еҰӮдҪ•еңЁPythonдёӯдҪҝз”ЁеҶізӯ–ж ‘
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іеҰӮдҪ•еңЁPythonдёӯдҪҝз”ЁеҶізӯ–ж ‘пјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
pythonжҳҜд»Җд№Ҳж„ҸжҖқ
PythonжҳҜдёҖз§Қи·Ёе№іеҸ°зҡ„гҖҒе…·жңүи§ЈйҮҠжҖ§гҖҒзј–иҜ‘жҖ§гҖҒдә’еҠЁжҖ§е’Ңйқўеҗ‘еҜ№иұЎзҡ„и„ҡжң¬иҜӯиЁҖпјҢе…¶жңҖеҲқзҡ„и®ҫи®ЎжҳҜз”ЁдәҺзј–еҶҷиҮӘеҠЁеҢ–и„ҡжң¬пјҢйҡҸзқҖзүҲжң¬зҡ„дёҚж–ӯжӣҙж–°е’Ңж–°еҠҹиғҪзҡ„ж·»еҠ пјҢеёёз”ЁдәҺз”ЁдәҺејҖеҸ‘зӢ¬з«Ӣзҡ„йЎ№зӣ®е’ҢеӨ§еһӢйЎ№зӣ®гҖӮ
дёҖгҖҒиҰҒжұӮ

дәҢгҖҒеҺҹзҗҶ
еҶізӯ–ж ‘жҳҜдёҖз§Қзұ»дјјдәҺжөҒзЁӢеӣҫзҡ„з»“жһ„пјҢе…¶дёӯжҜҸдёӘеҶ…йғЁиҠӮзӮ№д»ЈиЎЁдёҖдёӘеұһжҖ§дёҠзҡ„вҖңжөӢиҜ•вҖқпјҢжҜҸдёӘеҲҶж”Ҝд»ЈиЎЁжөӢиҜ•зҡ„з»“жһңпјҢжҜҸдёӘеҸ¶иҠӮзӮ№д»ЈиЎЁдёҖдёӘжөӢиҜ•з»“жһңгҖӮзұ»ж ҮзӯҫпјҲеңЁи®Ўз®—жүҖжңүеұһжҖ§еҗҺеҒҡеҮәзҡ„еҶіе®ҡпјүгҖӮд»Һж №еҲ°еҸ¶зҡ„и·Ҝеҫ„д»ЈиЎЁеҲҶзұ»и§„еҲҷгҖӮ
еҶізӯ–ж ‘еӯҰд№ зҡ„зӣ®зҡ„жҳҜдёәдәҶдә§з”ҹдёҖжЈөжіӣеҢ–иғҪеҠӣејәпјҢеҚіеӨ„зҗҶжңӘи§ҒзӨәдҫӢиғҪеҠӣејәзҡ„еҶізӯ–ж ‘гҖӮеӣ жӯӨеҰӮдҪ•жһ„е»әеҶізӯ–ж ‘пјҢжҳҜеҗҺз»ӯйў„жөӢзҡ„е…ій”®пјҒиҖҢжһ„е»әеҶізӯ–ж ‘пјҢе°ұйңҖиҰҒзЎ®е®ҡзұ»ж ҮзӯҫеҲӨж–ӯзҡ„е…ҲеҗҺпјҢе…¶еҶіе®ҡдәҶжһ„е»әзҡ„еҶізӯ–ж ‘зҡ„жҖ§иғҪгҖӮеҶізӯ–ж ‘зҡ„еҲҶж”ҜиҠӮзӮ№еә”иҜҘе°ҪеҸҜиғҪзҡ„еұһдәҺеҗҢдёҖзұ»еҲ«пјҢеҚіиҠӮзӮ№зҡ„вҖңзәҜеәҰвҖқиҰҒи¶ҠжқҘи¶Ҡй«ҳпјҢеҸӘжңүиҝҷж ·пјҢжүҚиғҪжңҖдҪіеҶізӯ–гҖӮ
з»Ҹе…ёзҡ„еұһжҖ§еҲ’еҲҶж–№жі•пјҡ
дҝЎжҒҜеўһзӣҠ
еўһзӣҠзҺҮ
еҹәе°јжҢҮж•°
жң¬ж¬Ўе®һйӘҢйҮҮз”ЁдәҶдҝЎжҒҜеўһзӣҠпјҢеӣ жӯӨдёӢйқўеҸӘеҜ№дҝЎжҒҜеўһзӣҠиҝӣиЎҢд»Ӣз»ҚгҖӮ
дёүгҖҒдҝЎжҒҜеўһзӣҠзҡ„и®Ўз®—ж–№жі•

е…¶дёӯDдёәж ·жң¬йӣҶеҗҲпјҢaдёәж ·жң¬йӣҶеҗҲдёӯзҡ„еұһжҖ§,DvиЎЁзӨәDж ·жң¬йӣҶеҗҲдёӯaеұһжҖ§дёәvзҡ„ж ·жң¬йӣҶеҗҲгҖӮ
