Javaд»Јз ҒжҳҜеҰӮдҪ•еңЁжңәеҷЁдёҠиҝҗиЎҢзҡ„
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңJavaд»Јз ҒжҳҜеҰӮдҪ•еңЁжңәеҷЁдёҠиҝҗиЎҢзҡ„вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
жҰӮи§Ҳ
и®Ўз®—жңәиғҪиҜҶеҲ«зҡ„жҳҜжңәеҷЁжҢҮд»Өз ҒпјҢз®Җз§°жңәеҷЁз ҒгҖӮжңәеҷЁз ҒжҳҜдәҢиҝӣеҲ¶зҡ„пјҢи®Ўз®—жңәеҸҜд»ҘзӣҙжҺҘиҜҶеҲ«пјҢдҪҶдёҺдәәзұ»зҡ„иҜӯиЁҖе·®еҲ«еӨӘеӨ§пјҢдёҚе®№жҳ“иў«дәәзҗҶи§Је’Ңи®°еҝҶгҖӮеҗҺжқҘпјҢе°ұиҜһз”ҹдәҶеҗ„з§Қй«ҳзә§иҜӯиЁҖпјҢдәә们用й«ҳзә§иҜӯиЁҖзј–еҶҷзЁӢеәҸпјҢ然еҗҺйҖҡиҝҮжҠҠзЁӢеәҸи§ЈйҮҠжҲ–зј–иҜ‘жҲҗжңәеҷЁз ҒгҖӮ
жҜ”еҰӮpythonпјҢе°ұжҳҜдёҖз§Қи§ЈйҮҠеһӢиҜӯиЁҖгҖӮPythonзЁӢеәҸжәҗз ҒдёҚйңҖиҰҒзј–иҜ‘пјҢеҸҜд»ҘзӣҙжҺҘд»Һжәҗд»Јз ҒиҝҗиЎҢзЁӢеәҸгҖӮPythonи§ЈйҮҠеҷЁе°Ҷжәҗд»Јз ҒиҪ¬жҚўдёәеӯ—иҠӮз ҒпјҢ然еҗҺжҠҠзј–иҜ‘еҘҪзҡ„еӯ—иҠӮз ҒиҪ¬еҸ‘еҲ°PythonиҷҡжӢҹжңә(PVM)дёӯиҝӣиЎҢжү§иЎҢгҖӮ
иҖҢCиҜӯиЁҖе°ұжҳҜе…ёеһӢзҡ„зј–иҜ‘еһӢиҜӯиЁҖпјҢйңҖиҰҒе…Ҳз”Ёзј–иҜ‘еҷЁзј–иҜ‘жҲҗжңәеҷЁз ҒпјҢжҜ”еҰӮжҲ‘们йҖҡеёёз”ЁgccжқҘзј–иҜ‘CиҜӯиЁҖзЁӢеәҸпјҡ
$ gcc hello.c # зј–иҜ‘ $ ./a.out # жү§иЎҢ hello world!
йӮЈJavaжҳҜи§ЈйҮҠеһӢиҜӯиЁҖиҝҳжҳҜзј–иҜ‘еһӢиҜӯиЁҖе‘ў?
