C++д»Јз Ғж“ҚдҪңзҡ„ж•ҲзҺҮжңүе“Әдәӣ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңC++д»Јз Ғж“ҚдҪңзҡ„ж•ҲзҺҮжңүе“ӘдәӣвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңC++д»Јз Ғж“ҚдҪңзҡ„ж•ҲзҺҮжңүе“ӘдәӣвҖқеҗ§пјҒ
жң¬дё“йўҳе°ҶеҲҶжһҗC++еҗ„з§Қд»Јз Ғж“ҚдҪңзҡ„ж•ҲзҺҮпјҢеҢ…жӢ¬дёҚеҗҢзұ»еһӢеҸҳйҮҸзҡ„еӯҳеӮЁж•ҲзҺҮпјҢдҪҝз”ЁжҷәиғҪжҢҮй’ҲгҖҒеҫӘзҺҜгҖҒеҮҪж•°еҸӮж•°гҖҒиҷҡеҮҪж•°гҖҒж•°з»„зӯүзҡ„ж•ҲзҺҮпјҢд»ҘеҸҠеҰӮдҪ•еҒҡй’ҲеҜ№жҖ§дјҳеҢ–пјҢжҲ–йҖүжӢ©жӣҙжңүж•Ҳзҡ„жӣҝд»Јж–№жЎҲгҖӮ
иҜҰз»Ҷзӣ®еҪ•зңӢдёӢеӣҫпјҡ
еҸҳйҮҸеӯҳеӮЁеҢәеҹҹпјҡ
еңЁC++дёӯпјҢеҸҳйҮҸеӯҳеӮЁеңЁе“Әзұ»еҶ…еӯҳпјҢеҸ–еҶідәҺејҖеҸ‘иҖ…еЈ°жҳҺе®ғ们зҡ„ж–№ејҸгҖӮеҰӮжһңж•°жҚ®дёҚиҝһз»ӯпјҢеҲҶжҲҗж— ж•°ж®өеҲҶж•ЈеңЁеҶ…еӯҳдёӯпјҢдјҡйҷҚдҪҺж•°жҚ®зҡ„Cacheе‘ҪдёӯзҺҮгҖӮеӣ жӯӨпјҢзҗҶи§ЈеҸҳйҮҸеҰӮдҪ•еӯҳеӮЁйқһеёёйҮҚиҰҒгҖӮ
ж Ҳз©әй—ҙ
ж Ҳз©әй—ҙпјҢйҖҡеёёз”ЁдәҺеӯҳеӮЁеұҖйғЁеҸҳйҮҸгҖҒеҮҪж•°еҸӮж•°гҖҒеҮҪж•°иҝ”еӣһең°еқҖгҖҒеҮҪж•°иҝ”еӣһеүҚйңҖиҰҒжҒўеӨҚзҡ„еҜ„еӯҳеҷЁзӯүгҖӮжҜҸж¬Ўи°ғз”ЁеҮҪж•°ж—¶пјҢзі»з»ҹйғҪдјҡеҲҶй…ҚдёҖж®өж Ҳз©әй—ҙпјҢз”ЁдәҺеӯҳеӮЁиҝҷдәӣдёңиҘҝпјҢеҮҪж•°иҝ”еӣһж—¶пјҢиҝҷж®өж Ҳз©әй—ҙдјҡиў«еӣһ收пјҢдёӢж¬Ўи°ғз”ЁеҮҪж•°ж—¶пјҢзЁӢеәҸиҝҳеҸҜд»ҘйҮҚз”Ёиҝҷж®өж Ҳз©әй—ҙгҖӮ
дёҖиҲ¬жқҘиҜҙпјҢзЁӢеәҸжҜҸдёӘзәҝзЁӢжңүеӣәе®ҡеӨ§е°Ҹзҡ„ж Ҳз©әй—ҙпјҢдҪҝз”ЁеӨҡе°‘пјҢеӣһ收еӨҡе°‘пјҢеҸӘжҳҜеҒҸ移йҮҸеҒҸ移еӨҡе°‘зҡ„й—®йўҳгҖӮж Ҳз©әй—ҙзү№еҲ«й«ҳж•ҲжҳҜеӣ дёәеҗҢдёҖж®өеҶ…еӯҳз©әй—ҙеҸҜд»Ҙиў«еҸҚеӨҚдҪҝз”ЁпјҢеҶ…еӯҳеҫҲе®№жҳ“е°ұеҠ иҪҪеҲ°CacheдёӯпјҢCacheе‘ҪдёӯзҺҮжӣҙй«ҳгҖӮ
жҲ‘们еҸҜд»ҘеӨҡеҲ©з”Ёж Ҳз©әй—ҙгҖӮжүҖжңүзҡ„еҸҳйҮҸпјҢжңҖеҘҪйғҪеңЁдҪҝз”Ёе®ғ们зҡ„еҮҪж•°дёӯеЈ°жҳҺгҖӮжңүдәӣжғ…еҶөдёӢеҸҜд»ҘеңЁеӨ§жӢ¬еҸ·{ }еҶ…еЈ°жҳҺеҸҳйҮҸпјҢе°ҪеҸҜиғҪзј©е°ҸеҸҳйҮҸзҡ„дҪңз”ЁеҹҹгҖӮ
е…ЁеұҖжҲ–йқҷжҖҒз©әй—ҙ
е…ЁеұҖеҸҳйҮҸпјҢд»»дҪ•еҮҪж•°йғҪеҸҜд»Ҙи®ҝй—®пјҢеӯҳеӮЁеңЁеҶ…еӯҳзҡ„йқҷжҖҒз©әй—ҙдёӯгҖӮstaticе…ій”®еӯ—еЈ°жҳҺзҡ„еҸҳйҮҸгҖҒжө®зӮ№еёёйҮҸгҖҒеӯ—з¬ҰдёІеёёйҮҸгҖҒиҷҡеҮҪж•°иЎЁзӯүпјҢйғҪеӯҳеӮЁеңЁйқҷжҖҒз©әй—ҙдёӯгҖӮ
йқҷжҖҒз©әй—ҙзҡ„дјҳзӮ№жҳҜпјҢеҸҜд»ҘеңЁзЁӢеәҸеҗҜеҠЁеүҚе°ұе°Ҷе…¶еҲқе§ӢеҢ–дёәжүҖйңҖзҡ„еҖјгҖӮзјәзӮ№жҳҜпјҢеҚідҪҝеҸҳйҮҸеҸӘдҪҝз”ЁдёҖж¬ЎпјҢжҲ–иҖ…еҸӘеңЁзЁӢеәҸзҡ„дёҖе°ҸйғЁеҲҶдёӯдҪҝз”ЁпјҢе®ғзҡ„еҶ…еӯҳпјҢд№ҹдјҡеңЁзЁӢеәҸж•ҙдёӘиҝҗиЎҢиҝҮзЁӢдёӯиў«еҚ з”ЁпјҢдјҡйҷҚдҪҺCacheзҡ„ж•ҲзҺҮгҖӮ
е°ҪйҮҸдёҚиҰҒе°ҶеҸҳйҮҸеЈ°жҳҺдёәе…ЁеұҖеҸҳйҮҸпјҢдёҖдёӘеҸҳйҮҸеҰӮжһңиў«еӨҡдёӘеҮҪж•°дҪҝз”ЁпјҢеҸҜд»ҘиҖғиҷ‘е°Ҷе…¶дҪңдёәеҸӮж•°пјҢдҪҶжҳҜеҸӮж•°дј йҖ’жҳҜжңүејҖй”Җзҡ„пјҢеҰӮжһңжҲ‘们жғійҒҝе…Қиҝҷзұ»ејҖй”ҖпјҢйҡҫйҒ“е°ұиҰҒеЈ°жҳҺдёәе…ЁеұҖеҸҳйҮҸдәҶеҗ—?е…¶е®һжҲ‘们д№ҹеҸҜе°ҶеҸҳйҮҸеӯҳеӮЁеңЁзұ»еҜ№иұЎдёӯпјҢеӨҡдёӘеҮҪж•°йғҪи®ҝй—®зұ»еҜ№иұЎдёӯзҡ„еҸҳйҮҸжҲҗе‘ҳгҖӮ
