这篇文章主要介绍“讲解linux关于正则表达式grep”,在日常操作中,相信很多人在讲解linux关于正则表达式grep问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”讲解linux关于正则表达式grep”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工具。类似于生活中常见的寻人启示,通过描述一个人的特征来进行“搜索匹配”
如今正则已经被我们广泛应用,目前被集成到了各种文本编辑器/文本处理工具当中
应用场景**验证: **表单提交时,进行用户名密码验证。**查找: **从大量信息中快速提取指定内容。在一批url中,查找指定url替换: 将指定格式的文本,进行正则匹配查找,找到之后进行特定替换,(vim文本替换等)
在很多技术领域(比如,自然语言处理,数据存储等),正则表达式可以很方便的提取出我们想要的信息,所以这部分必不可少构成基本要素字符类数量限定符位置限定符特殊符号
1. 字符类:
| 字符 | 说明 | 举例 |
|---|---|---|
| . | 匹配任意的一个字符 | abc. 可以匹配abcd、abc0等 |
| [] | 匹配 [] 内的任意一个字符 | [012]a可以匹配0a、1a、2a |
| - | 在括号内表示字符范围 | 如[0-9]可以匹配任何一个数字 |
| ^ | 放在[]内前面表示匹配除括号中字符外的任意一个字符 | [^ab]c可以匹配1c、dc,但是不能匹配ac、bc |
| [[:xxx:]] | grep工具预定义的一些命名字符类 | [[:digit:]]可以匹配一个数字,[[:alpha:]]匹配一个字符,[[:lower:]]匹配任何一个小写字母等 |
应用:
grep使用--color选项将匹配的字符串以红色标注出来Linux下可以用echo $?来打印上一条命令执行的退出码,为0表示执行成功,1表示失败。
实验如下:
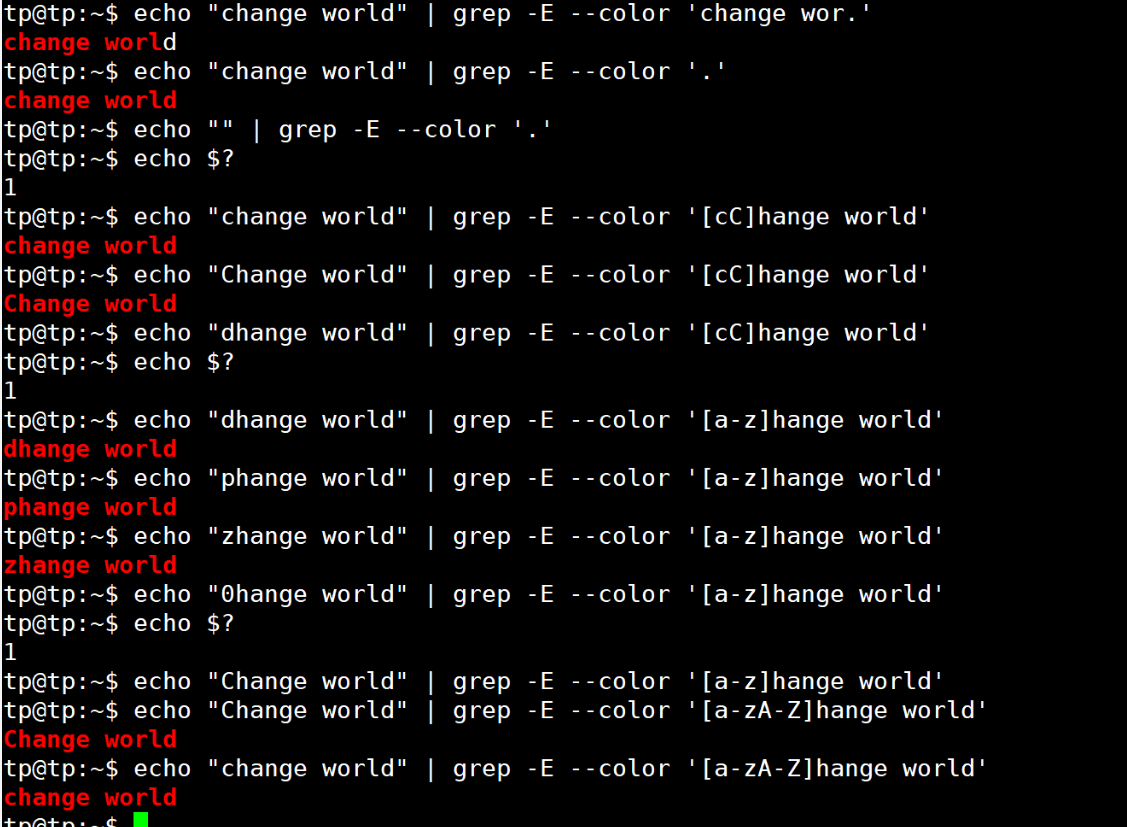
注意:使用 . 默认为贪心匹配,和后面的正则匹配方式相关,后面再述。
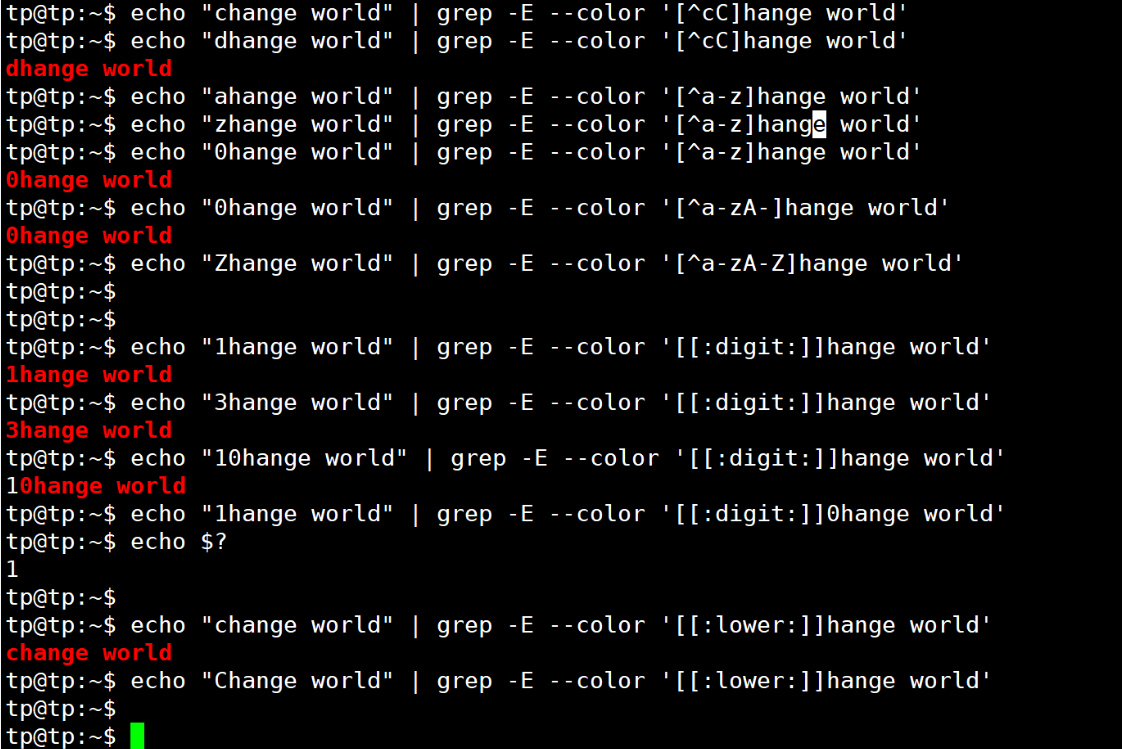
2. 数量限定符:
| 字符 | 说明 | 举例 |
|---|---|---|