гҖҢJavaжҳҜе…је…·зј–иҜ‘еһӢиҜӯиЁҖдёҺи§ЈйҮҠеһӢиҜӯиЁҖзҡ„зү№зӮ№зҡ„гҖҚгҖӮзЁӢеәҸе‘ҳеҶҷеҘҪJavaзЁӢеәҸеҗҺпјҢйңҖиҰҒе…Ҳз”Ёjavacзј–иҜ‘жҲҗJVMеҸҜд»ҘдҪҝз”Ёзҡ„еӯ—иҠӮз Ғclassж–Ү件гҖӮ然еҗҺJVMеҠ иҪҪclassж–Ү件пјҢйҖҗжқЎи§ЈйҮҠжү§иЎҢгҖӮеңЁиҝҗиЎҢиҝҮзЁӢдёӯпјҢйғЁеҲҶзғӯзӮ№д»Јз Ғдјҡиў«еҚіж—¶зј–иҜ‘еҷЁзј–иҜ‘жҲҗжңәеҷЁз ҒгҖӮ
жәҗд»Јз ҒеҲ°еӯ—иҠӮз Ғ
JavaиҜӯиЁҖзҡ„жәҗд»Јз ҒжҳҜ.javaдёәеҗҺзјҖзҡ„ж–Ү件гҖӮеҪ“然зҺ°еңЁжңүеҫҲеӨҡе…¶е®ғй«ҳзә§иҜӯиЁҖд№ҹжһ¶жһ„еңЁJVMдёҠпјҢжҜ”еҰӮgroovyгҖҒkotlinзӯүгҖӮжәҗд»Јз ҒжҳҜз»ҷдәәзңӢзҡ„пјҢжҳ“дәҺйҳ…иҜ»гҖҒзҗҶи§ЈгҖҒз»ҙжҠӨгҖӮ
жәҗд»Јз Ғз»ҸиҝҮзј–иҜ‘еҗҺеҫ—еҲ°еӯ—иҠӮз ҒпјҢеӯ—иҠӮз ҒжҳҜз»ҷJVMз”Ёзҡ„пјҢжҳ“дәҺзҗҶи§Је’ҢиҜҶеҲ«гҖӮеӯ—иҠӮз ҒжҳҜд»Ҙ.classдёәеҗҺзјҖпјҢе…¶ж јејҸжҳҜJVMзҡ„дёҖеҘ—规еҲ’пјҢеӯ—иҠӮз Ғдәәзұ»еҜ№з…§ж–ҮжЎЈд№ҹжҳҜеӢүејәиғҪзңӢжҮӮзҡ„пјҢеҸӘжҳҜзӣёеҜ№Javaд»Јз ҒжқҘиҜҙиҰҒйҡҫд»ҘзҗҶи§ЈдёҖдәӣиҖҢе·ІгҖӮ
JavaдёҺPythonдёҚеҗҢпјҢPythonдёҚйңҖиҰҒзј–иҜ‘еӯ—иҠӮз Ғж–Ү件(еҪ“然пјҢPythonд№ҹжҸҗдҫӣдәҶиҝҷз§Қж“ҚдҪң)пјҢзј–иҜ‘жҳҜдёҖдёӘиҮӘеҠЁзҡ„иҝҮзЁӢпјҢдёҖиҲ¬дёҚдјҡеңЁж„Ҹе®ғзҡ„еӯҳеңЁгҖӮиҖҢJavaдјҡе…Ҳзј–иҜ‘еҘҪеӯ—иҠӮз Ғж–Ү件пјҢиҝҷж ·JVMзӣҙжҺҘиҜ»еӯ—иҠӮз Ғж–Ү件пјҢеҸҜд»ҘиҠӮзңҒеҠ иҪҪжЁЎеқ—зҡ„ж—¶й—ҙпјҢжҸҗй«ҳж•ҲзҺҮгҖӮеҗҢж—¶еӯ—иҠӮз Ғзҡ„еҪўејҸд№ҹеўһеҠ дәҶеҸҚеҗ‘е·ҘзЁӢзҡ„йҡҫеәҰпјҢеҸҜд»ҘдҝқжҠӨжәҗд»Јз Ғ(еҪ“然пјҢд№ҹеҸҜд»Ҙиў«еҸҚзј–иҜ‘)гҖӮ
зҶҹжӮүJVMзҡ„е°ҸдјҷдјҙйғҪзҹҘйҒ“пјҢе®ғжңүдёҖдёӘвҖңзұ»еҠ иҪҪиҝҮзЁӢвҖқпјҢеҸҜд»ҘиҜҙжҳҜиҖҒе…«иӮЎж–ҮдәҶпјҢз»Ҹеёёдјҡиў«йқўиҜ•е®ҳй—®еҲ°гҖӮзұ»еҠ иҪҪиҝҮзЁӢе…¶е®һе°ұжҳҜжҢҮзҡ„JVMд»ҺиҜ»еҸ–дёҖдёӘclassж–Ү件еҲ°еҮҶеӨҮеҘҪиҝҷдёӘзұ»пјҢд»ҘеҸҠжңҖеҗҺй”ҖжҜҒзҡ„ж•ҙдёӘиҝҮзЁӢгҖӮ