жҹҗдәӣжғ…еҶөдёӢпјҢеҸҜд»ҘиҖғиҷ‘staticе’Ңconstе…ұз”ЁпјҢдҫӢеҰӮеЈ°жҳҺдёҖдёӘйқҷжҖҒеёёйҮҸжҹҘиҜўиЎЁпјҡ
float SomeFunction(int x) { static const float list[] = {1.1, 2.2, 3.4, 4.4, 5.5}; return list[x]; }иҝҷз§Қж–№ејҸзҡ„еҘҪеӨ„жҳҜпјҢдёҚйңҖиҰҒеңЁжҜҸж¬Ўи°ғз”ЁеҮҪж•°ж—¶еҜ№еҲ—иЎЁиҝӣиЎҢеҲқе§ӢеҢ–гҖӮstaticеЈ°жҳҺж„Ҹе‘ізқҖеңЁз¬¬дёҖж¬Ўи°ғз”ЁеҲқе§ӢеҢ–еҗҺпјҢеҗҺз»ӯе°ұдёҚеҶҚйңҖиҰҒеҲқе§ӢеҢ–пјҢдҪҶиҝҷж ·ж•ҲзҺҮиҫғдҪҺпјҢеӣ дёәйңҖиҰҒйўқеӨ–жЈҖжҹҘе®ғжҳҜ第дёҖж¬Ўи°ғз”ЁпјҢиҝҳжҳҜе·Із»Ҹиў«и°ғз”ЁиҝҮгҖӮеҠ е…ҘconstеЈ°жҳҺпјҢеҸҜд»Ҙе‘ҠиҜүзј–иҜ‘еҷЁпјҢдёҚйңҖиҰҒеҜ№жҳҜеҗҰжҳҜ第дёҖж¬Ўи°ғз”ЁжқҘиҝӣиЎҢжЈҖжҹҘгҖӮжүҖд»ҘжңҖеҘҪеҠ дёҠstaticе’ҢconstеЈ°жҳҺпјҢд»Ҙдҫҝи®©зј–иҜ‘еҷЁжӣҙеҘҪзҡ„дјҳеҢ–гҖӮ
еӯ—з¬ҰдёІеёёйҮҸе’Ңжө®зӮ№ж•°еёёйҮҸпјҢд№ҹз»ҸеёёдҝқеӯҳеңЁйқҷжҖҒз©әй—ҙдёӯпјҢдҫӢеҰӮпјҡ
a = b * 3.5; c = d + 3.5;
иҝҷйҮҢпјҢеёёж•°3.5е°ҶеӯҳеӮЁеңЁйқҷжҖҒз©әй—ҙдёӯпјҢеӨ§еӨҡж•°зј–иҜ‘еҷЁдјҡиҜҶеҲ«еҮәиҝҷдёӨдёӘеёёйҮҸжҳҜзӣёеҗҢзҡ„пјҢеӣ жӯӨеҸӘйңҖиҰҒеӯҳеӮЁдёҖд»ҪеёёйҮҸгҖӮж•ҙдёӘзЁӢеәҸдёӯжүҖжңүзӣёеҗҢзҡ„еёёйҮҸе°Ҷиў«иҝһжҺҘеңЁдёҖиө·пјҢдјҳеҢ–зЁӢеәҸдёӯеёёйҮҸзҡ„еҚ з”Ёз©әй—ҙгҖӮ
еҜ„еӯҳеҷЁеӯҳеӮЁ
еҜ„еӯҳеҷЁжҳҜCPUдёӯзҡ„дёҖе°Ҹеқ—еҶ…еӯҳпјҢз”ЁдҪңдёҙж—¶еӯҳеӮЁгҖӮи®ҝй—®еҜ„еӯҳеҷЁдёӯзҡ„еҸҳйҮҸйҖҹеәҰйқһеёёеҝ«пјҢдҪҶжҳҜеҜ„еӯҳеҷЁж•°йҮҸжңүйҷҗпјҢеӯҳеӮЁзҡ„еҸҳйҮҸд№ҹжңүйҷҗгҖӮзј–иҜ‘еҷЁдјҳеҢ–ж—¶пјҢдјҡиҮӘеҠЁйҖүжӢ©еҮҪж•°дёӯзҡ„жңҖеёёз”ЁеҸҳйҮҸпјҢеӯҳеҲ°еҜ„еӯҳеҷЁдёӯгҖӮзЁӢеәҸдёӯзҡ„еұҖйғЁеҸҳйҮҸе°ұеҫҲйҖӮеҗҲдәҺеӯҳеӮЁеңЁеҜ„еӯҳеҷЁдёӯгҖӮ
еҜ„еӯҳеҷЁж•°йҮҸжңүйҷҗпјҢ32дҪҚX86зі»з»ҹдёӯпјҢеӨ§зәҰжңү6дёӘж•ҙж•°еҜ„еӯҳеҷЁз”ЁдәҺйҖҡз”Ёзӣ®зҡ„пјҢ64дҪҚзі»з»ҹдёӯжңү14дёӘгҖӮиҖҢжө®зӮ№еҸҳйҮҸдҪҝз”ЁдёҚеҗҢзҡ„еҜ„еӯҳеҷЁпјҢ32дҪҚзі»з»ҹдёӯеӨ§зәҰжңү8дёӘеҸҜз”Ёзҡ„жө®зӮ№еҜ„еӯҳеҷЁпјҢ64дҪҚзі»з»ҹдёӯжңү16дёӘпјҢеҪ“еңЁ64дҪҚзі»з»ҹдёӯеҗҜз”Ёжӣҙй«ҳзә§зҡ„жҢҮд»ӨйӣҶж—¶пјҢеҸҜиғҪдјҡжңүжӣҙеӨҡеҸҜз”Ёзҡ„жө®зӮ№еҜ„еӯҳеҷЁгҖӮ
volatile
иҝҷйҮҢйңҖиҰҒзү№еҲ«е…іжіЁдёӢvolatileе…ій”®еӯ—пјҢиҜҘе…ій”®еӯ—иЎЁзӨәе…¶дҝ®йҘ°зҡ„еҸҳйҮҸеҸҜд»Ҙиў«еҸҰдёҖдёӘзәҝзЁӢжӣҙж”№пјҢйҳІжӯўзј–иҜ‘еҷЁеҒҡдёҖдәӣиҝҮеәҰдјҳеҢ–гҖӮдҫӢеҰӮпјҡ
volatile int seconds; void DelayFiveSeconds() { seconds = 0; while (seconds < 5) { // do nothing while seconds count to 5 } }еңЁжң¬дҫӢдёӯпјҢDelayFiveSeconds()е°ҶдёҖзӣҙзӯүеҫ…пјҢзӣҙеҲ°еҸҰдёҖдёӘзәҝзЁӢе°ҶsecondsеўһеҠ еҲ°5гҖӮ
