主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无 一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通 过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
前言
使用Hadoop已经有一段时间了,从开始的迷茫,到各种的尝试,到现在组合应用….慢慢地涉及到数据处理的事情,已经离不开hadoop了。Hadoop在大数据领域的成功,更引发了它本身的加速发展。现在Hadoop家族产品,已经达到20个了之多。
有必要对自己的知识做一个整理了,把产品和技术都串起来。不仅能加深印象,更可以对以后的技术方向,技术选型做好基础准备。
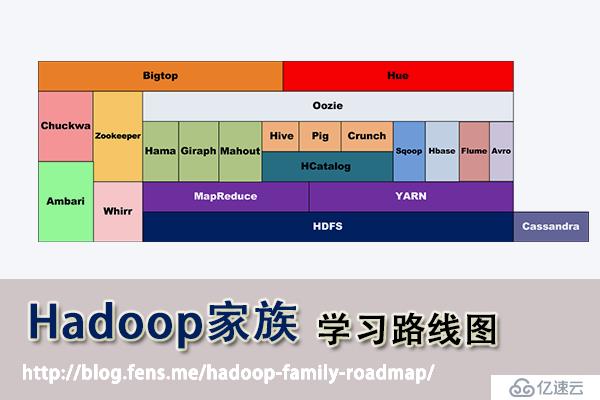
本文为“Hadoop家族”开篇,Hadoop家族学习路线图
目录
Hadoop家族产品
Hadoop家族学习路线图
截止到2013年,根据cloudera的统计,Hadoop家族产品已经达到20个!
http://blog.cloudera.com/blog/2013/01/apache-hadoop-in-2013-the-state-of-the-platform/
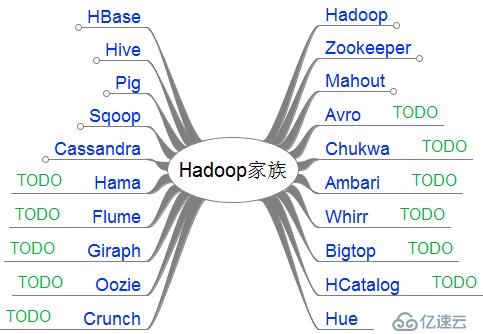
接下来,我把这20个产品,分成了2类。
第一类,是我已经掌握的
第二类,是TODO准备继续学习的
一句话产品介绍:
Apache Hadoop: 是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。
Apache Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Apache Pig: 是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
Apache HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
Apache Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Apache Zookeeper: 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务
Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Apache Cassandra:是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身
Apache Avro: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制
Apache Ambari: 是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
Apache Chukwa: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。
Apache Hama: 是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
Apache Flume: 是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输。
Apache Giraph: 是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
Apache Oozie: 是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。
Apache Crunch: 是基于Google的FlumeJava库编写的Java库,用于创建MapReduce程序。与Hive,Pig类似,Crunch提供了用于实现如连接数据、执行聚合和排序记录等常见任务的模式库
Apache Whirr: 是一套运行于云服务的类库(包括Hadoop),可提供高度的互补性。Whirr学支持Amazon EC2和Rackspace的服务。
Apache Bigtop: 是一个对Hadoop及其周边生态进行打包,分发和测试的工具。
Apache HCatalog: 是基于Hadoop的数据表和存储管理,实现中央的元数据和模式管理,跨越Hadoop和RDBMS,利用Pig和Hive提供关系视图。
Cloudera Hue: 是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。
下面我将分别介绍各个产品的安装和使用,以我经验总结我的学习路线。
Hadoop
Hadoop学习路线图
Yarn学习路线图
用Maven构建Hadoop项目
Hadoop历史版本安装
Hadoop编程调用HDFS
海量Web日志分析 用Hadoop提取KPI统计指标
用Hadoop构建电影推荐系统
创建Hadoop母体虚拟机
克隆虚拟机增加Hadoop节点
R语言为Hadoop注入统计血脉
RHadoop实践系列之一 Hadoop环境搭建
Hive
Hive学习路线图
Hive安装及使用攻略
Hive导入10G数据的测试
R利剑NoSQL系列文章 之 Hive
用RHive从历史数据中提取逆回购信息
Pig
Pig学习路线图
Zookeeper
Zookeeper学习路线图
ZooKeeper伪分步式集群安装及使用
ZooKeeper实现分布式队列Queue
ZooKeeper实现分布式FIFO队列
HBase
HBase学习路线图
RHadoop实践系列之四 rhbase安装与使用
Mahout
Mahout学习路线图
用R解析Mahout用户推荐协同过滤算法(UserCF)
RHadoop实践系列之三 R实现MapReduce的协同过滤算法
用Maven构建Mahout项目
Mahout推荐算法API详解
从源代码剖析Mahout推荐引擎
Mahout分步式程序开发 基于物品的协同过滤ItemCF
Mahout分步式程序开发 聚类Kmeans
用Mahout构建职位推荐引擎
Sqoop
Sqoop学习路线图
Cassandra
Cassandra学习路线图
Cassandra单集群实验2个节点
R利剑NoSQL系列文章 之 Cassandra
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