жүҖд»ҘгҖҢclassж–Ү件其е®һжҳҜд»ҘвҖңзұ»вҖқдёәеҚ•дҪҚзҡ„пјҢиҝҷи·ҹjavaж–Ү件жңүдёҖдәӣдёҚеҗҢгҖҚгҖӮеҰӮжһңжҲ‘们еңЁдёҖдёӘJavaж–Ү件йҮҢйқўеЈ°жҳҺеӨҡдёӘзұ»пјҢз”ЁJavacзј–иҜ‘еҮәжқҘдјҡеҸ‘зҺ°жңүеӨҡдёӘclassж–Ү件гҖӮжҜ”еҰӮжҲ‘们声жҳҺдёҖдёӘOne.javaж–Ү件пјҡ
public class One { public class OneInner {} private class OnePrivateInner {} public static class OneStaticInner {} private static class OneprivateStaticInner {} } class Two{}з”ЁJavacзј–иҜ‘еҗҺпјҢдјҡеҮәзҺ°6дёӘclassж–Ү件
вһң $ ls 'One$OneInner.class' 'One$OneStaticInner.class' One.class Two.class 'One$OnePrivateInner.class' 'One$OneprivateStaticInner.class' One.java
еӯ—иҠӮз ҒеҲ°жңәеҷЁз Ғ
еҠ иҪҪе’ҢдҪҝз”Ёеӯ—иҠӮз Ғ
еүҚйқўжҸҗеҲ°пјҢJVMдјҡеҠ иҪҪclassж–Ү件пјҢ然еҗҺеҠ иҪҪеҗҺзҡ„Javaзұ»дјҡиў«еӯҳж”ҫдәҺж–№жі•еҢә(Method Area)дёӯгҖӮд»ҺжҢҮе®ҡзҡ„зұ»зҡ„mainж–№жі•дҪңдёәе…ҘеҸЈејҖе§ӢиҝҗиЎҢгҖӮе®һйҷ…иҝҗиЎҢж—¶пјҢиҷҡжӢҹжңәдјҡжү§иЎҢж–№жі•еҢәеҶ…зҡ„д»Јз ҒпјҢJVMдјҡдҪҝз”Ёе Ҷе’Ңж ҲжқҘеӯҳеӮЁиҝҗиЎҢж—¶ж•°жҚ®гҖӮ
жҜҸеҪ“иҝӣе…ҘдёҖдёӘж–№жі•пјҢJavaиҷҡжӢҹжңәдјҡеңЁеҪ“еүҚзәҝзЁӢзҡ„ж Ҳдёӯз”ҹжҲҗдёҖдёӘж Ҳеё§пјҢеӯҳж”ҫеұҖйғЁеҸҳйҮҸд»ҘеҸҠеӯ—иҠӮз Ғзҡ„ж“ҚдҪңж•°пјҢиҝҷдёӘж Ҳеё§зҡ„еӨ§е°ҸжҳҜжҸҗеүҚи®Ўз®—еҘҪзҡ„гҖӮ

йҖҖеҮәж–№жі•ж—¶пјҢдёҚз®ЎжҳҜжӯЈеёёиҝ”еӣһиҝҳжҳҜејӮеёёиҝ”еӣһпјҢJavaиҷҡжӢҹжңәеқҮдјҡгҖҢеј№еҮәеҪ“еүҚзәҝзЁӢзҡ„еҪ“еүҚж Ҳеё§гҖҚпјҢ并е°Ҷд№ӢиҲҚејғгҖӮ
JavaиҷҡжӢҹжңәйңҖиҰҒе°Ҷеӯ—иҠӮз Ғзҝ»иҜ‘жҲҗжңәеҷЁз ҒпјҢжүҚиғҪи®©жңәеҷЁжү§иЎҢгҖӮиҝҷдёӘиҝҮзЁӢжңүдёӨз§ҚеҪўејҸпјҢдёҖз§ҚжҳҜи§ЈйҮҠжү§иЎҢпјҢеҚійҖҗжқЎе°Ҷеӯ—иҠӮз Ғзҝ»иҜ‘жҲҗжңәеҷЁз Ғ并жү§иЎҢ;еҸҰдёҖз§ҚжҳҜеҚіж—¶зј–иҜ‘(Just-In-Time compilationпјҢJIT)пјҢеҚіе°ҶгҖҢдёҖдёӘж–№жі•дёӯгҖҚеҢ…еҗ«зҡ„жүҖжңүеӯ—иҠӮз Ғзј–иҜ‘жҲҗжңәеҷЁз ҒеҗҺеҶҚжү§иЎҢгҖӮ