еҰӮжһңsecondsжІЎиў«еЈ°жҳҺдёәvolatileпјҢйӮЈд№Ҳзј–иҜ‘еҷЁеҸҜиғҪдјҡиҝӣиЎҢиҝҮеәҰдјҳеҢ–пјҢе°ҶеҒҮе®ҡеңЁwhileеҫӘзҺҜдёӯsecondsдҝқжҢҒдёә0пјҢеҫӘзҺҜеҶ…зҡ„д»»дҪ•еҶ…е®№йғҪдёҚиғҪжӣҙж”№иҜҘеҖјгҖӮеҫӘзҺҜе°ҶжҳҜwhile(0 < 5){}пјҢиҝҷе°ҶжҳҜдёӘжӯ»еҫӘзҺҜгҖӮ
е…ій”®еӯ—volatileзҡ„дҪңз”ЁжҳҜпјҢзЎ®дҝқеҸҳйҮҸж°ёиҝңеӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢиҖҢдёҚжҳҜеңЁеҜ„еӯҳеҷЁдёӯпјҢ并йҳ»жӯўеҜ№еҸҳйҮҸзҡ„жүҖжңүдјҳеҢ–гҖӮ
жіЁж„ҸvolatileдёҚдҝқиҜҒеҺҹеӯҗжҖ§пјҢе®ғдёҚдјҡйҳ»жӯўдёӨдёӘзәҝзЁӢеҗҢж—¶е°қиҜ•еҶҷж“ҚдҪңгҖӮе…¶д»–зәҝзЁӢеўһеҠ secondsзҡ„еҗҢж—¶пјҢиҜ•еӣҫе°Ҷsecondsи®ҫзҪ®дёә0пјҢиҝҷж ·еҸҜиғҪдјҡеӨұиҙҘгҖӮжӣҙе®үе…Ёзҡ„еҒҡжі•жҳҜпјҢдёҖдёӘзәҝзЁӢеҸӘиҜ»еҸ–secondsпјҢ并зӯүеҫ…иҜҘеҖјжӣҙж”№гҖӮ
thread-localеӯҳеӮЁ
C++11дёӯеҸҜд»ҘдҪҝз”Ёthread_localе…ій”®еӯ—жқҘеЈ°жҳҺзәҝзЁӢжң¬ең°еҸҳйҮҸпјҢC++11еүҚд№ҹжңүеҲ«зҡ„ж–№ејҸеЈ°жҳҺпјҢиў«дҝ®йҘ°зҡ„еҸҳйҮҸеҜ№дәҺжҜҸдёӘзәҝзЁӢйғҪжңүдёҖд»ҪжӢ·иҙқпјҢдҝқиҜҒдәҶзәҝзЁӢе®үе…ЁгҖӮthread-localеӯҳеӮЁж•ҲзҺҮиҫғдҪҺпјҢеӣ дёәе®ғжҳҜйҖҡиҝҮе…ЁеұҖжҢҮй’Ҳи®ҝй—®гҖӮжҲ‘们еә”иҜҘе°ҪйҮҸйҒҝе…ҚзәҝзЁӢжң¬ең°еӯҳеӮЁпјҢеҸҜд»ҘжӣҙеӨҡе°ҶеҸҳйҮҸеӯҳеӮЁеңЁзәҝзЁӢиҮӘе·ұзҡ„ж ҲдёӯпјҢеҚіеңЁзәҝзЁӢиҮӘе·ұзҡ„еҮҪж•°дёӯеЈ°жҳҺеҸҳйҮҸгҖӮ
е ҶеҶ…еӯҳ
е ҶеҶ…еӯҳдё»иҰҒйҖҡиҝҮж“ҚдҪңз¬Ұnewе’ҢdeleteеҠЁжҖҒеҲҶй…ҚпјҢжҲ–иҖ…дҪҝз”ЁеҮҪж•°mallocе’ҢfreeгҖӮеҰӮжһңд»ҘйҡҸжңәзҡ„йЎәеәҸеҲҶй…Қе’ҢйҮҠж”ҫдёҚеҗҢеӨ§е°Ҹзҡ„еҶ…еӯҳпјҢеҫҲе®№жҳ“дә§з”ҹеҶ…еӯҳзўҺзүҮпјҢеҲҶж•ЈеңЁе ҶеҶ…еӯҳзҡ„дёҚеҗҢең°ж–№пјҢиҖҢдё”йў‘з№ҒеҲҶй…ҚеҶ…еӯҳпјҢејҖй”Җд№ҹиҫғеӨ§гҖӮе°ҪйҮҸйҒҝе…ҚеҠЁжҖҒеҲҶй…ҚеҶ…еӯҳеҗ§пјҢжҲ–иҖ…з”ЁJeMallocжӣҝжҚўдёҖжіў?жҲ–еҶ…еӯҳжұ ?
ж•ҙж•°еҸҳйҮҸе’Ңиҝҗз®—
ж•ҙеһӢеӨ§е°Ҹ
ж•ҙж•°дёӯпјҢдёҚеҗҢзұ»еһӢеҸҜиғҪдјҡжңүдёҚеҗҢзҡ„еӨ§е°ҸпјҢдёӢеӣҫжҖ»з»“дәҶдёҚеҗҢж•ҙеһӢзҡ„еӨ§е°Ҹе’ҢжңҖеӨ§жңҖе°ҸеҖјпјҡ
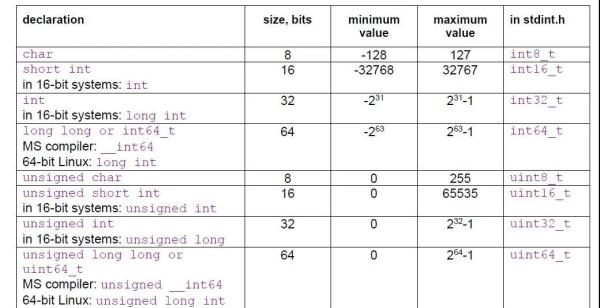
еңЁдёҚеҗҢзҡ„е№іеҸ°пјҢеЈ°жҳҺзү№е®ҡеӨ§е°Ҹж•ҙж•°зҡ„ж–№жі•дёҚеҗҢпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ёж ҮеҮҶеӨҙж–Ү件stdint.hпјҢеЈ°жҳҺзү№е®ҡеӨ§е°Ҹзҡ„ж•ҙеһӢпјҢиҜҘж–№жі•иҝҳеҸҜд»Ҙи·Ёе№іеҸ°пјҢеҸҜ移жӨҚгҖӮ
еӨ§еӨҡж•°жғ…еҶөдёӢпјҢж•ҙж•°иҝҗз®—йқһеёёеҝ«пјҢдҪҶжҳҜпјҢеҰӮжһңж•ҙж•°еӨ§дәҺеҸҜз”ЁеҜ„еӯҳеҷЁеӨ§е°ҸпјҢж•ҲзҺҮе°ұдјҡдҪҺдёҖдәӣгҖӮдҫӢеҰӮпјҢеңЁ32дҪҚзі»з»ҹдёӯпјҢдҪҝз”Ё64дҪҚж•ҙж•°ж•ҲзҺҮдҪҺдёҖдәӣпјҢзү№еҲ«жҳҜз”ЁдәҺд№ҳжі•жҲ–йҷӨжі•ж—¶гҖӮ
