Celery-дёҖдёӘдјҡеҒҡејӮжӯҘд»»еҠЎ,е®ҡж—¶д»»еҠЎзҡ„иҠ№иҸң
Celery еҲҶеёғејҸд»»еҠЎйҳҹеҲ—
еҗҢжӯҘдёҺејӮжӯҘ
жҜ”еҰӮиҜҙдҪ иҰҒеҺ»дёҖдёӘйӨҗеҺ…еҗғйҘӯ,дҪ зӮ№е®ҢиҸңд»ҘеҗҺеҒҮи®ҫжңҚеҠЎе‘ҳе‘ҠиҜүдҪ ,дҪ зӮ№зҡ„иҸң,иҰҒдёӨдёӘе°Ҹж—¶жүҚиғҪеҒҡе®Ң,иҝҷдёӘж—¶еҖҷдҪ еҸҜд»ҘжңүдёӨдёӘйҖүжӢ©
- дёҖзӣҙеңЁйӨҗеҺ…зӯүзқҖйҘӯиҸңдёҠжЎҢ
- дҪ еҸҜд»Ҙеӣһ家зӯүзқҖ,иҝҷдёӘж—¶еҖҷдҪ е°ұеҸҜд»ҘжҠҠдҪ зҡ„з”өиҜқз•ҷз»ҷжңҚеҠЎе‘ҳ,е‘ҠиҜүжңҚеҠЎе‘ҳзӯүд»Җд№Ҳж—¶еҖҷдҪ зҡ„йҘӯиҸңдёҠжЎҢдәҶ,еңЁз»ҷдҪ жү“з”өиҜқ
вҖӢ жүҖи°“еҗҢжӯҘе°ұжҳҜдёҖдёӘд»»еҠЎзҡ„е®ҢжҲҗйңҖиҰҒдҫқиө–еҸҰеӨ–дёҖдёӘд»»еҠЎж—¶пјҢеҸӘжңүзӯүеҫ…иў«дҫқиө–зҡ„д»»еҠЎе®ҢжҲҗеҗҺпјҢдҫқиө–зҡ„д»»еҠЎжүҚиғҪз®—е®ҢжҲҗпјҢиҝҷжҳҜдёҖз§ҚеҸҜйқ зҡ„д»»еҠЎеәҸеҲ—гҖӮиҰҒд№ҲжҲҗеҠҹйғҪжҲҗеҠҹпјҢеӨұиҙҘйғҪеӨұиҙҘпјҢдёӨдёӘд»»еҠЎзҡ„зҠ¶жҖҒеҸҜд»ҘдҝқжҢҒдёҖиҮҙгҖӮ
вҖӢ жүҖи°“ејӮжӯҘжҳҜдёҚйңҖиҰҒзӯүеҫ…иў«дҫқиө–зҡ„д»»еҠЎе®ҢжҲҗпјҢеҸӘжҳҜйҖҡзҹҘиў«дҫқиө–зҡ„д»»еҠЎиҰҒе®ҢжҲҗд»Җд№Ҳе·ҘдҪңпјҢдҫқиө–зҡ„д»»еҠЎд№ҹз«ӢеҚіжү§иЎҢпјҢеҸӘиҰҒиҮӘе·ұе®ҢжҲҗдәҶж•ҙдёӘд»»еҠЎе°ұз®—е®ҢжҲҗдәҶиҮідәҺиў«дҫқиө–зҡ„д»»еҠЎжңҖз»ҲжҳҜеҗҰзңҹжӯЈе®ҢжҲҗпјҢдҫқиө–е®ғзҡ„д»»еҠЎж— жі•зЎ®е®ҡпјҢжүҖд»Ҙе®ғжҳҜдёҚеҸҜйқ зҡ„д»»еҠЎеәҸеҲ—гҖӮ
йҳ»еЎһдёҺйқһйҳ»еЎһ
继з»ӯдёҠйқўзҡ„дҫӢеӯҗ
- дёҚз®ЎдҪ зҡ„еңЁйӨҗеҺ…зӯүзқҖиҝҳжҳҜеӣһ家зӯүзқҖ,иҝҷдёӘжңҹй—ҙдҪ зҡ„йғҪдёҚиғҪе№ІеҲ«зҡ„дәӢ,йӮЈд№ҲиҜҘжңәеҲ¶е°ұжҳҜйҳ»еЎһзҡ„пјҢиЎЁзҺ°еңЁзЁӢеәҸдёӯ,д№ҹе°ұжҳҜиҜҘзЁӢеәҸдёҖзӣҙйҳ»еЎһеңЁиҜҘеҮҪж•°и°ғз”ЁеӨ„дёҚиғҪ继з»ӯеҫҖдёӢжү§иЎҢгҖӮ