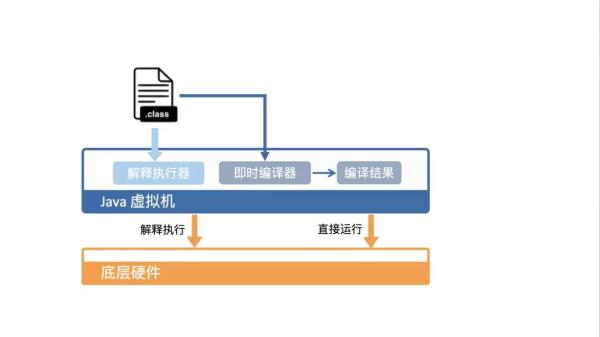
еҲҶеұӮзј–иҜ‘
иҝҷдёӨз§Қзј–иҜ‘ж–№ејҸжҳҜжҖҺд№ҲеҚҸдҪңзҡ„е‘ў?
HotSpotиҷҡжӢҹжңәеҢ…еҗ«еӨҡдёӘеҚіж—¶зј–иҜ‘еҷЁC1гҖҒC2е’ҢGraalгҖӮе…¶дёӯпјҢGraalжҳҜдёҖдёӘе®һйӘҢжҖ§иҙЁзҡ„еҚіж—¶зј–иҜ‘еҷЁпјҢеҸҜд»ҘйҖҡиҝҮеҸӮж•° -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompilerеҗҜз”ЁпјҢ并且жӣҝжҚўC2гҖӮ
C1е’ҢC2еҗ„жңүдјҳеҠЈпјҢйҖӮз”ЁдәҺдёҚеҗҢзҡ„еңәжҷҜгҖӮеңЁJava 7д»ҘеүҚпјҢеҸӘиғҪйҖүжӢ©дёҖз§Қзј–иҜ‘еҷЁгҖӮC1зј–иҜ‘еҝ«пјҢдҪҶз”ҹжҲҗзҡ„д»Јз Ғжү§иЎҢж•ҲзҺҮдёҖиҲ¬пјҢеёёз”ЁдәҺеҜ№дәҺжү§иЎҢж—¶й—ҙиҫғзҹӯзҡ„пјҢжҲ–иҖ…еҜ№еҗҜеҠЁжҖ§иғҪжңүиҰҒжұӮзҡ„зЁӢеәҸпјҢеёёз”ЁдәҺе®ўжҲ·з«Ҝ;C2зј–иҜ‘ж…ўпјҢдҪҶз”ҹжҲҗзҡ„д»Јз Ғжү§иЎҢж•ҲзҺҮеҝ«пјҢйҖӮз”ЁдәҺеҜ№дәҺжү§иЎҢж—¶й—ҙиҫғй•ҝзҡ„пјҢжҲ–иҖ…еҜ№еі°еҖјжҖ§иғҪжңүиҰҒжұӮзҡ„зЁӢеәҸпјҢеёёз”ЁдәҺжңҚеҠЎз«ҜгҖӮе®һйҷ…дёҠпјҢC1еҜ№еә”зҡ„еҸӮж•°жҳҜclientпјҢC2еҜ№еә”зҡ„еҸӮж•°жҳҜserverпјҢд№ҹи·ҹе®ғ们зҡ„еә”з”ЁеңәжҷҜжҜ”иҫғеҢ№й…ҚгҖӮ
Java7еј•е…ҘдәҶеҲҶеұӮзј–иҜ‘зҡ„жҰӮеҝөпјҢз»јеҗҲдәҶC1зҡ„еҗҜеҠЁжҖ§иғҪдјҳеҠҝе’ҢC2зҡ„еі°еҖјжҖ§иғҪдјҳеҠҝгҖӮC1е’ҢC2зј–иҜ‘еҮәзҡ„жңәеҷЁз ҒжҳҜдёҚеҗҢзҡ„гҖӮC2д»Јз Ғзҡ„жү§иЎҢж•ҲзҺҮиҰҒжҜ”C1д»Јз Ғй«ҳеҮә30%д»ҘдёҠгҖӮжңәеҷЁз Ғи¶Ҡеҝ«пјҢйңҖиҰҒзҡ„зј–иҜ‘ж—¶й—ҙе°ұи¶Ҡй•ҝгҖӮеҲҶеұӮзј–иҜ‘жҳҜдёҖз§ҚжҠҳиЎ·зҡ„ж–№ејҸпјҢж—ўиғҪеӨҹж»Ўи¶ійғЁеҲҶдёҚйӮЈд№Ҳзғӯзҡ„д»Јз ҒиғҪеӨҹеңЁзҹӯж—¶й—ҙеҶ…зј–иҜ‘е®ҢжҲҗпјҢд№ҹиғҪж»Ўи¶іеҫҲзғӯзҡ„д»Јз ҒиғҪеӨҹжӢҘжңүжңҖеҘҪзҡ„дјҳеҢ–гҖӮ
зғӯзӮ№д»Јз Ғ
йӮЈжҖҺд№ҲеҲӨе®ҡзғӯзӮ№д»Јз Ғе‘ў?
