这篇文章主要介绍python爬虫中如何使用header,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。
对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
谷歌或者火狐浏览器,在网页面上点击:右键–检查;点击更多工具-开发者工具;直接F12亦可。然后再按Fn+F5刷新出网页来显示元素
有的浏览器是点击:右键->查看元素,刷新
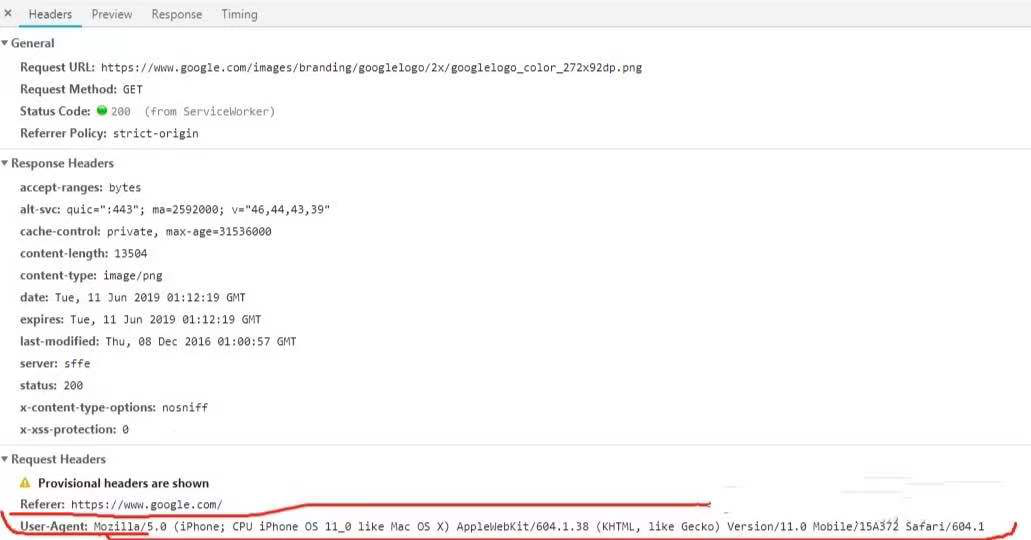
注意:headers中有很多内容,主要常用的就是user-agent 和 host,他们是以键对的形式展现出来,如果user-agent 以字典键对形式作为headers的内容,就可以反爬成功,就不需要其他键对;否则,需要加入headers下的更多键对形式。
import urllib2
import urllib
values={"username":"xxxx","password":"xxxxx"}
data=urllib.urlencode(values)
url= "https://ssl.gstatic.com/gb/images/v2_730ffe61.png"
user_agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1"
referer='http://www.google.com/'
headers={"User-Agent":user_agent,'Referer':referer}
request=urllib2.Request(url,data,headers)
response=urllib2.urlopen(request)
print response.read()以上是“python爬虫中如何使用header”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





