这篇文章主要介绍scrapy怎么在python分布式爬虫中构建?,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
Scrapy
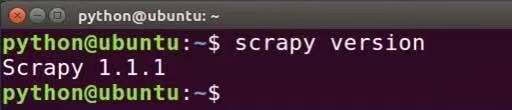
在Ubuntu安装Scrapy的步骤为:打开终端 >> 在终端输入命令:pip install scrapy >> 在终端输入命令:scrapy version >> 成功输出 Scrapy版本号则证明成功安装。
各模块作用
1. items
爬虫抓取数据的工作实际上是从非结构化数据(网页)中提取出结构化数据。虽然Scrapy框架爬虫可以将提取到的数据以Python字典 的形式返回,但是由于Python字典缺少结构,所以很容易发生返回数据不一致亦或者名称拼写的错误,若是Scrapy爬虫项目中包含复 数以上的爬虫则发生错误的机率将更大。因此,Scrapy框架提供了一个items模块来定义公共的输出格式,其中的Item对象是一个用于 收集Scrapy爬取的数据的简单容器。
2. Downloader Middleware
Downloader Middleware是一个Scrapy能全局处理Response和Request的、微型的系统。Downloader Middleware中定义的Downloader Middleware设有优先级顺序,优先级数字越低,则优先级越高,越先执行。在本次分布式爬虫中,我们定义了两个Downloader Middleware,一个用于随机选择爬虫程序执行时的User-Agent,一个用于随机选择爬虫程序执行时的IP地址。
3. settings
settings模块用于用户自定义Scrapy框架中Pipeline、Middleware、Spider等所有组件的所有动作,且可自定义变量或者日志动作。
以上是“scrapy怎么在python分布式爬虫中构建?”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