JVMдјҡ收йӣҶж–№жі•зҡ„иҝҗиЎҢж—¶дҝЎжҒҜпјҢдё»иҰҒеҢ…жӢ¬и°ғз”Ёж¬Ўж•°е’ҢеҫӘзҺҜеӣһиҫ№зҡ„ж¬Ўж•°гҖӮеҪ“гҖҢж–№жі•зҡ„и°ғз”Ёж¬Ўж•°е’ҢеҫӘзҺҜеӣһиҫ№зҡ„ж¬Ўж•°зҡ„е’ҢпјҢи¶…иҝҮжҢҮе®ҡйҳҲеҖјж—¶гҖҚпјҢдҫҝдјҡи§ҰеҸ‘еҚіж—¶зј–иҜ‘гҖӮ
->
еҫӘзҺҜеӣһиҫ№ж¬Ўж•°еҸҜд»Ҙз®ҖеҚ•зҗҶи§Јдёәж–№жі•еҶ…йғЁд»Јз Ғзҡ„еҫӘзҺҜж¬Ўж•°пјҢжҜ”еҰӮж–№жі•еҶ…йғЁжңүforеҫӘзҺҜжҲ–whileеҫӘзҺҜгҖӮ
<-
еңЁеҲҶеұӮзј–иҜ‘еҮәзҺ°еүҚпјҢиҝҷдёӘйҳҲеҖјжҳҜз”ұеҸӮж•°-XX:CompileThresholdжҢҮе®ҡзҡ„пјҢдҪҝз”ЁC1ж—¶пјҢиҜҘеҖјдёә1500;дҪҝз”ЁC2ж—¶пјҢиҜҘеҖјдёә10000гҖӮ
еҪ“еҗҜз”ЁеҲҶеұӮзј–иҜ‘ж—¶пјҢJVMдҪҝз”ЁеҸҰдёҖеҘ—йҳҲеҖјзі»з»ҹгҖӮеңЁиҝҷеҘ—зі»з»ҹдёӯпјҢйҳҲеҖјзҡ„еӨ§е°ҸжҳҜеҠЁжҖҒи°ғж•ҙзҡ„гҖӮJVMе°ҶйҳҲеҖјдёҺжҹҗдёӘзі»ж•° s зӣёд№ҳгҖӮиҜҘзі»ж•°дёҺеҪ“еүҚеҫ…зј–иҜ‘зҡ„ж–№жі•ж•°зӣ®жҲҗжӯЈзӣёе…іпјҢдёҺзј–иҜ‘зәҝзЁӢзҡ„ж•°зӣ®жҲҗиҙҹзӣёе…ігҖӮ
зј–иҜ‘зәҝзЁӢ
й»ҳи®Өжғ…еҶөдёӢзј–иҜ‘зәҝзЁӢзҡ„жҖ»ж•°зӣ®жҳҜж №жҚ®еӨ„зҗҶеҷЁж•°йҮҸжқҘи°ғж•ҙзҡ„гҖӮJava иҷҡжӢҹжңәдјҡе°Ҷиҝҷдәӣзј–иҜ‘зәҝзЁӢжҢүз…§1:2зҡ„жҜ”дҫӢеҲҶй…Қз»ҷ C1е’ҢC2(иҮіе°‘еҗ„дёә1дёӘ)гҖӮдёҫдёӘдҫӢеӯҗпјҢеҜ№дәҺдёҖдёӘеӣӣж ёжңәеҷЁжқҘиҜҙпјҢжҖ»зҡ„зј–иҜ‘зәҝзЁӢж•°зӣ®дёә3пјҢе…¶дёӯеҢ…еҗ«дёҖдёӘC1зј–иҜ‘зәҝзЁӢе’ҢдёӨдёӘC2зј–иҜ‘зәҝзЁӢгҖӮ