- дҪ еӣһ家д»ҘеҗҺе°ұеҸҜд»ҘеҺ»еҒҡеҲ«зҡ„дәӢдәҶ,дёҖйҒҚеҒҡеҲ«зҡ„дәӢ,дёҖиҲ¬еҺ»зӯүеҫ…жңҚеҠЎе‘ҳзҡ„з”өиҜқ,иҝҷж ·зҡ„зҠ¶жҖҒе°ұжҳҜйқһйҳ»еЎһзҡ„пјҢеӣ дёәдҪ (зӯүеҫ…иҖ…)жІЎжңүйҳ»еЎһеңЁиҝҷдёӘж¶ҲжҒҜйҖҡзҹҘдёҠпјҢиҖҢжҳҜдёҖиҫ№еҒҡиҮӘе·ұзҡ„дәӢжғ…дёҖиҫ№зӯүеҫ…гҖӮ
вҖӢ йҳ»еЎһе’Ңйқһйҳ»еЎһиҝҷдёӨдёӘжҰӮеҝөдёҺзЁӢеәҸпјҲзәҝзЁӢпјүзӯүеҫ…ж¶ҲжҒҜйҖҡзҹҘ(ж— жүҖи°“еҗҢжӯҘжҲ–иҖ…ејӮжӯҘ)ж—¶зҡ„зҠ¶жҖҒжңүе…ігҖӮд№ҹе°ұжҳҜиҜҙйҳ»еЎһдёҺйқһйҳ»еЎһдё»иҰҒжҳҜзЁӢеәҸпјҲзәҝзЁӢпјүзӯүеҫ…ж¶ҲжҒҜйҖҡзҹҘж—¶зҡ„зҠ¶жҖҒи§’еәҰжқҘиҜҙзҡ„
еҗҢжӯҘ/ејӮжӯҘдёҺйҳ»еЎһ/йқһйҳ»еЎһ
еҗҢжӯҘйҳ»еЎһеҪўејҸ
гҖҖгҖҖж•ҲзҺҮжңҖдҪҺгҖӮжӢҝдёҠйқўзҡ„дҫӢеӯҗжқҘиҜҙпјҢе°ұжҳҜдҪ дё“еҝғзҡ„еңЁйӨҗйҰҶзӯүзқҖпјҢд»Җд№ҲеҲ«зҡ„дәӢйғҪдёҚеҒҡгҖӮ
ејӮжӯҘйҳ»еЎһеҪўејҸ
гҖҖгҖҖеңЁе®¶йҮҢзӯүеҫ…зҡ„иҝҮзЁӢдёӯпјҢдҪ дёҖзӣҙзӣҜзқҖжүӢжңә,дёҚеҺ»еҒҡе…¶е®ғзҡ„дәӢжғ…пјҢйӮЈд№ҲеҫҲжҳҫ然пјҢдҪ иў«йҳ»еЎһеңЁдәҶиҝҷдёӘзӯүеҫ…зҡ„ж“ҚдҪңдёҠйқўпјӣ
гҖҖгҖҖејӮжӯҘж“ҚдҪңжҳҜеҸҜд»Ҙиў«йҳ»еЎһдҪҸзҡ„пјҢеҸӘдёҚиҝҮе®ғдёҚжҳҜеңЁеӨ„зҗҶж¶ҲжҒҜж—¶йҳ»еЎһпјҢиҖҢжҳҜеңЁзӯүеҫ…ж¶ҲжҒҜйҖҡзҹҘж—¶иў«йҳ»еЎһгҖӮ
еҗҢжӯҘйқһйҳ»еЎһеҪўејҸ
гҖҖгҖҖе®һйҷ…дёҠжҳҜж•ҲзҺҮдҪҺдёӢзҡ„гҖӮ
гҖҖгҖҖжғіиұЎдёҖдёӢдҪ еҰӮжһңе®іжҖ•жңҚеҠЎе‘ҳеҝҳи®°з»ҷдҪ жү“з”өиҜқйҖҡзҹҘдҪ пјҢдҪ иҝҮдёҖдјҡе°ұиҰҒеҺ»йӨҗеҺ…зңӢдёҖдёӢдҪ зҡ„йҘӯиҸңеҘҪдәҶжІЎжңү,жІЎеҘҪ ,еңЁеӣһ家зӯүеҫ…,иҝҮдёҖдјҡеҶҚеҺ»зңӢдёҖзңј,жІЎеҘҪеҶҚеӣһ家зӯүзқҖ,йӮЈд№Ҳж•ҲзҺҮеҸҜжғіиҖҢзҹҘжҳҜдҪҺдёӢзҡ„гҖӮ
ејӮжӯҘйқһйҳ»еЎһеҪўејҸ
вҖӢ жҜ”еҰӮиҜҙдҪ еӣһ家д»ҘеҗҺе°ұзӣҙжҺҘзңӢз”өи§ҶдәҶ,жҠҠжүӢжңәж”ҫеңЁдёҖиҫ№,зӯүд»Җд№Ҳж—¶еҖҷз”өиҜқе“ҚдәҶ,дҪ еңЁеҺ»жҺҘз”өиҜқ.иҝҷе°ұжҳҜејӮжӯҘйқһйҳ»еЎһеҪўејҸ,еӨ§е®¶жғідёҖдёӢиҝҷж ·жҳҜдёҚжҳҜж•ҲзҺҮжҳҜжңҖй«ҳзҡ„гҖҖгҖҖ