Ent(x)еҮҪж•°жҳҜи®Ўз®—дҝЎжҒҜзҶөпјҢиЎЁзӨәзҡ„жҳҜж ·жң¬йӣҶеҗҲзҡ„зәҜеәҰдҝЎжҒҜ,дҝЎжҒҜзҶөзҡ„и®Ўз®—ж–№жі•еҰӮдёӢпјҡ
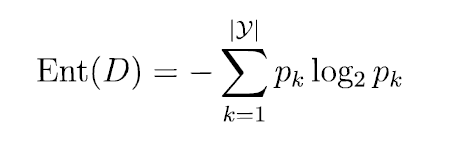
е…¶дёӯpkиЎЁзӨәж ·жң¬дёӯжңҖз»Ҳз»“жһңз§Қзұ»дёӯе…¶дёӯдёҖдёӘзұ»еҲ«жүҖеҚ зҡ„жҜ”дҫӢпјҢжҜ”еҰӮжңү10дёӘж ·жң¬пјҢе…¶дёӯ5дёӘеҘҪпјҢ5дёӘдёҚеҘҪпјҢеҲҷе…¶дёӯp1 = 5/10, p2 = 5/10гҖӮ
дёҖиҲ¬иҖҢиЁҖпјҢдҝЎжҒҜеўһзӣҠи¶ҠеӨ§пјҢеҲҷж„Ҹе‘ізқҖдҪҝз”ЁеұһжҖ§ОұжқҘиҝӣиЎҢеҲ’еҲҶжүҖиҺ·еҫ—зҡ„вҖңзәҜеәҰжҸҗеҚҮвҖқи¶ҠеӨ§пјҢеӣ жӯӨеңЁйҖүжӢ©еұһжҖ§иҠӮзӮ№зҡ„ж—¶еҖҷдјҳе…ҲйҖүжӢ©дҝЎжҒҜеўһзӣҠй«ҳзҡ„еұһжҖ§пјҒ
еӣӣгҖҒе®һзҺ°иҝҮзЁӢ
жң¬ж¬Ўи®ҫи®Ўз”ЁеҲ°дәҶpandasе’Ңnumpyеә“пјҢдё»иҰҒеҲ©з”Ёе®ғ们жқҘеҜ№ж•°жҚ®иҝӣиЎҢеҝ«йҖҹзҡ„еӨ„зҗҶе’ҢдҪҝз”ЁгҖӮ
йҰ–е…Ҳе°Ҷж•°жҚ®иҜ»е…Ҙпјҡ
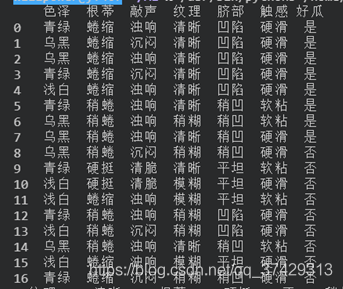
еҸҜд»ҘзңӢеҲ°ж•°жҚ®йӣҶзҡ„ж ҮзӯҫжҳҜз“ңзҡ„дёҚеҗҢзҡ„еұһжҖ§пјҢиҖҢиЎЁж јдёӯзҡ„ж•°жҚ®е°ұжҳҜдёҚеҗҢеұһжҖ§дёӢзҡ„дёҚеҗҢзҡ„еҖјзӯүгҖӮ
if(len(set(D.еҘҪз“ң)) == 1):
#ж Үи®°иҝ”еӣһ
return D.еҘҪз“ң.iloc[0]
elif((len(A) == 0) or Check(D, A[:-1])):
#йҖүжӢ©Dдёӯз»“жһңжңҖеӨҡзҡ„дёәж Үи®°
cnt = D.groupby('еҘҪз“ң').size()
maxValue = cnt[cnt == cnt.max()].index[0]
return maxValue
else:
A1 = copy.deepcopy(A)
attr = Choose(D, A1[:-1])
tree = {attr:{}}
for value in set(D[attr]):
tree[attr][value] = TreeGen(D[D[attr] == value], A1)
return treeTreeGenеҮҪж•°жҳҜз”ҹжҲҗж ‘дё»еҮҪж•°пјҢйҖҡиҝҮеҜ№е®ғзҡ„йҖ’еҪ’и°ғз”ЁпјҢиҝ”еӣһдёӢдёҖзә§ж ‘з»“жһ„(еӯ—е…ё)жқҘе®ҢжҲҗз”ҹжҲҗеҶізӯ–ж ‘гҖӮ
