小编给大家分享一下怎么用python爬虫中的xpath抓取信息,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
我们使用xpath语法来提取我们所需的信息。 不熟悉xpath语法的自行学习一下,很快就能上手,难度不高。 首先我们在chrome浏览器里进入豆瓣电影TOP250页面并按F12打开开发者工具。
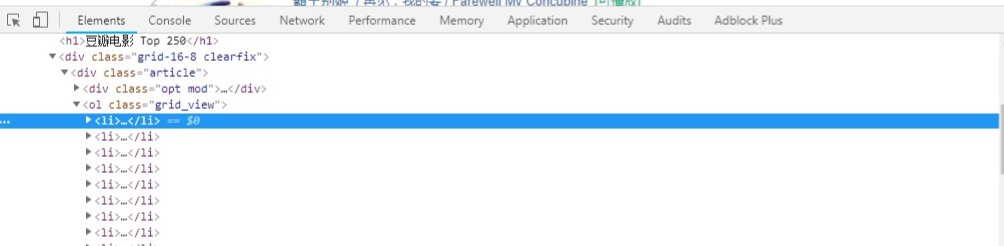
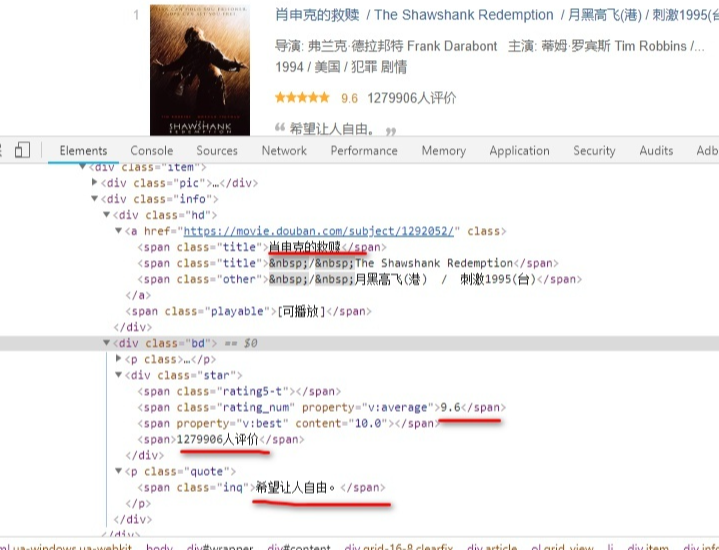
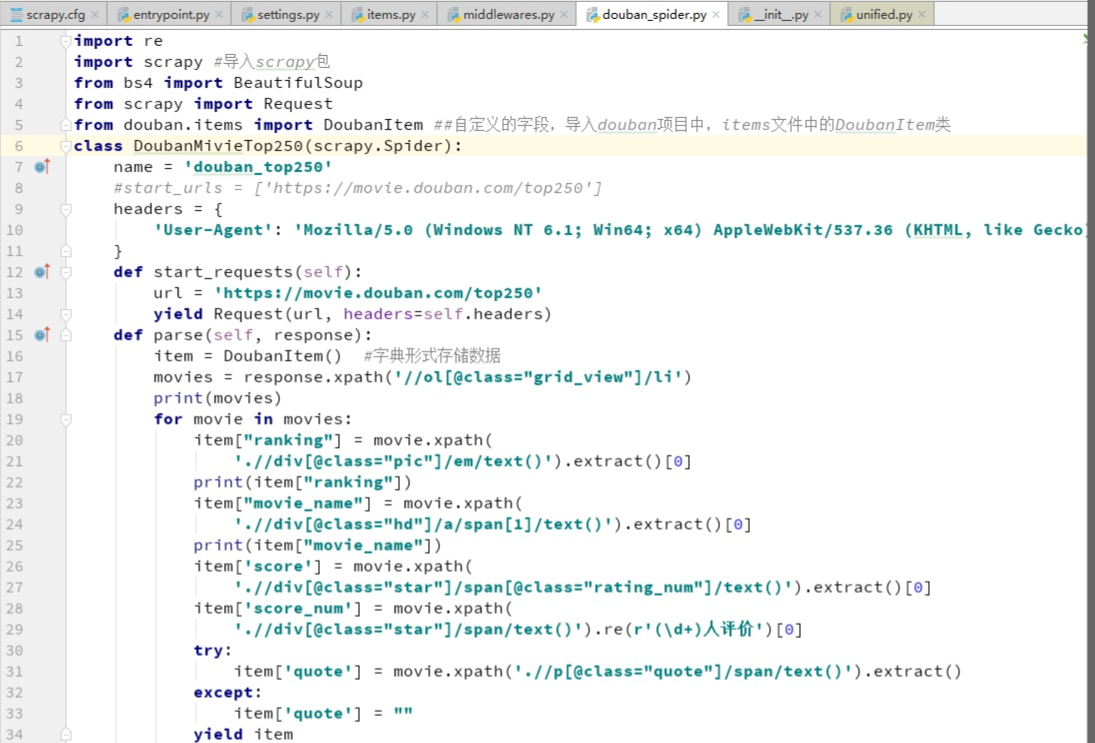
我们可以看到每一部电影的信息都在一个<li>...<li>里,打开后可以找到我们想要的全部信息,其中spider中初始的request是通过调用 start_requests() 来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request。看一下代码:
以上是怎么用python爬虫中的xpath抓取信息的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