вҖӢ йӮЈд№ҲеҗҢжӯҘдёҖе®ҡжҳҜйҳ»еЎһзҡ„еҗ—?ејӮжӯҘдёҖе®ҡжҳҜйқһйҳ»еЎһзҡ„еҗ—?
з”ҹдә§иҖ…ж¶Ҳиҙ№иҖ…жЁЎеһӢ
еңЁе®һйҷ…зҡ„иҪҜ件ејҖеҸ‘иҝҮзЁӢдёӯпјҢз»Ҹеёёдјҡзў°еҲ°еҰӮдёӢеңәжҷҜпјҡжҹҗдёӘжЁЎеқ—иҙҹиҙЈдә§з”ҹж•°жҚ®пјҢиҝҷдәӣж•°жҚ®з”ұеҸҰдёҖдёӘжЁЎеқ—жқҘиҙҹиҙЈеӨ„зҗҶпјҲжӯӨеӨ„зҡ„жЁЎеқ—жҳҜе№ҝд№үзҡ„пјҢеҸҜд»ҘжҳҜзұ»гҖҒеҮҪж•°гҖҒзәҝзЁӢгҖҒиҝӣзЁӢзӯүпјүгҖӮдә§з”ҹж•°жҚ®зҡ„жЁЎеқ—пјҢе°ұеҪўиұЎең°з§°дёәз”ҹдә§иҖ…пјӣиҖҢеӨ„зҗҶж•°жҚ®зҡ„жЁЎеқ—пјҢе°ұз§°дёәж¶Ҳиҙ№иҖ…гҖӮ
еҚ•еҚ•жҠҪиұЎеҮәз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…пјҢиҝҳеӨҹдёҚдёҠжҳҜз”ҹдә§иҖ…ж¶Ҳиҙ№иҖ…жЁЎејҸгҖӮиҜҘжЁЎејҸиҝҳйңҖиҰҒжңүдёҖдёӘзј“еҶІеҢәеӨ„дәҺз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…д№Ӣй—ҙпјҢдҪңдёәдёҖдёӘдёӯд»ӢгҖӮз”ҹдә§иҖ…жҠҠж•°жҚ®ж”ҫе…Ҙзј“еҶІеҢәпјҢиҖҢж¶Ҳиҙ№иҖ…д»Һзј“еҶІеҢәеҸ–еҮәж•°жҚ®пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
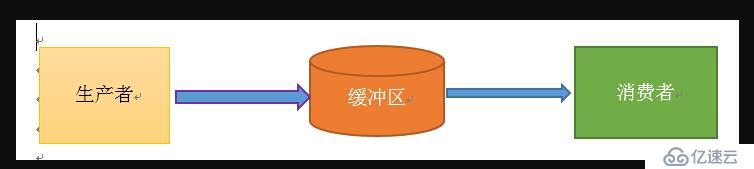
з”ҹдә§иҖ…ж¶Ҳиҙ№иҖ…жЁЎејҸжҳҜйҖҡиҝҮдёҖдёӘе®№еҷЁжқҘи§ЈеҶіз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…зҡ„ејәиҖҰеҗҲй—®йўҳгҖӮз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…еҪјжӯӨд№Ӣй—ҙдёҚзӣҙжҺҘйҖҡи®ҜпјҢиҖҢйҖҡиҝҮж¶ҲжҒҜйҳҹеҲ—пјҲзј“еҶІеҢәпјүжқҘиҝӣиЎҢйҖҡи®ҜпјҢжүҖд»Ҙз”ҹдә§иҖ…з”ҹдә§е®Ңж•°жҚ®д№ӢеҗҺдёҚз”Ёзӯүеҫ…ж¶Ҳиҙ№иҖ…еӨ„зҗҶпјҢзӣҙжҺҘжү”з»ҷж¶ҲжҒҜйҳҹеҲ—пјҢж¶Ҳиҙ№иҖ…дёҚжүҫз”ҹдә§иҖ…иҰҒж•°жҚ®пјҢиҖҢжҳҜзӣҙжҺҘд»Һж¶ҲжҒҜйҳҹеҲ—йҮҢеҸ–пјҢж¶ҲжҒҜйҳҹеҲ—е°ұзӣёеҪ“дәҺдёҖдёӘзј“еҶІеҢәпјҢе№іиЎЎдәҶз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…зҡ„еӨ„зҗҶиғҪеҠӣгҖӮиҝҷдёӘж¶ҲжҒҜйҳҹеҲ—е°ұжҳҜз”ЁжқҘз»ҷз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…и§ЈиҖҰзҡ„гҖӮ------------->иҝҷйҮҢеҸҲжңүдёҖдёӘй—®йўҳпјҢд»Җд№ҲеҸ«еҒҡи§ЈиҖҰпјҹ