еңЁз”ҹжҲҗж ‘иҝҮзЁӢдёӯпјҢжңүдәҢдёӘз»Ҳжӯўиҝӯд»Јзҡ„жқЎд»¶пјҢ第дёҖдёӘе°ұжҳҜеҪ“иҫ“е…Ҙж•°жҚ®жәҗDзҡ„жүҖжңүжғ…еҶөз»“жһңйғҪзӣёеҗҢпјҢйӮЈд№Ҳе°ҶиҝҷдёӘз»“жһңдҪңдёәеҸ¶иҠӮзӮ№иҝ”еӣһпјӣ第дәҢдёӘе°ұжҳҜеҪ“жІЎжңүеұһжҖ§еҸҜд»ҘеҶҚеҫҖдёӢеҲҶпјҢжҲ–иҖ…Dдёӯзҡ„ж ·жң¬еңЁAжүҖжңүеұһжҖ§дёӢйқўзҡ„еҖјйғҪзӣёеҗҢпјҢйӮЈд№Ҳе°ұе°ҶDзҡ„жүҖжңүжғ…еҶөдёӯз»“жһңжңҖеӨҡзҡ„дҪңдёәеҸ¶иҠӮзӮ№иҝ”еӣһгҖӮ
е…¶дёӯChoose(D:pd.DataFrame, A:list)еҮҪж•°жҳҜйҖүжӢ©ж Үзӯҫзҡ„еҮҪж•°пјҢе…¶ж №жҚ®иҫ“е…Ҙж•°жҚ®жәҗе’Ңеү©дёӢзҡ„еұһжҖ§еҲ—иЎЁз®—еҮәеҜ№еә”ж ҮзӯҫдҝЎжҒҜеўһзӣҠпјҢйҖүжӢ©иғҪдҪҝдҝЎжҒҜеўһзӣҠжңҖеӨ§зҡ„ж Үзӯҫиҝ”еӣһ
def Choose(D:pd.DataFrame, A:list):
result = 0.0
resultAttr = ''
for attr in A:
tmpVal = CalcZengYi(D, attr)
if(tmpVal > result):
resultAttr = attr
result = tmpVal
A.remove(resultAttr)
return resultAttr
жңҖеҗҺжҳҜз»“жһңпјҡ

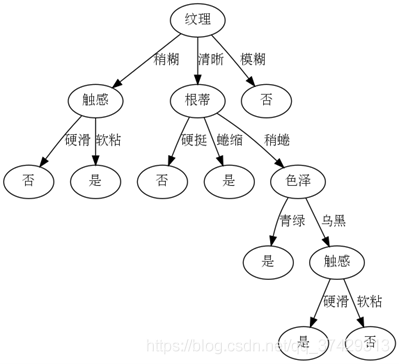
{вҖҳзә№зҗҶ': {вҖҳзЁҚзіҠ': {вҖҳи§Ұж„ҹ': {вҖҳзЎ¬ж»‘': вҖҳеҗҰ', вҖҳиҪҜзІҳ': вҖҳжҳҜ'}}, вҖҳжё…жҷ°': {вҖҳж №и’Ӯ': {вҖҳзЎ¬жҢә': вҖҳеҗҰ', вҖҳиң·зј©': вҖҳжҳҜ', вҖҳзЁҚиң·': {вҖҳиүІжіҪ': {вҖҳйқ’з»ҝ': вҖҳжҳҜ', вҖҳд№Ңй»‘': {вҖҳи§Ұж„ҹ': {вҖҳзЎ¬ж»‘': вҖҳжҳҜ', вҖҳиҪҜзІҳ': вҖҳеҗҰ'}}}}}}, вҖҳжЁЎзіҠ': вҖҳеҗҰ'}}
з»ҳеӣҫеҰӮдёӢпјҡ
дә”гҖҒзЁӢеәҸ
дё»зЁӢеәҸ
#!/usr/bin/python3
# -*- encoding: utf-8 -*-
'''
@Description:еҶізӯ–ж ‘:
@Date :2021/04/25 15:57:14
@Author :willpower
@version :1.0
'''
import pandas as pd
import numpy as np
import treeplot
import copy
import math
"""
@description :и®Ўз®—зҶөеҖј
---------
@param :иҫ“е…Ҙдёәеҹәжң¬pandasзұ»еһӢdataFrame,е…¶дёӯиҫ“е…ҘжңҖеҗҺдёҖиЎҢдёәе®һйҷ…з»“жһң
-------
@Returns :иҝ”еӣһзҶөеҖјпјҢзұ»еһӢдёәжө®зӮ№еһӢ
-------
"""