| ? | 匹配紧跟它前面的单元(前面的一个数字或字符) 0或1次 | 如匹配小数,用0\.?[0-9]匹配0.1 、0.2、0.3等;由于.在正则里面是特殊符号所以需要用\进行转义操作(后面再说) |
| + | 匹配紧跟它前面的单元 1或多次 | [a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+\.com匹配一个邮箱地址 |
| * | 匹配紧跟它前面的单元0或多次 | [0-9][0-9]*匹配至少一位数字,等价于[0-9]+ |
| {N} | 精确匹配紧跟它前面的单元N次 | [0-9]{3}匹配000到999之间的数字 |
| {N,} | 匹配紧跟它前面的单元至少N次 | [0-9]{3,}匹配三位及其以上的数字 |
| {,M} | 匹配紧跟它前面的单元最多M次 | [0-9]{,1}等价于[0-9]? |
| {N,M} | 匹配紧跟它前面的单元N~M次 | 近似匹配IP地址:[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3} |
应用:
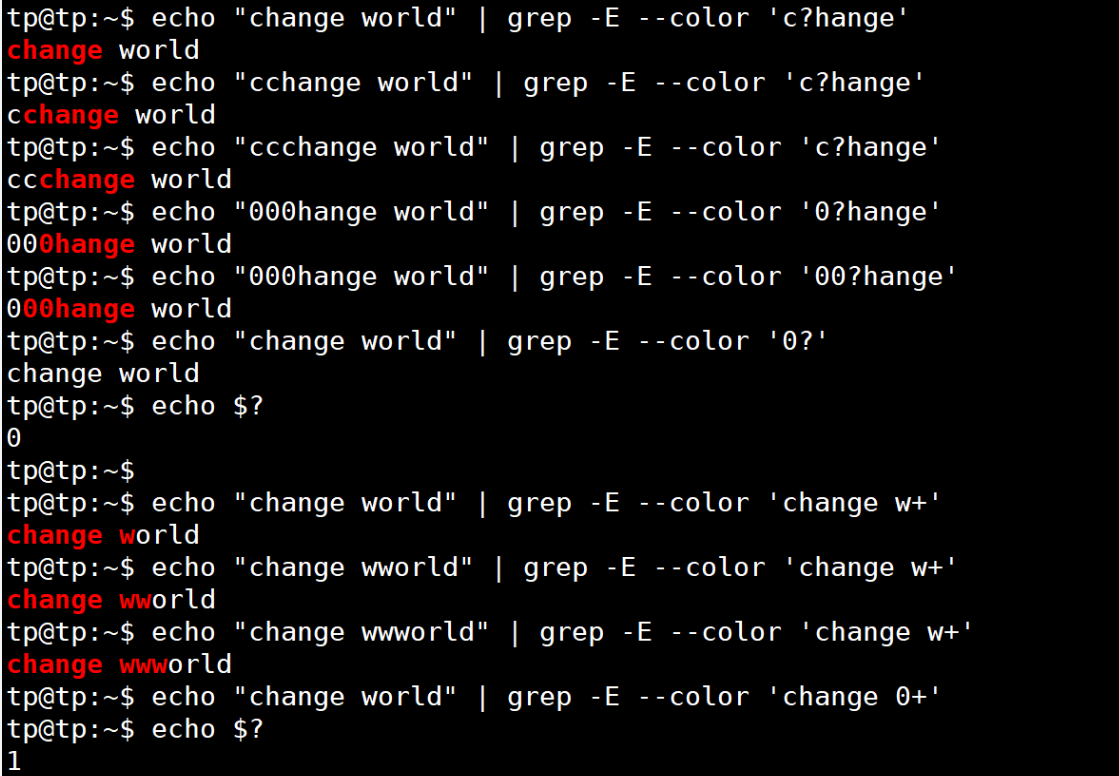