и§ЈиҖҰпјҡеҒҮи®ҫз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…еҲҶеҲ«жҳҜдёӨдёӘзұ»гҖӮеҰӮжһңи®©з”ҹдә§иҖ…зӣҙжҺҘи°ғз”Ёж¶Ҳиҙ№иҖ…зҡ„жҹҗдёӘж–№жі•пјҢйӮЈд№Ҳз”ҹдә§иҖ…еҜ№дәҺж¶Ҳиҙ№иҖ…е°ұдјҡдә§з”ҹдҫқиө–пјҲд№ҹе°ұжҳҜиҖҰеҗҲпјүгҖӮе°ҶжқҘеҰӮжһңж¶Ҳиҙ№иҖ…зҡ„д»Јз ҒеҸ‘з”ҹеҸҳеҢ–пјҢеҸҜиғҪдјҡеҪұе“ҚеҲ°з”ҹдә§иҖ…гҖӮиҖҢеҰӮжһңдёӨиҖ…йғҪдҫқиө–дәҺжҹҗдёӘзј“еҶІеҢәпјҢдёӨиҖ…д№Ӣй—ҙдёҚзӣҙжҺҘдҫқиө–пјҢиҖҰеҗҲд№ҹе°ұзӣёеә”йҷҚдҪҺдәҶгҖӮз”ҹдә§иҖ…зӣҙжҺҘи°ғз”Ёж¶Ҳиҙ№иҖ…зҡ„жҹҗдёӘж–№жі•пјҢиҝҳжңүеҸҰдёҖдёӘејҠз«ҜгҖӮз”ұдәҺеҮҪж•°и°ғз”ЁжҳҜеҗҢжӯҘзҡ„пјҲжҲ–иҖ…еҸ«йҳ»еЎһзҡ„пјүпјҢеңЁж¶Ҳиҙ№иҖ…зҡ„ж–№жі•жІЎжңүиҝ”еӣһд№ӢеүҚпјҢз”ҹдә§иҖ…еҸӘеҘҪдёҖзӣҙзӯүеңЁйӮЈиҫ№гҖӮдёҮдёҖж¶Ҳиҙ№иҖ…еӨ„зҗҶж•°жҚ®еҫҲж…ўпјҢз”ҹдә§иҖ…е°ұдјҡзҷҪзҷҪзіҹи№ӢеӨ§еҘҪж—¶е…үгҖӮзј“еҶІеҢәиҝҳжңүеҸҰдёҖдёӘеҘҪеӨ„гҖӮеҰӮжһңеҲ¶йҖ ж•°жҚ®зҡ„йҖҹеәҰж—¶еҝ«ж—¶ж…ўпјҢзј“еҶІеҢәзҡ„еҘҪеӨ„е°ұдҪ“зҺ°еҮәжқҘдәҶгҖӮеҪ“ж•°жҚ®еҲ¶йҖ еҝ«зҡ„ж—¶еҖҷпјҢж¶Ҳиҙ№иҖ…жқҘдёҚеҸҠеӨ„зҗҶпјҢжңӘеӨ„зҗҶзҡ„ж•°жҚ®еҸҜд»ҘжҡӮж—¶еӯҳеңЁзј“еҶІеҢәдёӯгҖӮзӯүз”ҹдә§иҖ…зҡ„еҲ¶йҖ йҖҹеәҰж…ўдёӢжқҘпјҢж¶Ҳиҙ№иҖ…еҶҚж…ўж…ўеӨ„зҗҶжҺүгҖӮ
еӣ дёәеӨӘжҠҪиұЎпјҢзңӢиҝҮзҪ‘дёҠзҡ„иҜҙжҳҺд№ӢеҗҺпјҢйҖҡиҝҮжҲ‘зҡ„зҗҶи§ЈпјҢжҲ‘дёҫдәҶдёӘдҫӢеӯҗпјҡеҗғеҢ…еӯҗгҖӮ
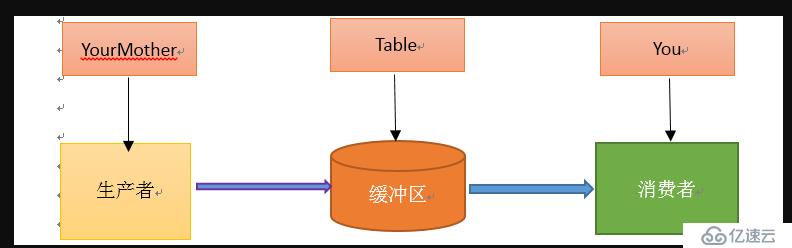