def CalcShang(D:pd.DataFrame):
setCnt = D.shape[0]
result = 0.0
# for i in D.groupby(D.columns[-1]).size().index:
#йҒҚеҺҶжҜҸдёҖдёӘеҖј
for i in set(D[D.columns[-1]]):
#иҺ·еҸ–иҜҘеұһжҖ§дёӢзҡ„жҹҗдёӘеҖјзҡ„ж¬Ўж•°
cnt = D.iloc[:,-1].value_counts()[i]
result = result + (cnt/setCnt)*math.log(cnt/setCnt, 2)
return (-1*result)
"""
@description :и®Ўз®—еўһзӣҠ
---------
@param :иҫ“е…ҘдёәDataFrameж•°жҚ®жәҗпјҢ然еҗҺжҳҜйңҖиҰҒи®Ўз®—еўһзӣҠзҡ„еұһжҖ§еҖј
-------
@Returns :иҝ”еӣһеўһзӣҠеҖј,жө®зӮ№еһӢ
-------
"""
def CalcZengYi(D:pd.DataFrame, attr:str):
sumShang = CalcShang(D)
setCnt = D.shape[0]
result = 0.0
valus = D.groupby(attr).size()
for subVal in valus.index:
result = result + (valus[subVal]/setCnt)*CalcShang(D[D[attr] == subVal])
return sumShang - result
"""
@description :йҖүжӢ©жңҖдҪізҡ„еұһжҖ§
---------
@param :иҫ“е…Ҙдёәж•°жҚ®жәҗпјҢд»ҘеҸҠиҝҳеү©дёӢзҡ„еұһжҖ§еҲ—иЎЁ
-------
@Returns :иҝ”еӣһжңҖдҪіеұһжҖ§
-------
"""
def Choose(D:pd.DataFrame, A:list):
result = 0.0
resultAttr = ''
for attr in A:
tmpVal = CalcZengYi(D, attr)
if(tmpVal > result):
resultAttr = attr
result = tmpVal
A.remove(resultAttr)
return resultAttr
"""
@description :жЈҖжҹҘж•°жҚ®еңЁжҜҸдёҖдёӘеұһжҖ§дёӢйқўзҡ„еҖјжҳҜеҗҰзӣёеҗҢ
---------
@param :иҫ“е…ҘдёәDataFrameд»ҘеҸҠеү©дёӢзҡ„еұһжҖ§еҲ—иЎЁ
-------
@Returns :иҝ”еӣһboolеҖјпјҢзӣёеҗҢиҝ”еӣһ1пјҢдёҚеҗҢиҝ”еӣһ0
-------
"""
def Check(D:pd.DataFrame, A:list):
for i in A:
if(len(set(D[i])) != 1):
return 0
return 1
"""
@description :з”ҹжҲҗж ‘дё»еҮҪж•°
---------