->
жңәеҷЁиө„жәҗеӨӘе°‘зҡ„ж—¶еҖҷпјҢд№ҹеҸҜиғҪеҗ„1дёӘзәҝзЁӢгҖӮ
<-
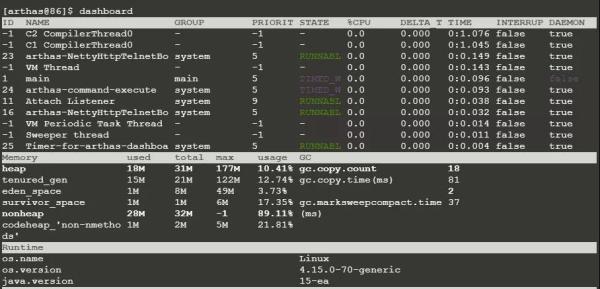
з”ЁarthasеҸҜд»ҘзңӢеҲ°зј–иҜ‘зәҝзЁӢпјҡ
^arthas^
еҸҜд»ҘзңӢеҲ°пјҢе®ғ们зҡ„IDжҳҜ-1пјҢдјҳе…Ҳзә§д№ҹжҳҜ-1гҖӮжҲ‘们иҮӘе·ұеҲӣе»әзҡ„зәҝзЁӢдјҳе…Ҳзә§жҳҜ0~10пјҢжүҖд»Ҙзј–иҜ‘зәҝзЁӢзҡ„дјҳе…Ҳзә§дјҡжӣҙй«ҳдёҖдәӣгҖӮ
жҖ»з»“
дёҖеҸҘиҜқжқҘжҖ»з»“JavaзЁӢеәҸжҳҜжҖҺд№ҲеңЁжңәеҷЁдёҠиҝҗиЎҢзҡ„е‘ў?йҰ–е…ҲJavaзЁӢеәҸе‘ҳзј–еҶҷJavaд»Јз ҒпјҢ然еҗҺJavaд»Јз Ғдјҡиў«зј–иҜ‘жҲҗclassж–Ү件пјҢеӨҡдёӘclassж–Ү件дјҡиў«жү“еҢ…жҲҗjarеҢ…жҲ–иҖ…warеҢ…гҖӮ然еҗҺJVMеҠ иҪҪclassж–Ү件пјҢ然еҗҺе…Ҳи§ЈйҮҠжү§иЎҢдёәеӯ—иҠӮз ҒгҖӮзЁӢеәҸиҝҗиЎҢдёҖж®өж—¶й—ҙеҗҺпјҢJVMдјҡйҖҡиҝҮж–№жі•и°ғз”Ёж¬Ўж•°е’ҢеҫӘзҺҜжҢҒз»ӯеҲӨж–ӯдёҖдёӘж–№жі•жҳҜеҗҰдёәзғӯзӮ№д»Јз ҒпјҢеҰӮжһңжҳҜпјҢдјҡдҪҝз”ЁеҲҶеұӮзј–иҜ‘пјҢйҖҡиҝҮзј–иҜ‘зәҝзЁӢзј–иҜ‘жҲҗеӯ—иҠӮз ҒпјҢеңЁжңәеҷЁдёҠиҝҗиЎҢгҖӮ
вҖңJavaд»Јз ҒжҳҜеҰӮдҪ•еңЁжңәеҷЁдёҠиҝҗиЎҢзҡ„вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