еҒҮеҰӮдҪ йқһеёёе–ңж¬ўеҗғеҢ…еӯҗпјҲеҗғиө·жқҘж №жң¬еҒңдёҚдёӢжқҘпјүпјҢд»ҠеӨ©пјҢдҪ еҰҲеҰҲпјҲз”ҹдә§иҖ…пјүеңЁи’ёеҢ…еӯҗпјҢеҺЁжҲҝжңүеј жЎҢеӯҗпјҲзј“еҶІеҢәпјүпјҢдҪ еҰҲеҰҲе°Ҷи’ёзҶҹзҡ„еҢ…еӯҗзӣӣеңЁзӣҳеӯҗпјҲж¶ҲжҒҜпјүйҮҢпјҢ然еҗҺж”ҫеҲ°жЎҢеӯҗдёҠпјҢдҪ жӯЈеңЁзңӢе·ҙиҘҝеҘҘиҝҗдјҡпјҢзңӢеҲ°и’ёзҶҹзҡ„еҢ…еӯҗж”ҫеңЁеҺЁжҲҝжЎҢеӯҗдёҠзҡ„зӣҳеӯҗйҮҢпјҢдҪ е°ұжҠҠзӣҳеӯҗеҸ–иө°пјҢдёҖиҫ№еҗғеҢ…еӯҗдёҖиҫ№зңӢеҘҘиҝҗгҖӮеңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢдҪ е’ҢдҪ еҰҲеҰҲдҪҝз”ЁеҗҢдёҖдёӘжЎҢеӯҗж”ҫзҪ®зӣҳеӯҗе’ҢеҸ–иө°зӣҳеӯҗпјҢиҝҷйҮҢжЎҢеӯҗе°ұжҳҜдёҖдёӘе…ұдә«еҜ№иұЎгҖӮз”ҹдә§иҖ…ж·»еҠ йЈҹзү©пјҢж¶Ҳиҙ№иҖ…еҸ–иө°йЈҹзү©гҖӮжЎҢеӯҗзҡ„еҘҪеӨ„жҳҜпјҢдҪ еҰҲеҰҲдёҚз”ЁзӣҙжҺҘжҠҠзӣҳеӯҗз»ҷдҪ пјҢеҸӘжҳҜиҙҹиҙЈжҠҠеҢ…еӯҗиЈ…еңЁзӣҳеӯҗйҮҢж”ҫеҲ°жЎҢеӯҗдёҠпјҢеҰӮжһңжЎҢеӯҗж»ЎдәҶпјҢе°ұдёҚеҶҚж”ҫдәҶпјҢзӯүеҫ…гҖӮиҖҢдё”з”ҹдә§иҖ…иҝҳжңүе…¶д»–дәӢжғ…иҰҒеҒҡпјҢж¶Ҳиҙ№иҖ…еҗғеҢ…еӯҗжҜ”иҫғж…ўпјҢз”ҹдә§иҖ…дёҚиғҪдёҖзӣҙзӯүж¶Ҳиҙ№иҖ…еҗғе®ҢеҢ…еӯҗжҠҠзӣҳеӯҗж”ҫеӣһеҺ»еҶҚеҺ»з”ҹдә§пјҢеӣ дёәеҗғеҢ…еӯҗзҡ„дәәжңүеҫҲеӨҡпјҢеҰӮжһңиҝҷжңҹй—ҙдҪ еҘҪжңӢеҸӢжқҘдәҶпјҢе’ҢдҪ дёҖиө·еҗғеҢ…еӯҗпјҢз”ҹдә§иҖ…дёҚз”Ёе…іжіЁжҳҜе“ӘдёӘж¶Ҳиҙ№иҖ…еҺ»жЎҢеӯҗдёҠжӢҝзӣҳеӯҗпјҢиҖҢж¶Ҳиҙ№иҖ…еҸӘеҺ»е…іжіЁжЎҢеӯҗдёҠжңүжІЎжңүж”ҫзӣҳеӯҗпјҢеҰӮжһңжңүпјҢе°ұз«ҜиҝҮжқҘеҗғзӣҳеӯҗдёӯзҡ„еҢ…еӯҗпјҢжІЎжңүзҡ„иҜқе°ұзӯүеҫ…гҖӮеҜ№еә”е…ізі»еҰӮдёӢеӣҫпјҡ
celery
з”ҹдә§иҖ…ж¶Ҳиҙ№иҖ…жЁЎеһӢ
ж¶Ҳиҙ№иҖ…
from celery import Celery
task=Celery('task',broker="redis://10.211.55.19:6379") #taskеҸҜд»ҘжҳҜд»»дҪ•еҗҚз§°,еҗҺйқўи·ҹзҡ„жҳҜйҳҹеҲ—зҡ„зј“еӯҳиҖ…,celeryдёӯдёҖиҲ¬з§°дёәдёӯй—ҙдәә,еҰӮжһңиҰҒжҳҜеҜҶз Ғи®ҝй—®зҡ„иҜқ,йңҖиҰҒжҳҜredis://:{pass}@IPең°еқҖ:з«ҜеҸЈ