еҰӮжһңеЈ°жҳҺдәҶintзұ»еһӢпјҢдҪҶжҳҜжІЎжңүжҢҮе®ҡе…·дҪ“еӨ§е°ҸпјҢзј–иҜ‘еҷЁе°Ҷе§Ӣз»ҲйҖүжӢ©жңҖжңүж•Ҳзҡ„ж•ҙж•°еӨ§е°ҸгҖӮиҫғе°ҸеӨ§е°Ҹзҡ„ж•ҙж•°еҰӮcharгҖҒshort intзӯүпјҢж•ҲзҺҮеҸҜиғҪзЁҚеҫ®дҪҺдёҖдәӣпјҢеңЁеҫҲеӨҡжғ…еҶөдёӢпјҢзј–иҜ‘еҷЁеңЁиҝӣиЎҢи®Ўз®—ж—¶пјҢдјҡе°Ҷиҝҷдәӣзұ»еһӢиҪ¬жҚўдёәй»ҳи®ӨеӨ§е°Ҹзҡ„ж•ҙж•°пјҢ然еҗҺеҸӘдҪҝз”Ёз»“жһңдёӯзҡ„дҪҺ8дҪҚжҲ–иҖ…дҪҺ16дҪҚгҖӮеңЁ64дҪҚзі»з»ҹдёӯпјҢеҸӘиҰҒжҲ‘们дёҚеҒҡйҷӨжі•пјҢдҪҝз”Ё32дҪҚж•ҙж•°е’Ң64дҪҚж•ҙж•°зҡ„ж•ҲзҺҮе…¶е®һжІЎеӨҡеӨ§е·®еҲ«гҖӮ
ж•ҙж•°иҝҗз®—ж—¶пјҢжҲ‘们йңҖиҰҒиҖғиҷ‘дёӯй—ҙи®Ўз®—зҡ„з»“жһңпјҢзңӢжҳҜеҗҰдјҡеҜјиҮҙжәўеҮәгҖӮдҫӢеҰӮиЎЁиҫҫејҸa=b+c+dпјҢеҚідҪҝbгҖҒcгҖҒdйғҪдҪҺдәҺж•ҙж•°жңҖеӨ§еҖјпјҢдҪҶжҳҜеҸҜиғҪb+cе°ұдјҡеҜјиҮҙж•ҙж•°жәўеҮәпјҢжҲ‘们йңҖиҰҒж—¶еҲ»жіЁж„ҸгҖӮ
жңүз¬ҰеҸ·ж•ҙж•°е’Ңж— з¬ҰеҸ·ж•ҙж•°
еӨҡж•°жғ…еҶөдёӢпјҢдҪҝз”Ёжңүз¬ҰеҸ·ж•ҙж•°е’Ңж— з¬ҰеҸ·ж•ҙж•°пјҢеңЁйҖҹеәҰдёҠжІЎжңүеҢәеҲ«пјҢдҪҶжңүдёҖдәӣзү№ж®Ҡжғ…еҶөпјҡ
еёёйҮҸйҷӨжі•пјҢеҪ“йҷӨд»ҘеёёйҮҸж—¶пјҢж— з¬ҰеҸ·ж•ҙж•°жҜ”жңүз¬ҰеҸ·ж•ҙж•°ж•ҲзҺҮжӣҙй«ҳпјҢжЁЎиҝҗз®—зұ»дјјгҖӮ
еҜ№дәҺеӨ§еӨҡж•°жҢҮд»ӨйӣҶпјҢдҪҝз”Ёжңүз¬ҰеҸ·ж•ҙж•°еҲ°жө®зӮ№ж•°зҡ„иҪ¬жҚўпјҢиҰҒжҜ”дҪҝз”Ёж— з¬ҰеҸ·ж•ҙж•°иҪ¬жҚўжӣҙеҝ«гҖӮ
жңүз¬ҰеҸ·е’Ңж— з¬ҰеҸ·ж•ҙж•°зҡ„жәўеҮәиЎҢдёәдёҚеҗҢпјҡж— з¬ҰеҸ·ж•ҙж•°зҡ„жәўеҮәдә§з”ҹдёҖдёӘдҪҺжӯЈз»“жһңпјҢжңүз¬ҰеҸ·ж•ҙж•°зҡ„жәўеҮәжҳҜе®ҳж–№жңӘе®ҡд№үзҡ„гҖӮжңүз¬ҰеҸ·ж•ҙж•°пјҢжӯЈеёёзҡ„иЎҢдёәжҳҜе°ҶжӯЈжәўеҮәиҪ¬жҚўдёәиҙҹеҖјпјҢдҪҶжҳҜзј–иҜ‘еҷЁеҸҜиғҪеҒҡдёҖдәӣдјҳеҢ–пјҢе®ғдјҡеҒҮи®ҫдёҚдјҡеҸ‘з”ҹжәўеҮәгҖӮ
жңүз¬ҰеҸ·ж•ҙж•°е’Ңж— з¬ҰеҸ·ж•ҙж•°д№Ӣй—ҙзҡ„иҪ¬жҚўпјҢжІЎжңүд»»дҪ•ејҖй”ҖгҖӮиҝҷеҸӘдёҚиҝҮжҳҜеҜ№еҗҢдёҖз¬ҰеҸ·дҪҚзҡ„дёҚеҗҢи§ЈйҮҠиҖҢе·ІгҖӮиҙҹж•ҙж•°еңЁиҪ¬жҚўдёәж— з¬ҰеҸ·ж—¶пјҢе°Ҷиў«и§ЈйҮҠдёәдёҖдёӘйқһеёёеӨ§зҡ„жӯЈж•°гҖӮ
int a, b; double c; b = (unsigned int)a / 10; // иҪ¬жҚўжҲҗж— з¬ҰеҸ·ж•ҙж•°еҒҡйҷӨжі•жӣҙеҝ« c = a * 2.5; // жңүз¬ҰеҸ·ж•ҙж•°йҡҗејҸиҪ¬жҚўдёәdoubleеһӢ
еңЁдёҠдҫӢдёӯпјҢе°ҶaиҪ¬жҚўдёәunsignedпјҢеҸҜд»ҘдҪҝйҷӨжі•жӣҙеҝ«гҖӮеҪ“然пјҢеҸӘжңүеҪ“aз»қеҜ№дёҚдјҡжҳҜиҙҹж•°зҡ„ж—¶еҖҷпјҢжүҚеҸҜд»Ҙиҝҷд№ҲиҪ¬жҚўгҖӮжңҖеҗҺдёҖиЎҢпјҢеңЁдёҺеёёж•°2.5зӣёд№ҳд№ӢеүҚпјҢдјҡйҡҗејҸең°е°ҶaиҪ¬жҚўдёәdoubleпјҢеӣ дёәеҗҺиҖ…жҳҜdoubleпјҢиҝҷйҮҢaдҪңдёәжңүз¬ҰеҸ·ж•ҙж•°еҺ»иҪ¬жҚўпјҢж•ҲзҺҮжӣҙй«ҳгҖӮ
жіЁж„ҸпјҢеңЁиҝӣиЎҢжҜ”иҫғж“ҚдҪңж—¶пјҢдҫӢеҰӮ<ж“ҚдҪңпјҢдёҚиҰҒж··з”Ёжңүз¬ҰеҸ·ж•ҙж•°е’Ңж— з¬ҰеҸ·ж•ҙж•°гҖӮжңүз¬ҰеҸ·ж•ҙж•°е’Ңж— з¬ҰеҸ·ж•ҙж•°зҡ„жҜ”иҫғпјҢеҸҜиғҪдјҡдә§з”ҹж„ҸжғідёҚеҲ°зҡ„з»“жһңгҖӮ
ж•ҙж•°иҝҗз®—
ж•ҙж•°иҝҗз®—йҖҡеёёйқһеёёеҝ«гҖӮз®ҖеҚ•зҡ„ж•ҙж•°иҝҗз®—пјҢеҰӮеҠ жі•гҖҒеҮҸжі•гҖҒжҜ”иҫғгҖҒдҪҚиҝҗз®—зӯүпјҢеңЁеӨ§еӨҡж•°еҫ®еӨ„зҗҶеҷЁдёҠеҸӘйңҖиҰҒдёҖдёӘж—¶й’ҹе‘ЁжңҹгҖӮд№ҳжі•е’ҢйҷӨжі•йңҖиҰҒжӣҙй•ҝзҡ„ж—¶й—ҙгҖӮж•ҙж•°д№ҳжі•еңЁеҘ”и…ҫ4CPUдёҠйңҖиҰҒ11дёӘж—¶й’ҹе‘ЁжңҹпјҢеӨ§еӨҡж•°жғ…еҶөд№ҳжі•йғҪйңҖиҰҒ3 - 4дёӘж—¶й’ҹе‘ЁжңҹпјҢж•ҙж•°йҷӨжі•йңҖиҰҒ40 - 80дёӘж—¶й’ҹе‘ЁжңҹпјҢе…·дҪ“еҸ–еҶідәҺCPUгҖӮ
