小编给大家分享一下python怎么通过文本文件限制爬虫,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
我们最近讲过的一些限制爬虫方法,都需要自己手动输入代码进行调试。根据我们学过的插件安装,是不是在python爬虫中也有类似简便的办法,能轻松地起到阻拦的作用呢?小编想说有一种文本文件的方法正好符合python初学者的安装需求,接下来我们就robots.txt进行简单介绍以及其限制爬虫的方法。
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots.txt协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。注意robots.txt是用字符串比较来确定是否获取URL,所以目录末尾有与没有斜杠“/”表示的是不同的URL。robots.txt允许使用类似"Disallow: *.gif"这样的通配符。
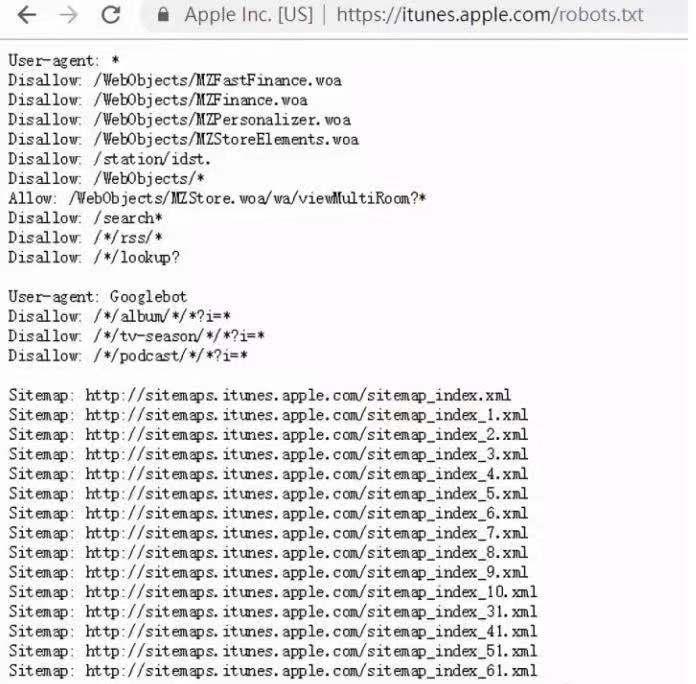
itunes的robots.txt
缺点:
只是一个君子协议,对于良好的爬虫比如搜索引擎有效果,对于有目的性的爬虫不起作用
以上是“python怎么通过文本文件限制爬虫”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





