今天就跟大家聊聊有关使用Python怎么过滤相似的文本,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
titles = [ "End of Year Review 2020", "2020 End of Year", "January Sales Projections", "Accounts 2017-2018", "Jan Sales Predictions" ] # Desired output filtered_titles = [ "End of Year Review 2020", "January Sales Projections", "Accounts 2017-2018", ]
根据以上的问题,本文适合那些希望快速而实用地概述如何解决这样的问题并广泛了解他们同时在做什么的人!
接下来,我将介绍我为解决这个问题所采取的不同步骤。下面是控制流的概要:
预处理所有标题文本
生成所有标题成对
测试所有对的相似性
如果一对文本未能通过相似性测试,则删除其中一个文本并创建一个新的文本列表
继续测试这个新的相似的文本列表,直到没有类似的文本留下
用Python表示,这可以很好地映射到递归函数上!
下面是Python中实现此功能的两个函数。
import spacy
from itertools import combinations
# Set globals
nlp = spacy.load("en_core_web_md")
def pre_process(titles):
"""
Pre-processes titles by removing stopwords and lemmatizing text.
:param titles: list of strings, contains target titles,.
:return: preprocessed_title_docs, list containing pre-processed titles.
"""
# Preprocess all the titles
title_docs = [nlp(x) for x in titles]
preprocessed_title_docs = []
lemmatized_tokens = []
for title_doc in title_docs:
for token in title_doc:
if not token.is_stop:
lemmatized_tokens.append(token.lemma_)
preprocessed_title_docs.append(" ".join(lemmatized_tokens))
del lemmatized_tokens[
:
] # empty the lemmatized tokens list as the code moves onto a new title
return preprocessed_title_docs
def similarity_filter(titles):
"""
Recursively check if titles pass a similarity filter.
:param titles: list of strings, contains titles.
If the function finds titles that fail the similarity test, the above param will be the function output.
:return: this method upon itself unless there are no similar titles; in that case the feed that was passed
in is returned.
"""
# Preprocess titles
preprocessed_title_docs = pre_process(titles)
# Remove similar titles
all_summary_pairs = list(combinations(preprocessed_title_docs, 2))
similar_titles = []
for pair in all_summary_pairs:
title1 = nlp(pair[0])
title2 = nlp(pair[1])
similarity = title1.similarity(title2)
if similarity > 0.8:
similar_titles.append(pair)
titles_to_remove = []
for a_title in similar_titles:
# Get the index of the first title in the pair
index_for_removal = preprocessed_title_docs.index(a_title[0])
titles_to_remove.append(index_for_removal)
# Get indices of similar titles and remove them
similar_title_counts = set(titles_to_remove)
similar_titles = [
x[1] for x in enumerate(titles) if x[0] in similar_title_counts
]
# Exit the recursion if there are no longer any similar titles
if len(similar_title_counts) == 0:
return titles
# Continue the recursion if there are still titles to remove
else:
# Remove similar titles from the next input
for title in similar_titles:
idx = titles.index(title)
titles.pop(idx)
return similarity_filter(titles)
if __name__ == "__main__":
your_title_list = ['title1', 'title2']
similarty_filter(your_title_list)第一个是预处理标题文本的简单函数;它删除像' the ', ' a ', ' and '这样的停止词,并只返回标题中单词的引理。
如果你在这个函数中输入“End of Year Review 2020”,你会得到“end year review 2020”作为输出;如果你输入“January Sales Projections”,你会得到“january sale projection”。
它主要使用了python中非常容易使用的spacy库.