иҮӘеўһе’ҢиҮӘеҮҸиҝҗз®—
++iе’Ңi++йҖҹеәҰдёҖж ·еҝ«пјҢеҪ“д»…з”ЁдәҺйҖ’еўһеҸҳйҮҸж—¶пјҢдҪҝз”Ё++iе’Ңi++жІЎжңүд»»дҪ•еҢәеҲ«пјҢж•Ҳжһңе®Ңе…ЁзӣёеҗҢпјҢдҫӢеҰӮпјҡ
for(i=0;i
жө®зӮ№ж•°еҸҠе…¶иҝҗз®—
зҺ°д»Јx86家ж—Ҹзҡ„CPUпјҢжңүдёӨз§ҚдёҚеҗҢзұ»еһӢзҡ„жө®зӮ№еҜ„еӯҳеҷЁпјҢеҜ№еә”дёҚеҗҢзұ»еһӢзҡ„жө®зӮ№жҢҮд»ӨпјҢжҜҸз§Қзұ»еһӢйғҪжңүдјҳзјәзӮ№гҖӮ
x87еҜ„еӯҳеҷЁ
x87еҜ„еӯҳеҷЁжҳҜжө®зӮ№иҝҗз®—зҡ„дј з»ҹж–№жі•пјҢиҝҷдәӣеҜ„еӯҳеҷЁйғҪжңүй•ҝеҸҢзІҫеәҰпјҢеӨҡдёӘеҜ„еӯҳеҷЁз»„жҲҗдәҶдёҖз»„еҜ„еӯҳеҷЁж ҲпјҢдҪҝз”ЁеҜ„еӯҳеҷЁж Ҳзҡ„дјҳзӮ№жңүпјҡ
жүҖжңүзҡ„и®Ўз®—йғҪжҳҜз”ЁеҸҢзІҫеәҰе®ҢжҲҗзҡ„дёҚеҗҢзІҫеәҰд№Ӣй—ҙзҡ„иҪ¬жҚўдёҚйңҖиҰҒйўқеӨ–зҡ„ж—¶й—ҙгҖӮ
еҜ№дәҺж•°еӯҰеҮҪж•°пјҢеҰӮеҜ№ж•°еҮҪж•°е’Ңдёүи§’еҮҪж•°пјҢжңүдёҖдәӣеҶ…зҪ®зҡ„жҢҮд»ӨгҖӮ
д»Јз ҒеҫҲзҙ§еҮ‘пјҢеңЁд»Јз Ғзј“еӯҳдёӯеҚ з”Ёзҡ„з©әй—ҙеҫҲе°ҸгҖӮ
еҜ„еӯҳеҷЁж Ҳд№ҹжңүзјәзӮ№пјҡ
з”ұдәҺеҜ„еӯҳеҷЁж Ҳзҡ„з»„з»Үж–№ејҸпјҢзј–иҜ‘еҷЁеҫҲйҡҫеҲӣе»әеҜ„еӯҳеҷЁеҸҳйҮҸгҖӮ
жө®зӮ№ж•°жҜ”иҫғйҖҹеәҰеҫҲж…ўпјҢйҷӨйқһеҗҜз”Ёжӣҙй«ҳзҡ„жҢҮд»ӨйӣҶгҖӮ
еҪ“дҪҝз”ЁеҸҢзІҫеәҰж—¶пјҢйҷӨжі•гҖҒе№іж–№ж №е’Ңж•°еӯҰеҮҪж•°пјҢйңҖиҰҒжӣҙеӨҡзҡ„ж—¶й—ҙжқҘи®Ўз®—гҖӮ
еҗ‘йҮҸеҜ„еӯҳеҷЁ
д№ҹеҸ«зҹўйҮҸеҜ„еӯҳеҷЁпјҢжңүXMMгҖҒYMMжҲ–ZMMзӯүеҜ„еӯҳеҷЁпјҢжҳҜиҝӣиЎҢжө®зӮ№иҝҗз®—зҡ„дёҖз§Қиҫғж–°зҡ„ж–№жі•пјҢжө®зӮ№иҝҗз®—д»ҘеҚ•зІҫеәҰжҲ–еҸҢзІҫеәҰе®ҢжҲҗпјҢдёӯй—ҙз»“жһңзҡ„и®Ўз®—зІҫеәҰе§Ӣз»ҲдёҺж“ҚдҪңж•°зӣёеҗҢпјҢдҪҝз”Ёеҗ‘йҮҸеҜ„еӯҳеҷЁзҡ„дјҳзӮ№жңүпјҡ
е®ғд№ҹжңүзјәзӮ№пјҡ
еңЁеҮ д№ҺжүҖжңүе…·жңүжө®зӮ№иҝҗз®—иғҪеҠӣзҡ„зі»з»ҹдёӯпјҢйғҪеҸҜд»ҘдҪҝз”Ёx87жө®зӮ№еҜ„еӯҳеҷЁпјҢиҖҢXMMгҖҒYMMе’ҢZMMеҜ„еӯҳеҷЁеҲҶеҲ«йңҖиҰҒSSEгҖҒAVXе’ҢAVX512жҢҮд»ӨйӣҶгҖӮ
зҺ°д»Јзј–иҜ‘еҷЁпјҢжӣҙеӨҡжғ…еҶөдёӢдјҡдҪҝз”Ёеҗ‘йҮҸеҜ„еӯҳеҷЁпјҢжқҘиҝӣиЎҢжө®зӮ№иҝҗз®—гҖӮеҫҲе°‘жңүзј–иҜ‘еҷЁеҸҜд»Ҙж··еҗҲдёӨз§ҚдёҚеҗҢзұ»еһӢзҡ„жө®зӮ№иҝҗз®—пјҢдёҚиғҪдёәжҜҸж¬Ўиҝҗз®—йҖүжӢ©жңҖдјҳзұ»еһӢгҖӮеӨ§еӨҡж•°жғ…еҶөдёӢпјҢеҪ“жІЎжңүдҪҝз”Ёеҗ‘йҮҸиҝҗз®—ж—¶пјҢеҚ•зІҫеәҰжө®зӮ№ж•°иҝҗз®—е’ҢеҸҢзІҫеәҰжө®зӮ№ж•°иҝҗз®—йҖҹеәҰеӨ§дҪ“зӣёеҗҢпјҢж— и®әзІҫеәҰеҰӮдҪ•пјҢеҠ жі•гҖҒеҮҸжі•гҖҒд№ҳжі•зӯүиҝҗз®—зҡ„йҖҹеәҰйғҪжҳҜзӣёеҗҢзҡ„гҖӮдҪҶеҰӮжһңејҖеҗҜеҗ‘йҮҸиҝҗз®—пјҢдҪҝз”ЁXMMзӯүеҗ‘йҮҸеҜ„еӯҳеҷЁж—¶пјҢеҚ•зІҫеәҰйҷӨжі•гҖҒе№іж–№ж №е’Ңж•°еӯҰеҮҪж•°зҡ„и®Ўз®—йҖҹеәҰиҰҒжҜ”еҸҢзІҫеәҰеҝ«гҖӮ
еҰӮжһңзңҹзҡ„еҜ№зІҫеәҰжңүй«ҳиҰҒжұӮпјҢеҸҜд»ҘдҪҝз”ЁеҸҢзІҫеәҰжө®зӮ№ж•°пјҢдёҚйңҖиҰҒеӨӘжӢ…еҝғйҖҹеәҰгҖӮдҪҶеҰӮжһңжҲ‘们еҸҜд»ҘеҲ©з”ЁеҘҪеҗ‘йҮҸиҝҗз®—пјҢжҲ–иҖ…жңүдёӘеӨ§зҡ„жө®зӮ№ж•°ж•°з»„пјҢжғіиҰҒе……еҲҶеҲ©з”ЁCacheпјҢйӮЈеҸҜд»ҘиҖғиҷ‘дҪҝз”ЁеҚ•зІҫеәҰжө®зӮ№ж•°гҖӮ