@task.task
def add(a,b):
return a+b
еҗҜеҠЁ celeryд»Һ4.0зүҲжң¬д»ҘеҗҺе°ұдёҚеңЁж”ҜжҢҒwindowsдәҶ,еҰӮжһңжғіеңЁwindowsзҺҜеўғдёӢдҪҝз”Ёзҡ„иҜқ,йңҖиҰҒе®үиЈ…eventletиҝҷдёӘеҢ…,еҗҜеҠЁзҡ„ж—¶еҖҷйңҖиҰҒжҢҮе®ҡ-P eventlet
celery worker -A c -l info
з”ҹдә§иҖ…
from c import add
for i in range(10):
add.delay(1,2)
жЁЎжӢҹдёӨдёӘж¶Ҳиҙ№иҖ…
еңЁдёҚеҗҢзҡ„дҪҚзҪ®еңЁеҗҜеҠЁдёҖдёӘworkerж—ўеҸҜд»ҘдәҶ
celery worker -A c -l info
з”ҹдә§иҖ…ж¶Ҳиҙ№иҖ…жЁЎеһӢеҚҮзә§
ж¶Ҳиҙ№иҖ…
from celery import Celery
task=Celery('task',broker="redis://10.211.55.19:6379/0",backend="redis://10.211.55.19:6379/2")#brokerе’ҢbackendеҸҜд»ҘжҳҜдёҚеҗҢзҡ„йҳҹеҲ—,иҝҷйҮҢдҪҝз”ЁredisдёҚеҗҢзҡ„еә“жқҘжЁЎжӢҹдёҚеҗҢзҡ„йҳҹеҲ—,еҪ“然д№ҹеҸҜд»ҘдёҖж ·
@task.task
def add(a,b):
return a+b
еҗҜеҠЁиҝҮзЁӢи·ҹдёҠйқўдёҖж ·
з”ҹдә§иҖ…
from c import add
for i in range(10):
t=add.delay(i,2)
print(t.get()) #иҺ·еҸ–з»“жһң
зҷ»еҪ•redisжҹҘзңӢдҝЎжҒҜ
redis-cli
127.0.0.1:6379[1]> SELECT 2
127.0.0.1:6379[2]> KEYS *
127.0.0.1:6379[2]> get celery-task-meta-6c8dda5e-c8a3-4f5f-8c2b-e7541aafdc42
"{\"status\": \"SUCCESS\", \"result\": 3, \"traceback\": null, \"children\": [], \"task_id\": \"6c8dda5e-c8a3-4f5f-8c2b-e7541aafdc42\"}"
## и§Јжһҗж•°жҚ®
d="{\"status\": \"SUCCESS\", \"result\": 3, \"traceback\": null, \"children\": [], \"task_id\": \"6c8dda5e-c8a3-4f5f-8c2b-e7541aafdc42\"}"
import json
