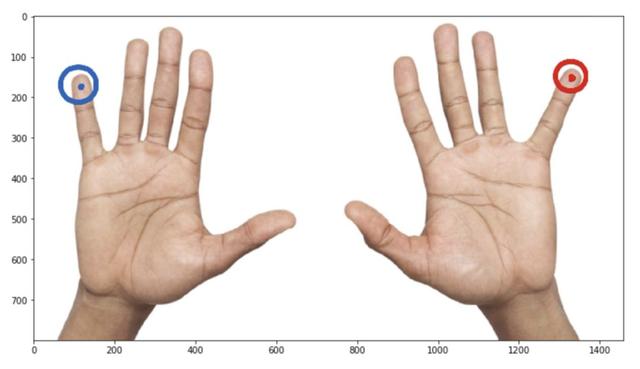
img = add_noise(cv2.imread('two_hands.jpg')[:, :, ::-1])
_ = plt.imshow(img)
зңӢиө·жқҘеҘҪеӨҡдәҶпјҢжҳҜеҗ§пјҹ
йЎәдҫҝиҜҙдёҖеҸҘпјҢиҝҳжңүдёҖз§Қж–№жі•еҸҜд»ҘйҒҝе…ҚиҝҷдёӘй—®йўҳпјҡдёҚиҰҒйҮҚж–°еҸ‘жҳҺиҪ®еӯҗпјҢдёҚиҰҒд»ҺеӨҙејҖе§Ӣзј–еҶҷеўһејәд»Јз Ғ并дҪҝз”ЁзҺ°жңүзҡ„жү©еұ•пјҡ albumentations.augmentations.transforms.GaussNoiseгҖӮ
жҲ‘жӣҫз»ҸеҒҡиҝҮеҸҰдёҖдёӘеҗҢж ·иө·жәҗзҡ„bugгҖӮ
raw_mask = cv2.imread('mask_small.png')
mask = raw_mask.astype('float32') / 255
mask = cv2.resize(mask, (64, 64), interpolation=cv2.INTER_LINEAR)
mask = cv2.resize(mask, (128, 128), interpolation=cv2.INTER_CUBIC)
mask = (mask * 255).astype('uint8')
_ = plt.imshow(np.hstack((raw_mask, mask)))
иҝҷйҮҢеҮәдәҶд»Җд№Ҳй—®йўҳпјҹйҰ–е…ҲпјҢз”Ёдёүж¬ЎжҸ’еҖји°ғж•ҙжҺ©жЁЎзҡ„еӨ§е°ҸжҳҜдёҖдёӘеқҸдё»ж„ҸгҖӮеҗҢж ·зҡ„й—®йўҳ float32еҲ° uint8пјҡдёүж¬ЎжҸ’еҖјеҸҜд»Ҙиҫ“еҮәеҖјеӨ§дәҺиҫ“е…ҘпјҢиҝҷдјҡеҜјиҮҙжәўеҮәгҖӮ
жҲ‘еңЁеҒҡеҸҜи§ҶеҢ–зҡ„ж—¶еҖҷеҸ‘зҺ°дәҶиҝҷдёӘй—®йўҳгҖӮеңЁдҪ зҡ„и®ӯз»ғеҫӘзҺҜдёӯеҲ°еӨ„ж”ҫзҪ®ж–ӯиЁҖд№ҹжҳҜдёҖдёӘеҘҪдё»ж„ҸгҖӮ
7. жӢјеҶҷй”ҷиҜҜ
еҒҮи®ҫйңҖиҰҒеҜ№е…ЁеҚ·з§ҜзҪ‘з»ң(еҰӮиҜӯд№үеҲҶеүІй—®йўҳ)е’ҢдёҖдёӘе·ЁеӨ§зҡ„еӣҫеғҸиҝӣиЎҢжҺЁзҗҶгҖӮиҜҘеӣҫеғҸжҳҜеҰӮжӯӨе·ЁеӨ§пјҢжІЎжңүжңәдјҡжҠҠе®ғж”ҫеңЁдҪ зҡ„GPUдёӯпјҢе®ғеҸҜд»ҘжҳҜдёҖдёӘеҢ»з–—жҲ–еҚ«жҳҹеӣҫеғҸгҖӮ
еңЁиҝҷз§Қжғ…еҶөдёӢпјҢеҸҜд»Ҙе°ҶеӣҫеғҸеҲҶеүІжҲҗзҪ‘ж јпјҢзӢ¬з«Ӣең°еҜ№жҜҸдёҖеқ—иҝӣиЎҢжҺЁзҗҶпјҢжңҖеҗҺеҗҲ并гҖӮжӯӨеӨ–пјҢдёҖдәӣйў„жөӢдәӨеҸүеҸҜиғҪжңүеҠ©дәҺе№іж»‘иҫ№з•Ңйҷ„иҝ‘зҡ„artifactsгҖӮ
from tqdm import tqdm
class GridPredictor:
"""
This class can be used to predict a segmentation mask for the big image
when you have GPU memory limitation
"""
def __init__(self, predictor: AbstractPredictor, size: int, stride: Optional[int] = None):
self.predictor = predictor
self.size = size
self.stride = stride if stride is not None else size // 2
def __call__(self, x: np.ndarray):
h, w, _ = x.shape
mask = np.zeros((h, w, 1), dtype='float32')
weights = mask.copy()
for i in tqdm(range(0, h - 1, self.stride)):
for j in range(0, w - 1, self.stride):
a, b, c, d = i, min(h, i + self.size), j, min(w, j + self.size)
patch = x[a:b, c:d, :]
mask[a:b, c:d, :] += np.expand_dims(self.predictor(patch), -1)
