爬取猫眼电影TOP100(http://maoyan.com/board/4?offset=90)
1). 爬取内容: 电影名称,主演, 上映时间,图片url地址保存到文件中;
2). 文件名为topMovie.csv;
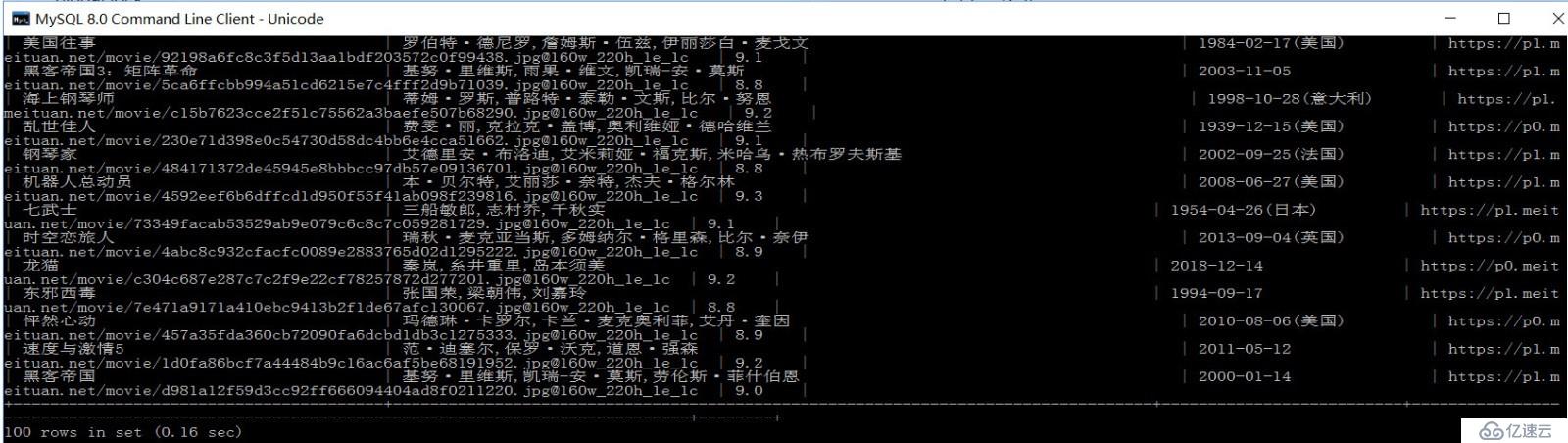
3). 记录方式: 电影名称:主演:上映时间:图片url地址:评分;
4). 并爬取的信息保存在数据库中;
5). 使用多线程/线城池实现;1.利用多线程分配任务
2.编写单线程的任务实现功能
(1)获取指定url页面信息。
(2)从指定信息中匹配所需的信息。
(3)将获取到的信息分别保存至文件并写入数据库中。from multiprocessing.pool import ThreadPool
def main():
# 需要访问10个分页,生成对应的urls列表
urls = [getPageInfo('https://maoyan.com/board/4?offset=%s' % i)for i in range(0,91,10)]
pool = ThreadPool(10) # 创建线程池对象,上限为10个
pool.map(getInfoInPage,urls) # 获取信息并保存至文件
pool.close() # 关闭线程池
pool.join() # 等待子线程结束# 获取页面信息
def getPageInfo(url):
pageObj = urlopen(url)
pageInfo = pageObj.read().decode('utf-8')
return pageInfopage = 0 # 定义全局变量便于分页存储
def savePageInfo(pageInfo):
global page
page += 1
with open('doc/moviePage%s'%(page),'w',encoding='utf-8')as f:
f.write(pageInfo)
return pageInfodef connetion():
return pymysql.connect(
host='localhost',
user='root',
password='mysql',
database='topMovie',
charset='utf8',
autocommit=True
)def getInfoInPage(page1):
# 将获取的html源码加工为美味汤(便于获取对应的信息)
soup = BeautifulSoup(page1, 'html.parser')
# 遍历单个页面中 class 为 content 的div标签
for page in soup.find_all('div', {'class': "content"}):
# 遍历content节点中的dd标签
for movie in page.find_all('dd'):
# 将soup节点转化成字符串
movieInfo = str(movie)
# 筛选出需要的信息
name = movie.find('p', {'class': "name"}).text # 获取电影名称
star = re.findall(r'主演:(.*?)\s', movieInfo)[0] # 获取主演
releaseTime = re.findall(r'上映时间:(.*?)<', movieInfo)[0] # 获取上映时间
imgUrl = re.findall(r'"(http.*?)"', movieInfo)[0] # 获取宣传图片地址
score = movie.find('p', {'class': "score"}).text # 获取评分
# 电影名称: 主演:上映时间: 图片url地址:评分;
oneMovieInfo = '\n{0}:{1}:{2}:{3}:{4}'.format(name, star, releaseTime, imgUrl, score)
# 写入文件
with open('doc/topMovie.csv', 'a+', encoding='utf-8')as f:
f.write(oneMovieInfo)
# 单个电影信息存入数据库的sql语句
insertSql = 'insert into topmovie(电影名称,主演,上映时间,图片地址,评分) value("{0}","{1}","{2}","{3}","{4}")'.format(name, star, releaseTime, imgUrl, score)
lock.acquire() # 加上线程锁,防止多线程公用连接出现问题
cur.execute(insertSql) # 执行插入语句
lock.release() # 解锁多线程公用数据库如果不进行安全处理,有时会因为
数据来不及回滚而其他线程进行数据操作,从而导致存储出现问题
可以通过一下几种方式调整:
1.让每个线程拥有自己的连接。
2.利用线程锁来保证单次操作的完整性。
这里采用第二种方式在属性插入语句前后进行加锁和解锁操作 lock.acquire() # 加上线程锁,防止多线程公用连接出现问题
cur.execute(insertSql) # 执行插入语句
lock.release() # 解锁def main():
with open('doc/topMovie.csv','w',encoding='utf-8')as f:
f.write('电影名称: 主演:上映时间: 图片url地址:评分;')
# 创建连接和游标
global cur
global lock
conn = connetion()
cur = conn.cursor()
lock = threading.Lock()
# 删除并创建一个新表(刷新每次写入的数据)
dropSql = 'drop table topMovie;'
cur.execute(dropSql)
createSql = 'create table topMovie(电影名称 varchar(100),主演 varchar(100),上映时间 varchar(100),图片地址 varchar(100),评分 varchar(100))default charset=utf8'
cur.execute(createSql)