print(json.loads(d))
иҺ·еҸ–жү§иЎҢзҠ¶жҖҒ
еҖҳиӢҘд»»еҠЎжҠӣеҮәдәҶдёҖдёӘејӮеёёпјҢ get() дјҡйҮҚж–°жҠӣеҮәејӮеёёпјҢ дҪҶдҪ еҸҜд»ҘжҢҮе®ҡ propagate еҸӮж•°жқҘиҰҶзӣ–иҝҷдёҖиЎҢдёә:
result.get(propagate=False)
еҰӮжһңд»»еҠЎжҠӣеҮәдәҶдёҖдёӘејӮеёёпјҢдҪ д№ҹеҸҜд»ҘиҺ·еҸ–еҺҹе§Ӣзҡ„еӣһжәҜдҝЎжҒҜ:
result.tracebackвҖҰ
print(t)
print(t.ready())
print(t.get())
print(t.ready())
е®ҡж—¶д»»еҠЎ
apply_async
t=add.apply_async((1,2),countdown=5) #иЎЁзӨә延иҝҹ5з§’й’ҹжү§иЎҢд»»еҠЎ
print(t)
print(t.get())
й—®йўҳ:жҳҜ延иҝҹ5з§’еҸ‘йҖҒиҝҳжҳҜз«ӢеҚіеҸ‘йҖҒ,ж¶Ҳиҙ№иҖ…延иҝҹ5з§’еңЁжү§иЎҢйӮЈ?
ж”ҜжҢҒзҡ„еҸӮж•° :
-
countdown : зӯүеҫ…дёҖж®өж—¶й—ҙеҶҚжү§иЎҢ.
add.apply_async((2,3), countdown=5)
-
eta : е®ҡд№үд»»еҠЎзҡ„ејҖе§Ӣж—¶й—ҙ.иҝҷйҮҢзҡ„ж—¶й—ҙжҳҜUTCж—¶й—ҙ,иҝҷйҮҢжңүеқ‘
add.apply_async((2,3), eta=now+tiedelta(second=10))
-
expires : и®ҫзҪ®и¶…ж—¶ж—¶й—ҙ.
add.apply_async((2,3), expires=60)
-
retry : е®ҡж—¶еҰӮжһңд»»еҠЎеӨұиҙҘеҗҺ, жҳҜеҗҰйҮҚиҜ•.
add.apply_async((2,3), retry=False)
-
retry_policy : йҮҚиҜ•зӯ–з•Ҙ.
- max_retries : жңҖеӨ§йҮҚиҜ•ж¬Ўж•°, й»ҳи®Өдёә 3 ж¬Ў.
- interval_start : йҮҚиҜ•зӯүеҫ…зҡ„ж—¶й—ҙй—ҙйҡ”з§’ж•°, й»ҳи®Өдёә 0 , иЎЁзӨәзӣҙжҺҘйҮҚиҜ•дёҚзӯүеҫ….
- interval_step : жҜҸж¬ЎйҮҚиҜ•и®©йҮҚиҜ•й—ҙйҡ”еўһеҠ зҡ„з§’ж•°, еҸҜд»ҘжҳҜж•°еӯ—жҲ–жө®зӮ№ж•°, й»ҳи®Өдёә 0.2
- interval_max : йҮҚиҜ•й—ҙйҡ”жңҖеӨ§зҡ„з§’ж•°, еҚі йҖҡиҝҮ interval_step еўһеӨ§еҲ°еӨҡе°‘з§’д№ӢеҗҺ, е°ұдёҚеңЁеўһеҠ дәҶ, еҸҜд»ҘжҳҜж•°еӯ—жҲ–иҖ…жө®зӮ№ж•°, й»ҳи®Өдёә 0.2 .