第二个函数(第30行)为所有标题创建配对,然后确定它们是否通过了余弦相似度测试。如果它没有找到任何相似的标题,那么它将输出一个不相似标题的列表。但如果它确实找到了相似的标题,在删除没有通过相似度测试的配对后,它会将这些过滤后的标题再次发送给它自己,并检查是否还有相似的标题。
这就是为什么它是递归的!简单明了,这意味着函数将继续检查输出,以真正确保在返回“最终”输出之前没有类似的标题。
但简而言之,这就是spacy在幕后做的事情……
首先,还记得那些预处理过的工作吗?首先,spacy把我们输入的单词变成了一个数字矩阵。
一旦它完成了,你就可以把这些数字变成向量,也就是说你可以把它们画在图上。
一旦你这样做了,计算两条直线夹角的余弦就能让你知道它们是否指向相同的方向。
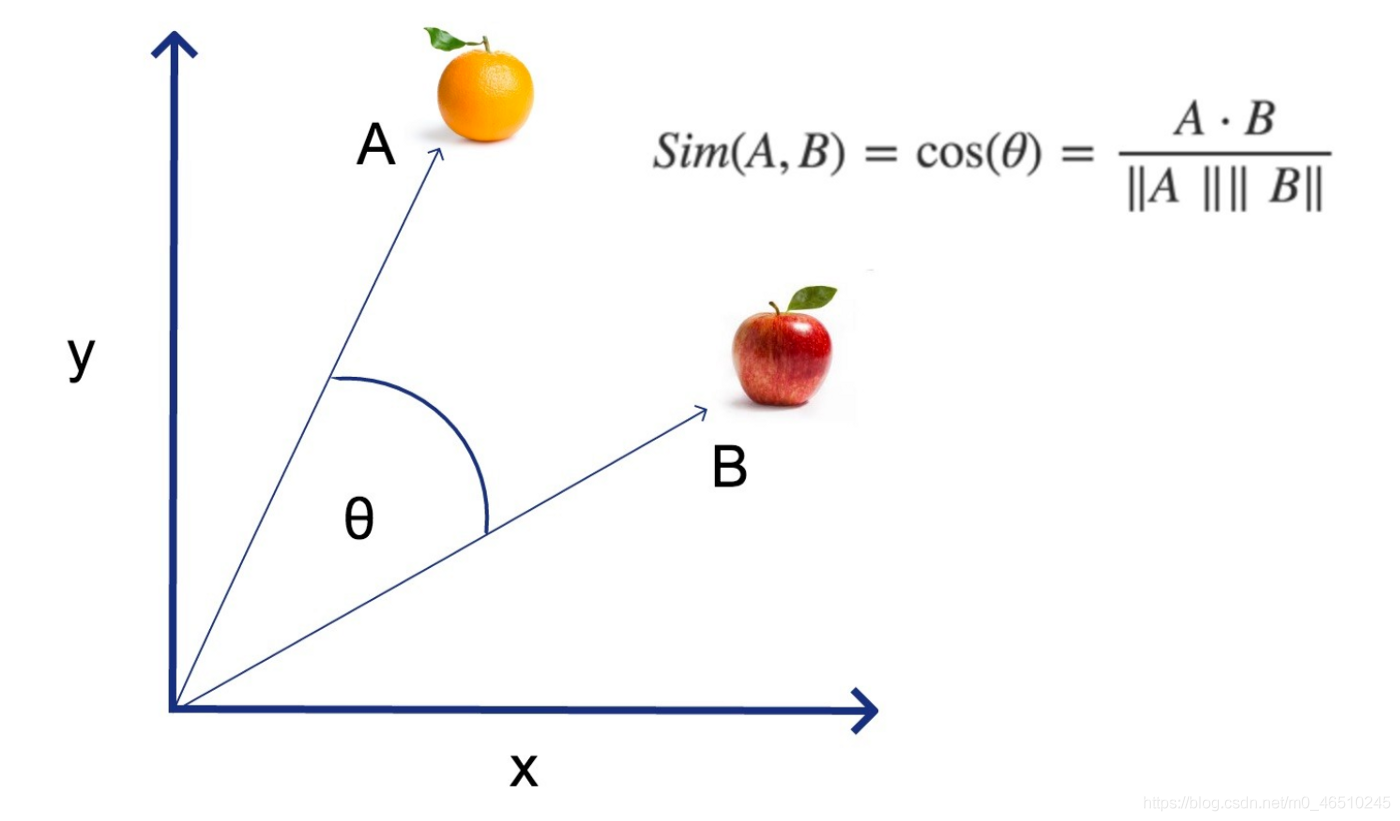
所以,在上图中,想象一下,A线代表“闪亮的橙色水果”,B线代表“闪亮的红苹果是一种水果”。
在这种情况下,行A和行B都对应于空格为这两个句子创建的数字矩阵。这两条线之间的角度——在上面的图表中由希腊字母theta表示——是非常有用的!你可以计算余弦来判断这两条线是否指向同一个方向。
看完上述内容,你们对使用Python怎么过滤相似的文本有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