weights[a:b, c:d, :] = 1
return mask / weights
жңүдёҖдёӘз¬ҰеҸ·иҫ“е…Ҙй”ҷиҜҜпјҢд»Јз Ғж®өи¶іеӨҹеӨ§пјҢеҸҜд»ҘеҫҲе®№жҳ“ең°жүҫеҲ°е®ғгҖӮжҲ‘жҖҖз–‘д»…д»…йҖҡиҝҮд»Јз Ғе°ұиғҪеҝ«йҖҹиҜҶеҲ«е®ғгҖӮдҪҶжҳҜеҫҲе®№жҳ“жЈҖжҹҘд»Јз ҒжҳҜеҗҰжӯЈзЎ®пјҡ
class Model(nn.Module):
def forward(self, x):
return x.mean(axis=-1)
model = Model()
grid_predictor = GridPredictor(model, size=128, stride=64)
simple_pred = np.expand_dims(model(img), -1)
grid_pred = grid_predictor(img)
np.testing.assert_allclose(simple_pred, grid_pred, atol=.001)
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-24-a72034c717e9> in <module>
9 grid_pred = grid_predictor(img)
10
---> 11 np.testing.assert_allclose(simple_pred, grid_pred, atol=.001)
~/.pyenv/versions/3.6.6/lib/python3.6/site-packages/numpy/testing/_private/utils.py in assert_allclose(actual, desired, rtol, atol, equal_nan, err_msg, verbose)
1513 header = 'Not equal to tolerance rtol=%g, atol=%g' % (rtol, atol)
1514 assert_array_compare(compare, actual, desired, err_msg=str(err_msg),
-> 1515 verbose=verbose, header=header, equal_nan=equal_nan)
1516
1517
~/.pyenv/versions/3.6.6/lib/python3.6/site-packages/numpy/testing/_private/utils.py in assert_array_compare(comparison, x, y, err_msg, verbose, header, precision, equal_nan, equal_inf)
839 verbose=verbose, header=header,
840 names=('x', 'y'), precision=precision)
--> 841 raise AssertionError(msg)
842 except ValueError:
843 import traceback
AssertionError:
Not equal to tolerance rtol=1e-07, atol=0.001
Mismatch: 99.6%
Max absolute difference: 765.
Max relative difference: 0.75000001
x: array([[[215.333333],
[192.666667],
[250. ],...
y: array([[[ 215.33333],
[ 192.66667],
[ 250. ],...
дёӢйқўжҳҜ __call__ж–№жі•зҡ„жӯЈзЎ®зүҲжң¬:
def __call__(self, x: np.ndarray):
h, w, _ = x.shape
mask = np.zeros((h, w, 1), dtype='float32')
weights = mask.copy()
for i in tqdm(range(0, h - 1, self.stride)):
for j in range(0, w - 1, self.stride):
a, b, c, d = i, min(h, i + self.size), j, min(w, j + self.size)
patch = x[a:b, c:d, :]
mask[a:b, c:d, :] += np.expand_dims(self.predictor(patch), -1)
weights[a:b, c:d, :] += 1
return mask / weights