# 生成分页的urls
urls = [getPageInfo('https://maoyan.com/board/4?offset=%s' % i)for i in range(0,91,10)]
# 实现多线程
pool = ThreadPool(10)
pool.map(getInfoInPage,urls) # 获取信息并保存至文件
# 关闭线程池并等待子线程结束
pool.close()
pool.join()
# 关闭游标和连接
cur.close()
conn.close()import re
import threading
import time
from multiprocessing.pool import ThreadPool
import pymysql
from bs4 import BeautifulSoup
from urllib.request import urlopen
# 获取页面信息
def getPageInfo(url):
pageObj = urlopen(url)
pageInfo = pageObj.read().decode('utf-8')
return pageInfo
page = 0
# 保存页面信息到文件moviePage
def savePageInfo(pageInfo):
global page
page += 1
with open('doc/moviePage%s'%(page),'w',encoding='utf-8')as f:
f.write(pageInfo)
return pageInfo
# 计时器
def timeCounter(fun):
def wrapper(*args,**kwargs):
startTime = time.time()
res = fun(*args,**kwargs)
endTime = time.time()
print(fun.__name__+'使用时间为%.2f'%(endTime-startTime))
return res
return wrapper
# 建立数据库连接
def connetion():
return pymysql.connect(
host='localhost',
user='root',
password='mysql',
database='topMovie',
charset='utf8',
autocommit=True
)
# 从单页源码中获取所需要的信息,并分别存至数据库和文件参数为页面源码(str)
def getInfoInPage(page1):
soup = BeautifulSoup(page1, 'html.parser')
for page in soup.find_all('div', {'class': "content"}):
for movie in page.find_all('dd'):
# 将soup节点转化成字符串
movieInfo = str(movie)
# 筛选出需要的信息
name = movie.find('p', {'class': "name"}).text
star = re.findall(r'主演:(.*?)\s', movieInfo)[0]
releaseTime = re.findall(r'上映时间:(.*?)<', movieInfo)[0]
imgUrl = re.findall(r'"(http.*?)"', movieInfo)[0]
score = movie.find('p', {'class': "score"}).text
# 电影名称: 主演:上映时间: 图片url地址:评分;
oneMovieInfo = '\n{0}:{1}:{2}:{3}:{4}'.format(name, star, releaseTime, imgUrl, score)
# 写入文件
with open('doc/topMovie.csv', 'a+', encoding='utf-8')as f:
f.write(oneMovieInfo)
# 存入数据库
insertSql = 'insert into topmovie(电影名称,主演,上映时间,图片地址,评分) value("{0}","{1}","{2}","{3}","{4}")'.format(name, star, releaseTime, imgUrl, score)
lock.acquire()
cur.execute(insertSql)
lock.release()
print(oneMovieInfo)
@timeCounter
def main():
with open('doc/topMovie.csv','w',encoding='utf-8')as f:
f.write('电影名称: 主演:上映时间: 图片url地址:评分;')
# 创建连接和游标
conn = connetion()
global cur
cur = conn.cursor()
global lock
lock = threading.Lock()
# 创建一个新表
dropSql = 'drop table topMovie;'
cur.execute(dropSql)
createSql = 'create table topMovie(电影名称 varchar(100),主演 varchar(100),上映时间 varchar(100),图片地址 varchar(100),评分 varchar(100))default charset=utf8'
cur.execute(createSql)
urls = [getPageInfo('https://maoyan.com/board/4?offset=%s' % i)for i in range(0,91,10)]
pool = ThreadPool(10)
# pool.map(savePageInfo,urls)
pool.map(getInfoInPage,urls) # 获取信息并保存至文件
pool.close()
pool.join()
cur.close()
conn.close()

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





