分布式集群如何实现使用Kafka多节点搭建?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
多节点分布式集群结构如下图所示:
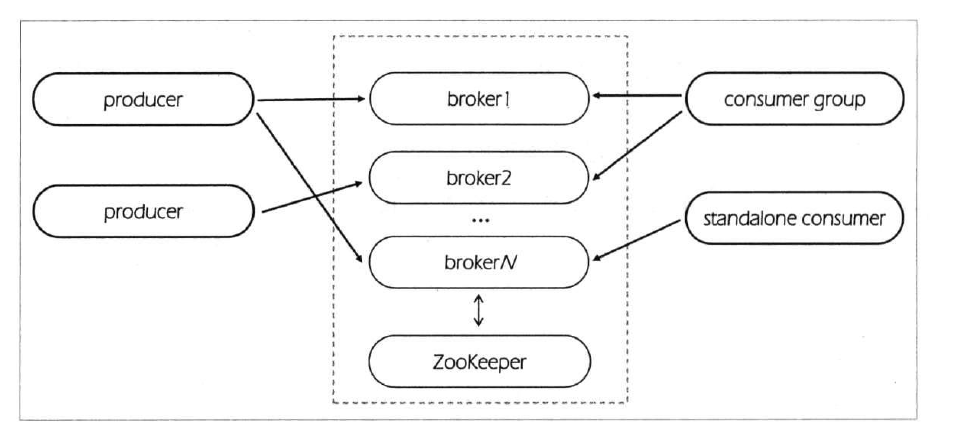
为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建。
一、安装Jdk
具体安装步骤可参考linux安装jdk。
二、安装与配置zookeeper
下载地址:https://www-us.apache.org/dist/zookeeper/stable/
下载二进制压缩包zookeeper-3.4.14.tar.gz,然后上传到linux服务器指定目录下,本次上传目录为/software,然后执行如下命令安装:
cd /software
tar -zxvf zookeeper-3.4.14.tar.gz
mv zookeeper-3.4.14 /usr/local/zookeeper
cd /usr/local/zookeeper/conf
mv zoo_sample.cfg zoo1.cfg
编辑zoo1.cfg,配置相关参数如下:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/usr/local/zookeeper/data/zookeeper1
clientPort=2181
server.1=192.168.184.128:2888:3888
server.2=192.168.184.128:2889:3889
server.3=192.168.184.128:2890:3890
其中:
tickTime:Zookeeper最小的时间单位,用于丈量心跳和超时时间,一般设置默认值2秒;
initLimit:指定follower节点初始时连接leader节点的最大tick此处,设置为5,表示follower必须在5xtickTime即10秒内连接上leader,否则视为超时;
syncLimit:设定follower节点与leader节点进行同步的最大时间,设置为2,表示最大时间为2xtickTime即4秒时间;
dataDir:Zookeeper会在内存中保存系统快照,并定期写入该路径指定的文件夹中,生产环境需要特别注意该文件夹的磁盘占用情况;
clientPort:Zookeeper监听客户端连接的端口号,默认为2181,同一服务器上不同实例之间应该有所区别;
server.X=host:port1:port2:此处X的取值范围在1~255之间,必须是全局唯一的且和myid文件中的数字对应(myid文件后面说明),host是各个节点的主机名,port1通常是2888,用于使follower节点连接leader节点,port2通常是3888,用于leader选举,zookeeper在不同服务器上的时候,不同zookeeper服务器的端口号可以重复,在同一台服务器上的时候需要有所区别。
1.配置zoo.cfg文件
单节点安装zookeeper的时候,仅有一份zoo.cfg文件,多节点安装的时候,每个zookeeper服务器就应该有一个zoo.cfg配置文件。如果在一台服务器安装zookeeper多实例集群,则需要在conf目录下分别配置每个实例的zoo.cfg,同时创建每个zookeeper实例自己的数据存储目录。本次在一台服务器上配置多个zookeeper实例,执行如下命令创建数据存储目录并复制配置文件:
mkdir -p /usr/local/zookeeper/data/zookeeper1
mkdir -p /usr/local/zookeeper/data/zookeeper2
mkdir -p /usr/local/zookeeper/data/zookeeper3
cd /usr/local/zookeeper/conf/
cp zoo1.cfg zoo2.cfg
cp zoo1.cfg zoo3.cfg
复制后分别修改zoo2.cfg,zoo3.cfg中的配置,修改后的配置如下:
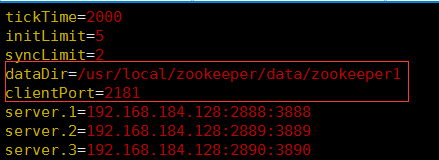
zoo1.cfg的配置如下:
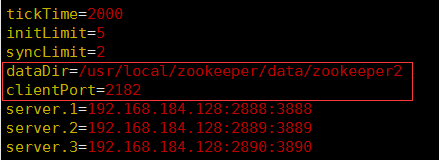
zoo2.cfg的配置如下:
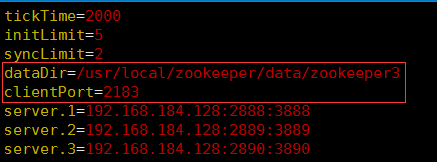
zoo3.cfg中的配置如下:
2.myid文件创建与配置
前面提到zoo.cfg文件中的server.X中的X应该与myid中的数字相对应。除此之外,myid文件必须存放在每个zookeeper实例的data目录下,对应本次安装应该位于/usr/local/zookeeper/data/zookeeper1,2,3目录下,执行如下命令进行配置:
echo '1' > /usr/local/zookeeper/data/zookeeper1/myid
echo '2' > /usr/local/zookeeper/data/zookeeper2/myid
echo '3' > /usr/local/zookeeper/data/zookeeper3/myid
3.启动zookeeper服务器
使用如下命令启动zookeeper集群:
cd /usr/local/zookeeper/bin/
./zkServer.sh start ../conf/zoo1.cfg
./zkServer.sh start ../conf/zoo2.cfg
./zkServer.sh start ../conf/zoo3.cfg
启动后,使用如下命令查看集群状态:
cd /usr/local/zookeeper/bin/
./zkServer.sh status ../conf/zoo1.cfg./zkServer.sh status ../conf/zoo2.cfg./zkServer.sh status ../conf/zoo3.cfg
回显信息如下:

可以看到有两个follower节点,一个leader节点。
三、安装与配置kafka集群
下载地址:http://kafka.apache.org/downloads.html
1.数据目录和配置文件创建
目前最新版本是2.2.0,本次下载2.1.1版本的安装包,然后上传压缩包到服务器指定目录,本次上传目录为/software,然后执行以下命令进行安装:
tar -zxvf kafka_2.12-2.1.1.tgz
mv kafka_2.12-2.1.1 /usr/local/kafka
mkdir -p /usr/local/kafka/logs/kafka1
mkdir -p /usr/local/kafka/logs/kafka2
mkdir -p /usr/local/kafka/logs/kafka3
cd /usr/local/kafka/config/
mv server.properties server1.properties
通过执行上面的命令,我们在/usr/local/kafka/logs文件夹中创建了kafka1,kafka2,kafka3三个文件夹用于存放三个kafka实例的数据,同时将/usr/local/kafka/config/文件夹下的server.properties重命名为server1.properties用于配置kafka的第一个实例。
2.配置属性文件
接下来配置server1.properties文件,主要配置参数如下:
broker.id=1:设置kafka broker的id,本次分别为1,2,3;
delete.topic.enable=true:开启删除topic的开关;
listeners=PLAINTEXT://192.168.184.128:9092:设置kafka的监听地址和端口号,本次分别设置为9092,9093,9094;
log.dirs=/usr/local/kafka/logs/kafka1:设置kafka日志数据存储路径;
zookeeper.connect=192.168.184.128:2181,192.168.184.128:2182,192.168.184.128:2183:设置kafka连接的zookeeper访问地址,集群环境需要配置所有zookeeper的访问地址;
unclean.leader.election.enable=false:为true则代表允许选用非isr列表的副本作为leader,那么此时就意味着数据可能丢失,为false的话,则表示不允许,直接抛出NoReplicaOnlineException异常,造成leader副本选举失败。
zookeeper.connection.timeout.ms=6000:设置连接zookeeper服务器超时时间为6秒。
配置完成后,复制server1.properties两份分别用于配置kafka的第二个,第三个节点:
修改修改其中的broker.id 以及listeners、log.dirs的配置为第二个,第三个节点的配置,最终各个配置文件配置如下:
server1.properties配置:

server2.properties配置:

server3.properties配置:

3.启动kafka
通过如下命令启动kafka集群:
cd /usr/local/kafka/bin/
./kafka-server-start.sh -daemon ../config/server1.properties
./kafka-server-start.sh -daemon ../config/server2.properties
./kafka-server-start.sh -daemon ../config/server3.properties
使用java的命令jps来查看kafka进程:jps |grep -i kafka
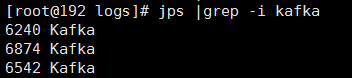
说明kafak启动正常,至此kafka集群搭建完成。本次使用一台服务器作为演示,如果需要在多个服务器上配置集群,配置方法和以上类似,只是不需要像上面那样配置多个数据目录和配置文件,每台服务器的配置保持相同,并且注意在防火墙配置端口号即可。
最后,如果需要远程访问kafka集群,则需要在防火墙中开通9092、9093、9094端口的访问权限。
四、测试
1.topic创建与删除
首先创建一个测试topic,名为testTopic,为了充分利用3个实例(服务器节点),创建3个分区,每个分区都分配3个副本,命令如下:
cd /usr/local/kafka/bin/
./kafka-topics.sh --zookeeper 192.168.184.128:2181 192.168.184.128:2182 192.168.184.128:2183 --create --topic testTopic --partitions 3 --replication-factor 3
回显Created topic "testTopic".则表明testTopic创建成功。执行如下命令进行验证并查看testTopic的信息:
./kafka-topics.sh --zookeeper 192.168.184.128:2181 192.168.184.128:2182 192.168.184.128:2183 --list testTopic
./kafka-topics.sh --zookeeper 192.168.184.128:2181 192.168.184.128:2182 192.168.184.128:2183 --describe --topic testTopic
以上几条命令回显信息如下:

接下来测试topic删除,使用如下命令进行删除:
./kafka-topics.sh --zookeeper 192.168.184.128:2181 192.168.184.128:2182 192.168.184.128:2183 --delete --topic testTopic
执行该条命令后,回显信息如下:

可以看到,testTopic已经被标记为删除,同时第二行提示表明当配置了delete.topic.enable属性为true的时候topic才会删除,否则将不会被删除,本次安装的时候该属性设置的值为true。
2.测试消息发送与消费
首先使用第一步topic创建命令,先创建testTopic这个topic,然后进行消息发送与消费测试。
控制台测试消息发送与消费需要使用kafka的安装目录/usr/local/kafka/bin下的kafka-console-producer.sh来发送消息,使用kafka-console-consumer.sh来消费消息。因此本次打开两个控制台,一个用于执行kafka-console-producer.sh来发送消息,另一个用于执行kafka-console-consumer.sh来消费消息。
消息发送端命令:
cd /usr/local/kafka/bin
./kafka-console-producer.sh --broker-list 192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 --topic testTopic
消息接收端命令:
cd /usr/local/kafka/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 --topic testTopic --from-beginning
当发送端和接收端都登录后,在发送端输入需要发送的消息并回车,在接收端可以看到刚才发送的消息:
发送端:

接收端:

以上就是简单地生产消息与消费消息的测试,在测试消费消息的时候时候,命令里边加了个参数--from-beginning表示接收该topic从创建开始的所有消息。
3.生产者吞吐量测试
对于任何一个消息引擎而言,吞吐量是一个至关重要的性能指标。对于Kafka而言,它的吞吐量指每秒能够处理的消息数或者字节数。kafka为了提高吞吐量,采用追加写入方式将消息写入操作系统的页缓存,读取的时候从页缓存读取,因此它不直接参与物理I/O操作,同时使用以sendfile为代表的零拷贝技术进行数据传输提高效率。
kafka提供了kafka-producer-perf-test.sh脚本用于测试生产者吞吐量,使用如下命令启动测试:
cd /usr/local/kafka/bin
./kafka-producer-perf-test.sh --topic testTopic --num-records 50000 --record-size 200 --throughput -1 --producer-props bootstrap.servers=192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 acks=-1

以上回显信息表明这台服务器上每个producer每秒能发送6518个消息,平均吞吐量是1.24MB/s,平均延迟2.035秒,最大延迟3.205秒,平均有50%的消息发送需要2.257秒,95%的消息发送需要3.076秒,99%的消息发送需要3.171秒,99.9%的消息发送需要3.205秒。
4.消费者吞吐量测试
与生产者吞吐量测试类似,kafka提供了kafka-consumer-perf-test.sh脚本用于消费者吞吐量测试,可以执行以下命令进行测试:
cd /usr/local/kafka/bin
./kafka-consumer-perf-test.sh --broker-list 192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 --messages 50000 --topic testTopic

以上是测试50万条消息的consumer吞吐量,结果表明该consumer在1秒总共消费了9.5366MB消息。
看完上述内容,你们掌握分布式集群如何实现使用Kafka多节点搭建的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