еҰӮжһңдҪ д»Қ然дёҚзҹҘйҒ“й—®йўҳеҮәеңЁе“ӘйҮҢпјҢиҜ·жіЁж„Ҹ weights[a:b,c:d,:]+=1иҝҷдёҖиЎҢгҖӮ
8. ImagenetеҪ’дёҖеҢ–
еҪ“дёҖдёӘдәәйңҖиҰҒиҝӣиЎҢиҪ¬з§»еӯҰд№ ж—¶пјҢз”Ёи®ӯз»ғImagenetж—¶зҡ„ж–№жі•е°ҶеӣҫеғҸеҪ’дёҖеҢ–йҖҡеёёжҳҜдёҖдёӘеҘҪдё»ж„ҸгҖӮ
и®©жҲ‘们дҪҝз”ЁжҲ‘们已з»ҸзҶҹжӮүзҡ„albumentationsеә“гҖӮ
from albumentations import Normalize
norm = Normalize()
img = cv2.imread('img_small.jpg')
mask = cv2.imread('mask_small.png', cv2.IMREAD_GRAYSCALE)
mask = np.expand_dims(mask, -1) # shape (64, 64) -> shape (64, 64, 1)
normed = norm(image=img, mask=mask)
img, mask = [normed[x] for x in ['image', 'mask']]
def img_to_batch(x):
x = np.transpose(x, (2, 0, 1)).astype('float32')
return torch.from_numpy(np.expand_dims(x, 0))
img, mask = map(img_to_batch, (img, mask))
criterion = F.binary_cross_entropy
зҺ°еңЁжҳҜж—¶еҖҷи®ӯз»ғдёҖдёӘзҪ‘з»ң并еҜ№еҚ•дёӘеӣҫеғҸиҝӣиЎҢиҝҮеәҰжӢҹеҗҲдәҶвҖ”вҖ”жӯЈеҰӮжҲ‘жүҖжҸҗеҲ°зҡ„пјҢиҝҷжҳҜдёҖз§ҚеҫҲеҘҪзҡ„и°ғиҜ•жҠҖжңҜпјҡ
model_a = UNet(3, 1)
optimizer = torch.optim.Adam(model_a.parameters(), lr=1e-3)
losses = []
for t in tqdm(range(20)):
loss = criterion(model_a(img), mask)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
_ = plt.plot(losses)
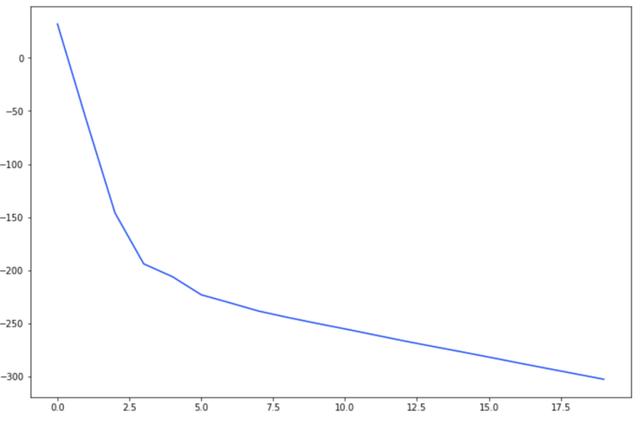
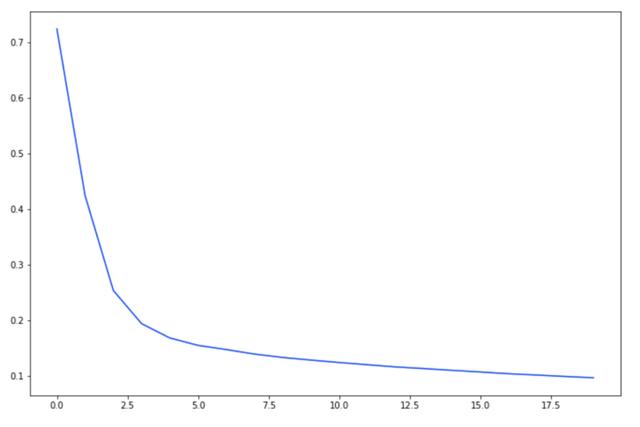
жӣІзҺҮзңӢиө·жқҘеҫҲеҘҪпјҢдҪҶжҳҜдәӨеҸүзҶөзҡ„жҚҹеӨұеҖј-300жҳҜдёҚеҸҜйў„ж–ҷзҡ„гҖӮжҳҜд»Җд№Ҳй—®йўҳпјҹ
еҪ’дёҖеҢ–еӨ„зҗҶеӣҫеғҸж•ҲжһңеҫҲеҘҪпјҢдҪҶжҳҜmaskжІЎжңүпјҡйңҖиҰҒжүӢеҠЁзј©ж”ҫеҲ° [0,1]гҖӮ
model_b = UNet(3, 1)
optimizer = torch.optim.Adam(model_b.parameters(), lr=1e-3)
losses = []
for t in tqdm(range(20)):
loss = criterion(model_b(img), mask / 255.)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
_ = plt.plot(losses)
и®ӯз»ғеҫӘзҺҜзҡ„з®ҖеҚ•иҝҗиЎҢж—¶ж–ӯиЁҖ(дҫӢеҰӮ assertmask.max()<=1дјҡеҫҲеҝ«жЈҖжөӢеҲ°й—®йўҳгҖӮеҗҢж ·пјҢд№ҹеҸҜд»ҘжҳҜеҚ•е…ғжөӢиҜ•гҖӮ
жҖ»з»“
-
жөӢиҜ•еҫҲжңүеҝ…иҰҒ
-
иҝҗиЎҢж—¶ж–ӯиЁҖеҸҜд»Ҙз”ЁдәҺи®ӯз»ғзҡ„pipeline;
-
еҸҜи§ҶеҢ–жҳҜдёҖз§Қе№ёзҰҸ
-
еӨҚеҲ¶зІҳиҙҙжҳҜдёҖз§ҚиҜ…е’’
-
жІЎжңүд»Җд№ҲжҳҜзҒөдё№еҰҷиҚҜпјҢдёҖдёӘжңәеҷЁеӯҰд№ е·ҘзЁӢеёҲеҝ…йЎ»жҖ»жҳҜе°Ҹеҝғ(жҲ–еҸӘжҳҜеҸ—иӢҰ)гҖӮ
иӢұж–ҮеҺҹж–Үпјҡhttps://medium.com/@arseny_info/8-deep-learning-computer-vision-bugs-and-how-i-could-have-avoided-them-d40b0e4b1da