这篇文章将为大家详细讲解有关Scrapy框架怎么在python中使用,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
Python 爬虫包含两个重要的部分:正则表达式和Scrapy框架的运用, 正则表达式对于所有语言都是通用的,网络上可以找到各种资源。
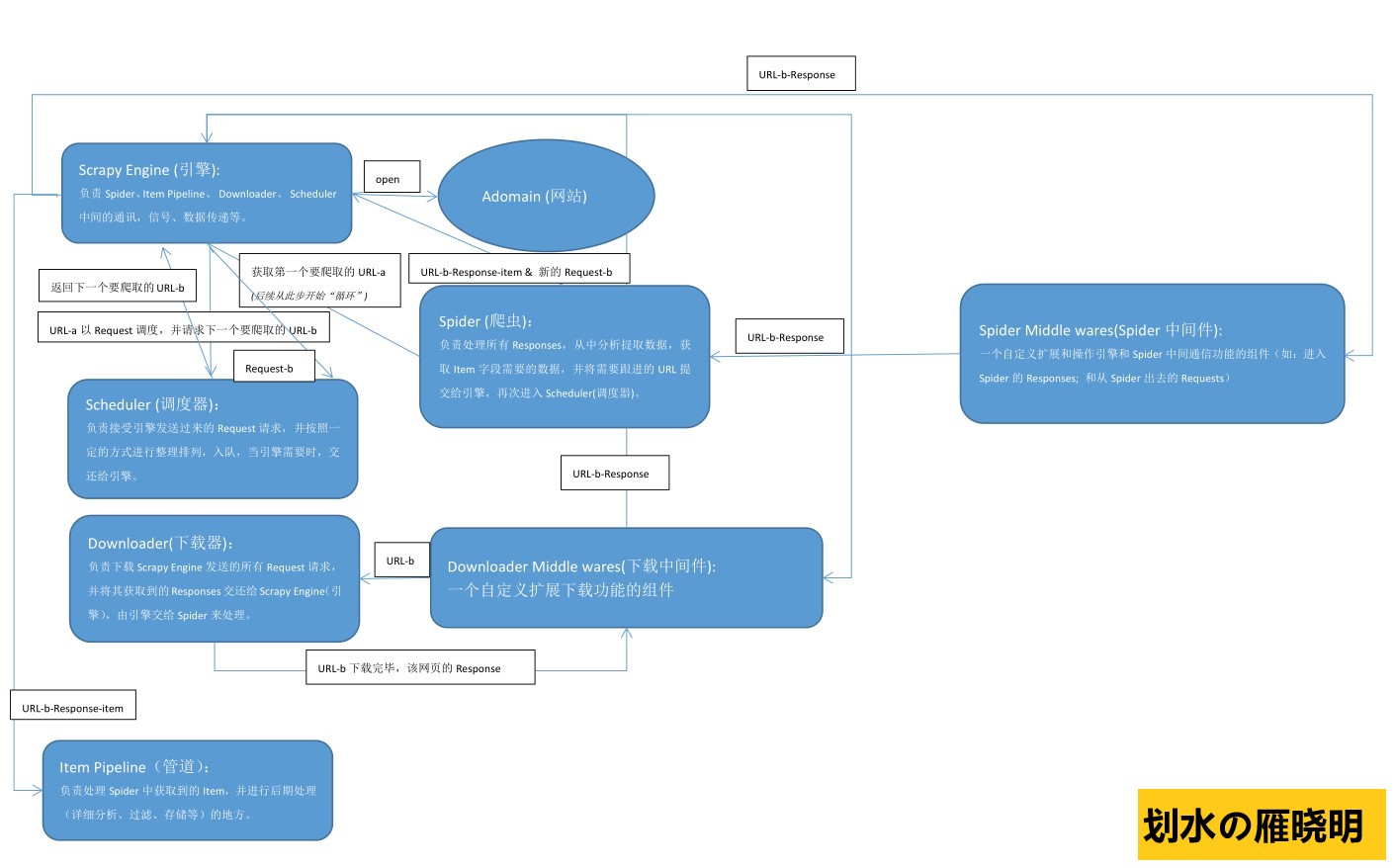
如下是手绘Scrapy框架原理图,帮助理解
如下是一段运用Scrapy创建的spider:使用了内置的crawl模板,以利用Scrapy库的CrawlSpider。相对于简单的爬取爬虫来说,Scrapy的CrawlSpider拥有一些网络爬取时可用的特殊属性和方法:
$ scrapy genspider country_or_district example.python-scrapying.com--template=crawl
运行genspider命令后,下面的代码将会在example/spiders/country_or_district.py中自动生成。
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from example.items import CountryOrDistrictItem class CountryOrDistrictSpider(CrawlSpider): name = 'country_or_district' allowed_domains = ['example.python-scraping.com'] start_urls = ['http://example.python-scraping.com/'] rules = ( Rule(LinkExtractor(allow=r'/index/', deny=r'/user/'), follow=True), Rule(LinkExtractor(allow=r'/view/', deny=r'/user/'), callback='parse_item'), ) def parse_item(self, response): item = CountryOrDistrictItem() name_css = 'tr#places_country_or_district__row td.w2p_fw::text' item['name'] = response.css(name_css).extract() pop_xpath = '//tr[@id="places_population__row"]/td[@class="w2p_fw"]/text()' item['population'] = response.xpath(pop_xpath).extract() return item
爬虫类包括的属性:
name: 识别爬虫的字符串。
allowed_domains: 可以爬取的域名列表。如果没有设置该属性,则表示可以爬取任何域名。
start_urls: 爬虫起始URL列表。
rules: 该属性为一个通过正则表达式定义的Rule对象元组,用于告知爬虫需要跟踪哪些链接以及哪些链接包含抓取的有用内容。
关于Scrapy框架怎么在python中使用就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