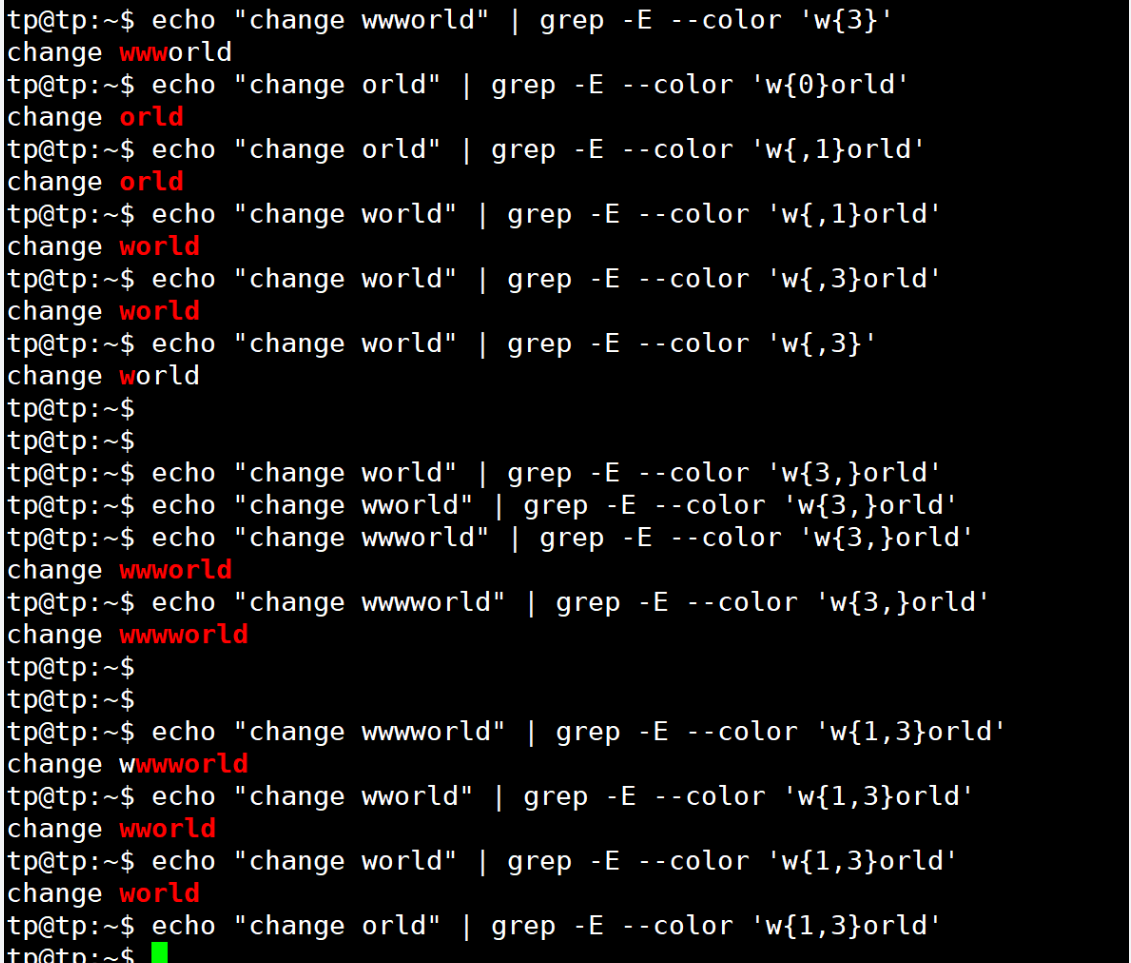
3. 位置限定符:
| 字符 | 说明 | 举例 |
|---|---|---|
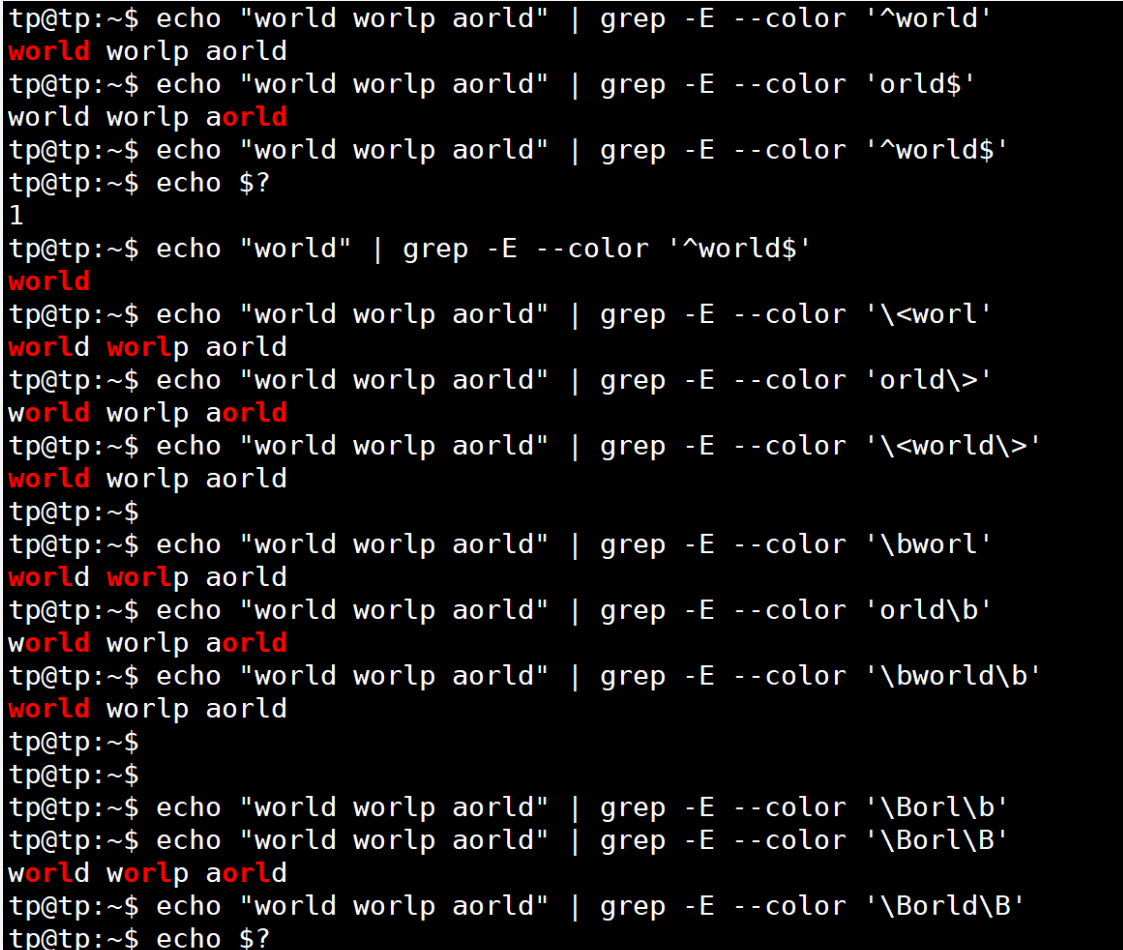
| ^ | 匹配行首位置,从行首开始匹配 | ^world只匹配一行开头的world |
| $ | 匹配行末位置,从行末尾开始匹配 | ;$匹配一行末尾的;号,^$匹配空行 |
| < | 匹配单词开始位置 | < th匹配this,不匹配teach、ethernet |
| \> | 匹配单词末尾位置 | p\>匹配sleep、leap等,不匹配parent、sleepy |
| \b | 匹配单词的开始位置、末尾位置 | 如 \borld匹配world、aorld,\borld\b只匹配orld |
| \B | 匹配非单词的开头、末尾位置 | 如 \Bat\B匹配battery,不匹配attend、hat等以字符串"at"开头、结尾的单词 |
注意:其中 \b 用来限定是目标串中是否有以指定字符串开头的单词,我们称之为词界。 \B 称之为非词界
应用:
4. 特殊符号:
| 字符 | 说明 | 举例 |