жө®зӮ№еҠ жі•йңҖиҰҒ3 - 6дёӘж—¶й’ҹе‘ЁжңҹпјҢд№ҳжі•ж“ҚдҪңйңҖиҰҒ4 - 8дёӘж—¶й’ҹе‘ЁжңҹпјҢйҷӨжі•йңҖиҰҒ14 - 45дёӘж—¶й’ҹе‘ЁжңҹпјҢиҝҷеҸ–еҶідәҺCPUгҖӮеҪ“дҪҝз”Ёдј з»ҹзҡ„x87жө®зӮ№еҜ„еӯҳеҷЁж—¶пјҢжө®зӮ№ж•°жҜ”иҫғж“ҚдҪңпјҢе’Ңжө®зӮ№ж•°еҲ°ж•ҙж•°зҡ„иҪ¬жҚўж“ҚдҪңпјҢж•ҲзҺҮиҫғдҪҺгҖӮ
жіЁж„Ҹпјҡ
еҗҢдёҖдёӘиЎЁиҫҫејҸдёӯпјҢдёҚиҰҒж··еҗҲдҪҝз”ЁеҚ•зІҫеәҰе’ҢеҸҢзІҫеәҰжө®зӮ№ж•°гҖӮ
е°ҪйҮҸйҒҝе…Қж•ҙеһӢе’Ңжө®зӮ№еһӢзҡ„иҪ¬жҚўгҖӮ
еҗ‘йҮҸеҜ„еӯҳеҷЁж”ҜжҢҒеӨҡз§ҚжЁЎејҸпјҢеҸҜд»Ҙж №жҚ®е®һйҷ…йңҖиҰҒи®ҫзҪ®дёҚеҗҢзҡ„жЁЎејҸпјҢдҫӢеҰӮflush-to-zeroжЁЎејҸгҖҒdenormals-are-zeroжЁЎејҸзӯүгҖӮ
жһҡдёҫ
жһҡдёҫе…¶е®һе°ұжҳҜдёӘдјӘиЈ…зҡ„ж•ҙж•°пјҢе®ғзҡ„ж•ҲзҺҮдёҺж•ҙж•°зӣёеҗҢгҖӮжіЁж„ҸпјҢжһҡдёҫеҖјеҗҚеӯ—еҸҜиғҪдёҺдёҖдәӣеҸҳйҮҸжҲ–еҮҪж•°зҡ„еҗҚеӯ—еҸ‘з”ҹеҶІзӘҒпјҢеҸҜд»Ҙе°ҶеӨҙж–Ү件дёӯзҡ„жһҡдёҫи®ҫзҪ®жҲҗиҫғй•ҝдё”е”ҜдёҖзҡ„еҗҚеӯ—пјҢжҲ–иҖ…ж”ҫе…Ҙе‘ҪеҗҚз©әй—ҙпјҢд№ҹеҸҜд»ҘдҪҝз”Ёenum classеЈ°жҳҺжһҡдёҫгҖӮ
еёғе°”
еёғе°”ж“ҚдҪңзҡ„йЎәеәҸдјҳеҢ–
еёғе°”ж“ҚдҪңз¬Ұ&&е’Ң||зҡ„ж“ҚдҪңж•°жҢүд»ҘдёӢж–№ејҸи®Ўз®—гҖӮеҰӮжһң&&зҡ„第дёҖдёӘж“ҚдҪңж•°дёәfalseпјҢеҲҷж №жң¬дёҚ计算第дәҢдёӘж“ҚдҪңж•°пјҢеӣ дёәж— и®ә第дәҢдёӘж“ҚдҪңж•°зҡ„еҖјжҳҜеӨҡе°‘пјҢз»“жһңйғҪжҳҜfalseгҖӮеҗҢж ·пјҢеҰӮжһң||зҡ„第дёҖдёӘж“ҚдҪңж•°дёәtrueпјҢеҲҷдёҚ计算第дәҢдёӘж“ҚдҪңж•°пјҢеӣ дёәз»“жһңиӮҜе®ҡжҳҜtrueгҖӮ
жүҖд»ҘпјҢжҲ‘们еҸҜд»Ҙе°ҶйҖҡеёёдёәtrueзҡ„ж“ҚдҪңж•°ж”ҫеңЁ&&иЎЁиҫҫејҸзҡ„жңҖеҗҺпјҢжҲ–ж”ҫеңЁ||иЎЁиҫҫејҸзҡ„жңҖејҖе§ӢгҖӮдҫӢеҰӮпјҢеҒҮи®ҫaеңЁ50%зҡ„жғ…еҶөдёӢдёәзңҹпјҢbеңЁ10%зҡ„жғ…еҶөдёӢдёәзңҹгҖӮеҪ“aдёәзңҹж—¶пјҢиЎЁиҫҫејҸa && bйңҖиҰҒи®Ўз®—bпјҢиҝҷжҳҜ50%зҡ„жғ…еҶөгҖӮзӯүд»·зҡ„иЎЁиҫҫејҸb && aеҸӘйңҖиҰҒеңЁbдёәзңҹж—¶и®Ўз®—aпјҢиҝҷеҸӘеҚ 10%зҡ„ж—¶й—ҙгҖӮ
еҰӮжһңдёҖдёӘж“ҚдҪңж•°жҜ”еҸҰдёҖдёӘж“ҚдҪңж•°жӣҙеҸҜйў„жөӢпјҢйӮЈд№Ҳе°ҶжңҖеҸҜйў„жөӢзҡ„ж“ҚдҪңж•°ж”ҫеңЁеүҚйқўгҖӮ
еҰӮжһңдёҖдёӘж“ҚдҪңж•°жҜ”еҸҰдёҖдёӘж“ҚдҪңж•°и®Ўз®—еҫ—еҝ«пјҢйӮЈд№Ҳе°Ҷи®Ўз®—еҫ—жңҖеҝ«зҡ„ж“ҚдҪңж•°ж”ҫеңЁеүҚйқўгҖӮ
дҪҶжҳҜпјҢеңЁж”№еҸҳеёғе°”ж“ҚдҪңж•°зҡ„йЎәеәҸеҝ…йЎ»иҰҒе°ҸеҝғпјҡеҰӮжһңж“ҚдҪңж•°зҡ„и®Ўз®—жңүеүҜдҪңз”ЁпјҢеҰӮжһң第дёҖдёӘж“ҚдҪңж•°иў«з”ЁжқҘзЎ®е®ҡ第дәҢдёӘж“ҚдҪңж•°жҳҜеҗҰжңүж•ҲпјҢеҲҷдёҚиғҪдәӨжҚўж“ҚдҪңж•°гҖӮдҫӢеҰӮпјҡ
unsigned int i; const int ARRAYSIZE = 100; float list[ARRAYSIZE]; if (i < ARRAYSIZE && list[i] > 3) {...}иҝҷйҮҢжҲ‘们дёҚиғҪдәӨжҚўйЎәеәҸпјҢеӣ дёәеҪ“i>ARRAYSIZEж—¶пјҢlist[i]ж“ҚдҪңжҳҜйқһжі•зҡ„пјҢеҸҰдёҖдёӘдҫӢеӯҗпјҡ