@param :ж•°жҚ®жәҗDataFrameд»ҘеҸҠжүҖжңүзұ»еһӢ
-------
@Returns :иҝ”еӣһз”ҹжҲҗзҡ„еӯ—е…ёж ‘
-------
"""
def TreeGen(D:pd.DataFrame, A:list):
if(len(set(D.еҘҪз“ң)) == 1):
#ж Үи®°иҝ”еӣһ
return D.еҘҪз“ң.iloc[0]
elif((len(A) == 0) or Check(D, A[:-1])):
#йҖүжӢ©Dдёӯз»“жһңжңҖеӨҡзҡ„дёәж Үи®°
cnt = D.groupby('еҘҪз“ң').size()
#жүҫеҲ°з»“жһңжңҖеӨҡзҡ„з»“жһң
maxValue = cnt[cnt == cnt.max()].index[0]
return maxValue
else:
A1 = copy.deepcopy(A)
attr = Choose(D, A1[:-1])
tree = {attr:{}}
for value in set(D[attr]):
tree[attr][value] = TreeGen(D[D[attr] == value], A1)
return tree
"""
@description :йӘҢиҜҒйӣҶ
---------
@param :иҫ“е…Ҙдёәеҫ…йӘҢиҜҒзҡ„ж•°жҚ®(жңҖеҗҺдёҖеҲ—дёәзңҹе®һз»“жһң)д»ҘеҸҠеҶізӯ–ж ‘жЁЎеһӢ
-------
@Returns :ж—
-------
"""
def Test(D:pd.DataFrame, model:dict):
for i in range(D.shape[0]):
data = D.iloc[i]
subModel = model
while(1):
attr = list(subModel)[0]
subModel = subModel[attr][data[attr]]
if(type(subModel).__name__ != 'dict'):
print(subModel, end='')
break
print('')
name = ['иүІжіҪ', 'ж №и’Ӯ', 'ж•ІеЈ°', 'зә№зҗҶ', 'и„җйғЁ', 'и§Ұж„ҹ', 'еҘҪз“ң']
df = pd.read_csv('./savedata.txt', names=name)
# CalcZengYi(df, 'иүІжіҪ')
resultTree = TreeGen(df, name)
print(resultTree)
# print(df[name[:-1]])
Test(df[name[:-1]], resultTree)
treeplot.plot_model(resultTree,"resultTree.gv")з»ҳеӣҫзЁӢеәҸ
from graphviz import Digraph
def plot_model(tree, name):
g = Digraph("G", filename=name, format='png', strict=False)
first_label = list(tree.keys())[0]
g.node("0", first_label)