|---|---|---|
| \ | 转义字符,普通字符转义为特殊字符,特殊字符转义为普通字符 | <写成<匹配单词开头,.前面加上\写成\.取 . 的字面值 |
| () | 将正则表达式的一部分括起来组成一个单元,可以对整个单元使用数量限定符 | ([0-9]{1,3}\.){3}[0-9]{3}匹配IP地址 |
| | | 连接两个子表达式,表示或的关系 | n(o|either)匹配no或neither |
应用:
( )将包含内容括起来作为一个整体,进而通过数量限定符限定。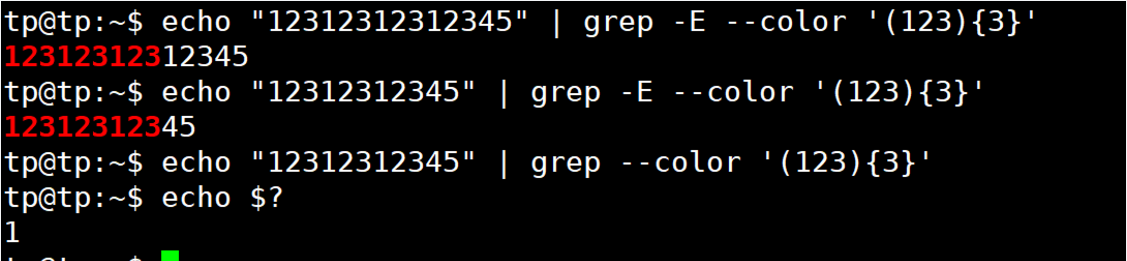
| 用来级联多个条件,只要有任意一个匹配,即可匹配,表示或者关系,我们称之为析取符,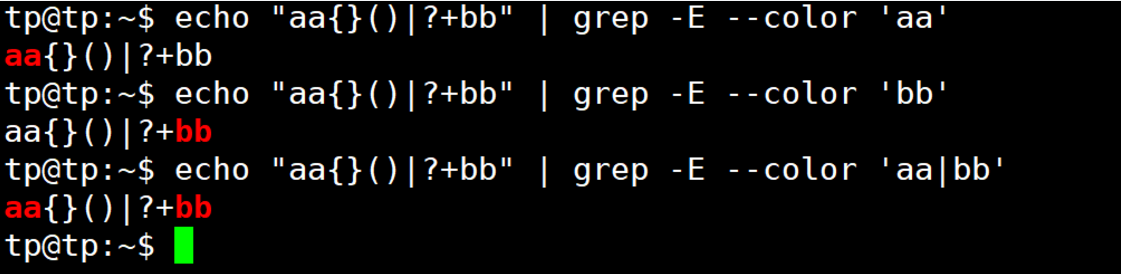
正则表达式版本其他常用通用字符集及其替换
| 符号 | 等价于 | 匹配 |
|---|---|---|
| \d | [0-9] | 数字字符 |
| \D | [^0-9] | 非数字字符 |
| \w | [a-zA-Z0-9_] | 数字字母下划线 |
| \W | [^\w] | 非数字字母下划线 |
