快速排序
从数列中挑出一个元素,称为 “基准”(pivot),重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
排序效果:
cdn2.b0.upaiyun.com/2012/01/Visual-and-intuitive-feel-of-7-common-sorting-algorithms.gif">
int PartSort(int* a, int left, int right) //每步的排序
{
int key = a[right];
int begin = left;
int end = right - 1;
while (begin < end)
{
while (begin < end && a[begin] <= key)
{
++begin;
}
while (begin < end && a[end] >= key)
{
--end;
}
if (begin < end)
{
swap(a[begin], a[end]);
}
}
if (a[begin]>a[right])
{
swap(a[begin], a[right]);
return begin;
}
else
{
return right;
}
}
void QuickSort(int* a, int left, int right) //快速排序
{
assert(a);
if (left >= right)
{
return;
}
int div = PartSort(a, left, right);
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}2.堆排序:
堆积排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
排序效果:

void AdjustDown(int* a,size_t size,size_t parents) //大堆 下调
{
assert(a);
size_t child = parents * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1]>a[child])
{
++child;
}
if (a[child]>a[parents])
{
swap(a[child], a[parents]);
parents = child;
child = parents * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, size_t size) //堆排序
{
assert(a);
for (int i = (size - 2) / 2; i >= 0; i--) //建堆
{
AdjustDown(a, size, i);
}
for (int i = 0; i < size; i++)
{
swap(a[0], a[size - i - 1]);
AdjustDown(a, size - i-1, 0);
}
}3.选择排序:
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。以此类推,直到所有元素均排序完毕。
效果如下:

void SelectSort(int* a, size_t size) //选择排序
{
assert(a);
for (size_t i = 0; i < size; i++)
{
int* p = a;
for (size_t j = 0; j < size-i; j++)
{
if (*p < a[j])
{
p = &a[j];
}
}
swap(*p, a[size-i-1]);
}
}4.冒泡排序:
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
效果如下:

void BubbleSort(int* a,size_t size) //冒泡排序
{
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size - i - 1; j++)
{
if (a[j]>a[j + 1])
{
swap(a[j], a[j + 1]);
}
}
}
}5.插入排序
介绍:
插入排序(Insertion Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
步骤:
1.从第一个元素开始,该元素可以认为已经被排序
2.取出下一个元素,在已经排序的元素序列中从后向前扫描
3.如果该元素(已排序)大于新元素,将该元素移到下一位置
4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5.将新元素插入到该位置中
6.重复步骤2
void InsertSort(int *a, size_t size) //插入排序
{
assert(a);
for (int i = 1; i < size - 1; i++)
{
int end =i;
int tmp = a[i];
while (end >= 0 && a[end-1]>tmp)
{
a[end] = a[end-i];
--end;
}
a[end-1] = tmp;
}
}6.希尔排序
介绍:
希尔排序,也称递减增量排序算法,是插入排序的一种高速而稳定的改进版本。希尔排序是基于插入排序的以下两点性质而提出改进方法的:
1、插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
2、但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位
排序效果:

void ShellSort(int* a, size_t size) //希尔排序
{
int gap = size;
while (gap > 1)
{
gap = gap / 3 + 1;
for (size_t i = 0; i<size - gap;i++)
{
int end =i;
int tmp = a[end + gap];
while (end >= 0 && a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
a[end + gap] = tmp;
}
}
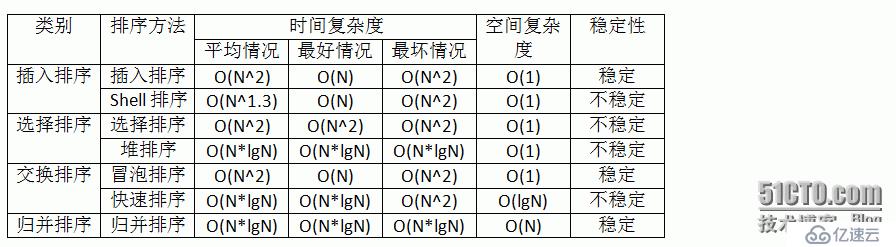
}这几种排序的时间复杂度与空间复杂度如下表所示:
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