if (handle != INVALID_HANDLE_VALUE && WriteFile(handle, ...)) {...}еҗҢж ·пјҢиҝҷйҮҢжҲ‘们д№ҹдёҚеҸҜиғҪдәӨжҚўйЎәеәҸгҖӮ
еёғе°”еҖј
еёғе°”еҸҳйҮҸиў«еӯҳеӮЁдёә8дҪҚж•ҙж•°пјҢеҖјдёә0иЎЁзӨәfalse, 1иЎЁзӨәtrueгҖӮжӯӨз§Қж„Ҹд№үдёҠпјҢеёғе°”еҸҳйҮҸз”ұеӨҡз§Қеӣ зҙ зЎ®е®ҡпјҢеҚіжүҖжңүд»Ҙеёғе°”еҸҳйҮҸдҪңдёәиҫ“е…Ҙзҡ„ж“ҚдҪңз¬ҰпјҢжңүеҸҜиғҪдёҚеҸӘжҳҜ0е’Ң1пјҢиҖҢд»Ҙеёғе°”еҸҳйҮҸдҪңдёәиҫ“еҮәзҡ„ж“ҚдҪңз¬ҰпјҢеҸӘиғҪдә§еҮә0жҲ–1зҡ„еҖјгҖӮиҝҷж ·еҸҜиғҪеёғе°”еҸҳйҮҸдҪңдёәиҫ“е…Ҙзҡ„ж“ҚдҪңж•ҲзҺҮиҫғдҪҺгҖӮ
дёҫдҫӢжқҘиҜҙпјҢеҜ№дәҺ
bool a, b, c, d; c = a && b; d = a || b;
иҖҢзј–иҜ‘еҷЁеҸҜиғҪжҳҜиҝҷд№Ҳе®һзҺ°зҡ„пјҡ
bool a, b, c, d; if (a != 0) { if (b != 0) { c = 1; } else { goto cfalse; } } else { cfalse: c = 0; } if (a == 0) { if (b == 0) { d = 0; } else { goto dtrue; } } else { dtrue: d = 1; }еҪ“然пјҢиҝҷдёҚжҳҜжңҖдјҳж–№ејҸгҖӮеңЁй”ҷиҜҜйў„жөӢзҡ„жғ…еҶөдёӢпјҢеҲҶж”ҜеҸҜиғҪиҝҳйңҖиҰҒеҫҲй•ҝж—¶й—ҙгҖӮеҰӮжһңеҸҜд»ҘзЎ®е®ҡж“ҚдҪңж•°йҷӨдәҶ0е’Ң1д№ӢеӨ–пјҢжІЎжңүе…¶д»–еҖјпјҢйӮЈд№Ҳеёғе°”ж“ҚдҪңзҡ„ж•ҲзҺҮдјҡй«ҳеҫ—еӨҡгҖӮзј–иҜ‘еҷЁжІЎжңүеҒҡиҝҷж ·зҡ„еҒҮи®ҫзҡ„еҺҹеӣ жҳҜпјҢеҰӮжһңеҸҳйҮҸжІЎжңүеҲқе§ӢеҢ–пјҢжҲ–иҖ…жқҘжәҗжңӘзҹҘпјҢйӮЈд№Ҳе®ғ们еҸҜиғҪжңүе…¶е®ғзҡ„еҖјгҖӮеҰӮжһңaе’Ңbе·Із»ҸеҲқе§ӢеҢ–дёәжңүж•ҲеҖјпјҢжҲ–иҖ…е®ғ们жқҘиҮӘдә§з”ҹеёғе°”иҫ“еҮәзҡ„еҖјпјҢеҲҷеҸҜд»ҘдјҳеҢ–дёҠиҝ°д»Јз ҒгҖӮдјҳеҢ–еҗҺзҡ„д»Јз ҒеҰӮдёӢжүҖзӨәпјҡ
char a = 0, b = 0, c, d; c = a & b; d = a | b;
иҝҷйҮҢпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ёchar(жҲ–int)д»ЈжӣҝboolпјҢд»ҘдҫҝиғҪеӨҹдҪҝз”ЁдҪҚж“ҚдҪңз¬Ұ(&е’Ң|)иҖҢдёҚжҳҜеёғе°”ж“ҚдҪңз¬Ұ(&&е’Ң||)гҖӮжҢүдҪҚж“ҚдҪңз¬ҰпјҢжҳҜеҸӘеҚ з”ЁдёҖдёӘж—¶й’ҹе‘Ёжңҹзҡ„еҚ•дёӘжҢҮд»ӨгҖӮеҚідҪҝaе’Ңbзҡ„еҖјдёҚжҳҜ0жҲ–1пјҢORж“ҚдҪңз¬Ұ(|)д№ҹеҸҜд»Ҙе·ҘдҪңгҖӮдҪҶеҰӮжһңж“ҚдҪңж•°зҡ„еҖјдёҚжҳҜ0е’Ң1пјҢеҲҷANDж“ҚдҪңз¬Ұ(&)е’ҢејӮжҲ–ж“ҚдҪңз¬Ұ(^)еҸҜиғҪдјҡдә§з”ҹдёҚдёҖиҮҙзҡ„з»“жһңгҖӮ
жіЁж„ҸиҝҷйҮҢжңүдёӘеқ‘пјҢжҲ‘们дёҚиғҪдҪҝз”Ё~д»Јжӣҝ!пјҢзӣёеҸҚпјҢеҰӮжһңзЎ®е®ҡиҫ“е…ҘжҳҜ0жҲ–1пјҢеҸҜд»ҘйҖҡиҝҮдёҺ1еҒҡејӮжҲ–жқҘеҫ—еҲ°!зҡ„еҖјгҖӮ
дёҫдҫӢпјҡ
bool a, b; b = !a;
еҸҜд»Ҙиў«дјҳеҢ–жҲҗпјҡ
char a = 0, b; b = a ^ 1;
жҢҮй’Ҳе’Ңеј•з”Ё
зңӢд»Јз Ғпјҡ
void FuncA(int *p) { *p = *p + 2; } void FuncB(int &r) { r = r + 2; }иҝҷдёӨж®өеҲҶеҲ«дҪҝз”ЁжҢҮй’Ҳе’Ңеј•з”Ёзҡ„д»Јз ҒпјҢе®ғ们е®һйҷ…дёҠеҒҡзҡ„жҳҜзӣёеҗҢзҡ„дәӢжғ…пјҢе…·дҪ“жҲ‘们еҸҜд»ҘзңӢе®ғ们编иҜ‘еҗҺз”ҹжҲҗзҡ„д»Јз ҒпјҢе…¶е®һе®ғ们зҡ„жұҮзј–д»Јз Ғе®Ңе…ЁзӣёеҗҢпјҢеҢәеҲ«д»…д»…жҳҜзј–зЁӢйЈҺж јзҡ„й—®йўҳгҖӮ
жҢҮй’ҲдјҳдәҺеј•з”Ёзҡ„зҗҶз”ұжҳҜпјҡ