е‘Ёжңҹд»»еҠЎ
from c import task
task.conf.beat_schedule={
timezone='Asia/Shanghai',
"each20s_task":{
"task":"c.add",
"schedule":3, # жҜҸ3з§’й’ҹжү§иЎҢдёҖж¬Ў
"args":(10,10)
},
}
е…¶е®һceleryд№ҹж”ҜжҢҒlinuxйҮҢйқўзҡ„crontabж јејҸзҡ„д№ҰеҶҷзҡ„
from celery.schedules import crontab
task.conf.beat_schedule={
timezone='Asia/Shanghai',
"each4m_task":{
"task":"c.add",
"schedule":crontab(minute=3), #жҜҸе°Ҹж—¶зҡ„第3еҲҶй’ҹжү§иЎҢ
"args":(10,10)
},
"each4m_task":{
"task":"c.add",
"schedule":crontab(minute=*/3), #жҜҸе°Ҹж—¶зҡ„第3еҲҶй’ҹжү§иЎҢ
"args":(10,10)
},
}
еҗҺеҸ°еҗҜеҠЁ
worker:
celery multi start worker1 \
-A c \
--pidfile="$HOME/run/celery/%n.pid" \
--logfile="$HOME/log/celery/%n%I.log"
celery multi restart worker1 \
-A proj \
--logfile="$HOME/log/celery/%n%I.log" \
--pidfile="$HOME/run/celery/%n.pid
celery multi stopwait worker1 --pidfile="$HOME/run/celery/%n.pid"
beat:
celery -A d beat --detach -l info -f beat.log
дёҺdjangoз»“еҗҲ
1.жү§иЎҢејӮжӯҘд»»еҠЎ
1.1 еңЁз”ҹжҲҗзҡ„зӣ®еҪ•ж–Ү件дёӯж·»еҠ celeryж–Ү件,еҶ…е®№еҰӮдёӢ
from __future__ import absolute_import, unicode_literals
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'tests.settings') #дёҺйЎ№зӣ®е…іиҒ”
app = Celery('tests',backend='redis://10.211.55.19/3',broker='redis://10.211.55.19/4')
#еҲӣе»әceleryеҜ№иұЎ
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')
#еңЁdjangoдёӯеҲӣе»әceleryзҡ„е‘ҪеҗҚз©әй—ҙ
# Load task modules from all registered Django app configs.
app.autodiscover_tasks()
#иҮӘеҠЁеҠ иҪҪд»»еҠЎ
1.2зј–иҫ‘settings.pyеҗҢзә§зӣ®еҪ•зҡ„init.py
from __future__ import absolute_import, unicode_literals
from .celery import app as celery_app
__all__ = ['celery_app']
1.3 еңЁйЎ№зӣ®дёӯж·»еҠ tasksж–Ү件,з”ЁжқҘдҝқеӯҳtasksзҡ„ж–Ү件
from celery import shared_task
@shared_task
def add(x, y):
return x + y
@shared_task
def mul(x, y):
return x * y
@shared_task
def xsum(numbers):
return sum(numbers)
1.4ж·»еҠ viewsж–Ү件еҶ…е®№
from .tasks import add
def index(request):
result = add.delay(2, 3)
return HttpResponse('иҝ”еӣһж•°жҚ®{}'.format(result.get()))
1.5 еҗҜеҠЁworker
celery -A tests worker -l info
1.6ж·»еҠ url并и°ғз”Ё
2.жү§иЎҢе‘ЁжңҹжҖ§д»»еҠЎ
2.1йңҖиҰҒе®үиЈ…дёҖдёӘdjangoзҡ„组件жқҘе®ҢжҲҗиҝҷдёӘдәӢжғ…
pip install django-celery-beat
2.2е°Ҷdjango-celery-beatж·»еҠ еҲ°INSTALLED_APPSйҮҢйқў
INSTALLED_APPS = (
...,
'django_celery_beat',
)
2.3еҲ·ж–°еҲ°ж•°жҚ®еә“
python3 manage.py makemigrations #дёҚжү§иЎҢиҝҷдёӘдјҡжңүй—®йўҳ
python3 manage.py migrate
2.4 adminй…ҚзҪ®
2.5еҗҜеҠЁbeat
celery -A tests beat -l info --scheduler django_celery_beat.schedulers:DatabaseScheduler
2.6 еҗҜеҠЁworker
celery -A tests worker -l info