_sub_plot(g, tree, "0")
g.view()
root = "0"
def _sub_plot(g, tree, inc):
global root
first_label = list(tree.keys())[0]
ts = tree[first_label]
for i in ts.keys():
if isinstance(tree[first_label][i], dict):
root = str(int(root) + 1)
g.node(root, list(tree[first_label][i].keys())[0])
g.edge(inc, root, str(i))
_sub_plot(g, tree[first_label][i], root)
else:
root = str(int(root) + 1)
g.node(root, tree[first_label][i])
g.edge(inc, root, str(i))./savedata.txt
йқ’з»ҝ,иң·зј©,жөҠе“Қ,жё…жҷ°,еҮ№йҷ·,зЎ¬ж»‘,жҳҜ
д№Ңй»‘,иң·зј©,жІүй—·,жё…жҷ°,еҮ№йҷ·,зЎ¬ж»‘,жҳҜ
д№Ңй»‘,иң·зј©,жөҠе“Қ,жё…жҷ°,еҮ№йҷ·,зЎ¬ж»‘,жҳҜ
йқ’з»ҝ,иң·зј©,жІүй—·,жё…жҷ°,еҮ№йҷ·,зЎ¬ж»‘,жҳҜ
жө…зҷҪ,иң·зј©,жөҠе“Қ,жё…жҷ°,еҮ№йҷ·,зЎ¬ж»‘,жҳҜ
йқ’з»ҝ,зЁҚиң·,жөҠе“Қ,жё…жҷ°,зЁҚеҮ№,иҪҜзІҳ,жҳҜ
д№Ңй»‘,зЁҚиң·,жөҠе“Қ,зЁҚзіҠ,зЁҚеҮ№,иҪҜзІҳ,жҳҜ
д№Ңй»‘,зЁҚиң·,жөҠе“Қ,жё…жҷ°,зЁҚеҮ№,зЎ¬ж»‘,жҳҜ
д№Ңй»‘,зЁҚиң·,жІүй—·,зЁҚзіҠ,зЁҚеҮ№,зЎ¬ж»‘,еҗҰ
йқ’з»ҝ,зЎ¬жҢә,жё…и„Ҷ,жё…жҷ°,е№іеқҰ,иҪҜзІҳ,еҗҰ
жө…зҷҪ,зЎ¬жҢә,жё…и„Ҷ,жЁЎзіҠ,е№іеқҰ,зЎ¬ж»‘,еҗҰ
жө…зҷҪ,иң·зј©,жөҠе“Қ,жЁЎзіҠ,е№іеқҰ,иҪҜзІҳ,еҗҰ
йқ’з»ҝ,зЁҚиң·,жөҠе“Қ,зЁҚзіҠ,еҮ№йҷ·,зЎ¬ж»‘,еҗҰ
жө…зҷҪ,зЁҚиң·,жІүй—·,зЁҚзіҠ,еҮ№йҷ·,зЎ¬ж»‘,еҗҰ
д№Ңй»‘,зЁҚиң·,жөҠе“Қ,жё…жҷ°,зЁҚеҮ№,иҪҜзІҳ,еҗҰ
жө…зҷҪ,иң·зј©,жөҠе“Қ,жЁЎзіҠ,е№іеқҰ,зЎ¬ж»‘,еҗҰ
йқ’з»ҝ,иң·зј©,жІүй—·,зЁҚзіҠ,зЁҚеҮ№,зЎ¬ж»‘,еҗҰ
е…ӯгҖҒйҒҮеҲ°зҡ„й—®йўҳ
graphviz Not a directory: вҖҳdot'
и§ЈеҶіеҠһжі•

дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„еҰӮдҪ•еңЁPythonдёӯдҪҝз”ЁеҶізӯ–ж ‘дәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