| \s | [_\r\t\n\f] | 表格,换行等空白区域 |
| \S | [^\s] | 非空白区域 |
于是, 我们现在可以用这些符号来简化我们正则表达式的编写了?试试

可是结果好像并不如我们所愿?其实这里还与正则表达式版本有关。正则分为以下几个版本:
基本的正则表达式(Basic Regular Expression 又叫 Basic RegEx 简称 BREs)扩展的正则表达式(Extended Regular Expression 又叫 Extended RegEx 简称 EREs)Perl 的正则表达式(Perl Regular Expression 又叫 Perl RegEx 简称 PREs)
在grep中指定相应的参数即可,而这几个版本中默认的就是基本正则,带上-E选项就是扩展正则,而带上-P参数就是用perl版正则。解决前面的问题,我们这里让grep带上-P选项便可解决了
版本间区别正则表达式的Extended规范和Basic规范基本相同。只是在Basic规范下,有些字符 ?+{}|() 应解释为普通字符,要表示上述特殊含义则需要加 \ 转义。反之,在Extended规范下, ?+{}|() 应该被理解成特殊含义,要取其字面值,也要对其进行\ \ 转义。所以, grep 工具带上 -E 选项,表示使用扩展正则来进行匹配(亦可直接使用egrep 命令操作),若没有,则表示使用基准正则进行匹配。带-P选项使用的perl正则匹配。它是perl语言集成的最重要的一种特性,它十分强大,很多语言设计正则式支持的时候基本上都参考Perl的正则表达式。正则匹配模式
贪婪模式
正则表达式去匹配时,会尽量多的去匹配符合条件的内容,grep命令 默认使用的就是贪婪匹配,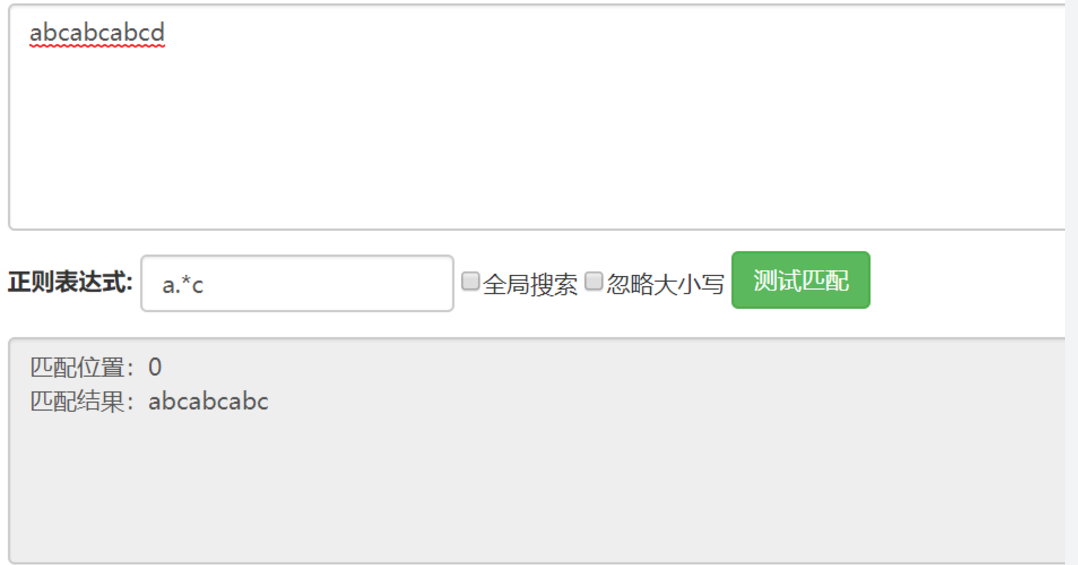 非贪婪模式
非贪婪模式
正则表达式去匹配时,会尽量少的匹配符合条件的内容 也就是说,一旦发现匹配符合要求,立马就匹配成功,而不会继续匹配下去(除非有g选项,开启下一组匹配)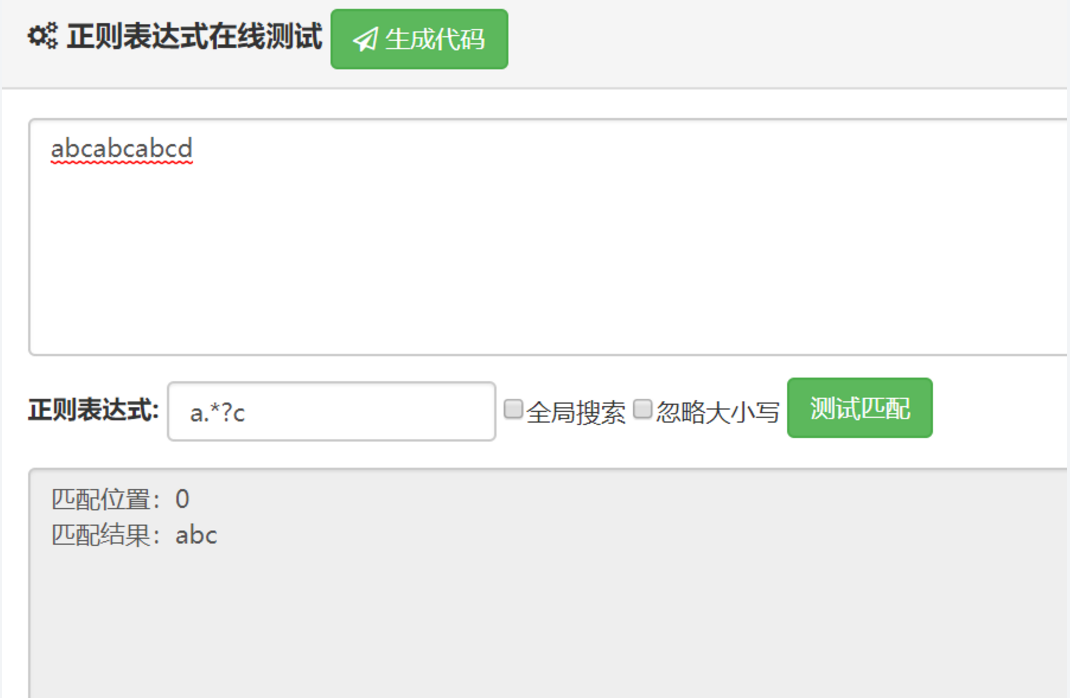
总结:可以看到,非贪婪模式的标识符,就是贪婪模式的标识符后面加上一个 ?
到此,关于“讲解linux关于正则表达式grep”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