зӣҙжҺҘзңӢдёҠйқўзҡ„еҮҪж•°дҪ“пјҢеҫҲжҳҺжҳҫзңӢеҮәpжҳҜдёҖдёӘжҢҮй’ҲпјҢдҪҶдёҚжё…жҘҡrжҳҜдёҖдёӘеј•з”ЁпјҢиҝҳжҳҜдёҖдёӘз®ҖеҚ•зҡ„еҸҳйҮҸпјҢдҪҝз”ЁжҢҮй’Ҳи®©йҳ…иҜ»д»Јз Ғзҡ„дәәжӣҙжё…жҘҡең°зҹҘйҒ“еҸ‘з”ҹдәҶд»Җд№ҲгҖӮ
жҢҮй’Ҳзҡ„жҢҮеҗ‘еҸҜд»Ҙжӣҙж”№пјҢдҪҝз”ЁжӣҙзҒөжҙ»пјҢиҝҳеҸҜд»Ҙз”ЁжҢҮй’ҲеҒҡз®—жңҜиҝҗз®—гҖӮ
еј•з”ЁдјҳдәҺжҢҮй’Ҳзҡ„зҗҶз”ұжҳҜпјҡ
еј•з”ЁжҜ”жҢҮй’Ҳжӣҙе®үе…ЁпјҢеӣ дёәеңЁеӨ§еӨҡж•°жғ…еҶөдёӢпјҢеј•з”ЁиӮҜе®ҡжҢҮеҗ‘дёҖдёӘжңүж•Ҳзҡ„ең°еқҖпјҢиҖҢдё”еј•з”Ёзҡ„жҢҮеҗ‘дёҚеҸҜжӣҙж”№гҖӮиҖҢеҜ№дәҺжҢҮй’ҲпјҢеҰӮжһңжІЎжңүеҲқе§ӢеҢ–пјҢйӮЈжҢҮй’Ҳз®—жңҜи®Ўз®—и¶…еҮәдәҶжңүж•Ҳең°еқҖзҡ„иҢғеӣҙпјҢжҲ–иҖ…жҢҮй’Ҳзұ»еһӢиҪ¬жҚўдёәй”ҷиҜҜзҡ„зұ»еһӢпјҢйӮЈд№ҲжҢҮй’ҲеҸҜиғҪжҳҜж— ж•Ҳзҡ„пјҢ并еҜјиҮҙиҮҙе‘Ҫй”ҷиҜҜгҖӮ
еј•з”ЁеҜ№дәҺеӨҚеҲ¶жһ„йҖ еҮҪж•°е’ҢйҮҚиҪҪиҝҗз®—з¬ҰеҫҲжңүз”ЁгҖӮ
еЈ°жҳҺдёәеёёйҮҸеј•з”Ёзҡ„еҮҪж•°еҪўеҸӮпјҢеҸҜжҺҘеҸ—иЎЁиҫҫејҸдҪңдёәе®һеҸӮпјҢиҖҢжҢҮй’Ҳе’ҢйқһеёёйҮҸеј•з”ЁйңҖиҰҒеҸҳйҮҸгҖӮ
дҪҝз”ЁжҢҮй’ҲжҲ–еј•з”Ёи®ҝй—®еҸҳйҮҸпјҢеҸҜиғҪдёҺзӣҙжҺҘи®ҝй—®дёҖж ·еҝ«гҖӮеҮҪж•°дёӯеЈ°жҳҺзҡ„жүҖжңүйқһйқҷжҖҒеҸҳйҮҸпјҢйғҪеӯҳеӮЁеңЁж ҲдёҠпјҢе®һйҷ…дёҠе®ғ们д№ҹжҳҜйҖҡиҝҮж ҲжҢҮй’ҲиҝӣиЎҢеҜ»еқҖгҖӮеҗҢж ·зҡ„пјҢзұ»дёӯеЈ°жҳҺзҡ„жүҖжңүйқһйқҷжҖҒеҸҳйҮҸпјҢд№ҹжҳҜйҖҡиҝҮйҡҗејҸзҡ„thisжҢҮй’Ҳи®ҝй—®пјҢжүҖд»ҘпјҢеӨ§еӨҡж•°еҸҳйҮҸе®һйҷ…дёҠйғҪжҳҜйҖҡиҝҮжҢҮй’Ҳи®ҝй—®гҖӮ
дҪҝз”ЁжҢҮй’ҲжҲ–еј•з”Ёд№ҹжңүзјәзӮ№пјҢе®ғйңҖиҰҒдёҖдёӘйўқеӨ–зҡ„еҜ„еӯҳеҷЁжқҘдҝқеӯҳжҢҮй’ҲжҲ–еј•з”Ёзҡ„еҖјпјҢиҖҢеҜ„еӯҳеҷЁжҳҜдёҖз§ҚзЁҖзјәиө„жәҗпјҢзү№еҲ«жҳҜеңЁ32дҪҚжЁЎејҸдёӢгҖӮеҰӮжһңеҜ„еӯҳеҷЁж•°йҮҸдёҚи¶іпјҢйӮЈд№ҲжҜҸж¬ЎдҪҝз”ЁжҢҮй’Ҳж—¶йғҪеҝ…йЎ»д»ҺеҶ…еӯҳдёӯеҠ иҪҪпјҢйҖҹеәҰе°ұдјҡеҸҳж…ўгҖӮ
жіЁж„ҸжҢҮй’ҲиҝҷйҮҢжңүдёӘеқ‘пјҡеҚіжҢҮй’Ҳзҡ„з®—ж•°иҝҗз®—пјҡ
struct A { int a; int b; }; A *a; a = ++a; a = ++(char*)a;++aе’Ң++(void*)aпјҢе®ғ们зҡ„иҝҗз®—з»“жһңжҳҜдёҚеҗҢзҡ„пјҢ++aйҮҢе…¶е®һеҠ зҡ„еҖјжҳҜ8пјҢеӣ дёәAеӨ§е°ҸжҳҜ8пјҢ++(void*)aйҮҢе…¶е®һеҠ зҡ„еҖјжҳҜ1пјҢеӣ дёә(char)еӨ§е°ҸжҳҜ1гҖӮ
еҮҪж•°жҢҮй’Ҳ
еҰӮжһңзӣ®ж Үең°еқҖеҸҜд»Ҙйў„жөӢпјҢйҖҡиҝҮеҮҪж•°жҢҮй’Ҳи°ғз”ЁеҮҪж•°пјҢзӣёжҜ”дәҺзӣҙжҺҘи°ғз”ЁеҮҪж•°пјҢиҰҒеӨҡиҠұеҮ дёӘж—¶й’ҹе‘ЁжңҹгҖӮеҰӮжһңеҮҪж•°жҢҮй’Ҳзҡ„еҖјпјҢдёҺдёҠж¬Ўжү§иЎҢиҜӯеҸҘж—¶зӣёеҗҢпјҢеҲҷзӣ®ж Үең°еқҖдјҡиў«йў„жөӢжҲҗеҠҹпјҢиҖҢеҰӮжһңеҮҪж•°жҢҮй’Ҳзҡ„еҖјеҸ‘з”ҹеҸҳеҢ–пјҢзӣ®ж Үең°еқҖеҫҲеҸҜиғҪдјҡиў«й”ҷиҜҜйў„жөӢпјҢйў„жөӢеӨұиҙҘдјҡеҜјиҮҙжңүеӨҡдёӘж—¶й’ҹе‘Ёжңҹзҡ„延иҝҹгҖӮ
жҷәиғҪжҢҮй’Ҳ
жҷәиғҪжҢҮй’ҲжҳҜдёҖз§ҚиЎҢдёәдёҺжҢҮй’Ҳзұ»дјјзҡ„еҜ№иұЎгҖӮC++11еҗҺеҹәжң¬дёҠжңүдёӨз§ҚжҷәиғҪжҢҮй’ҲпјҢunique_ptrе’Ңshared_ptrпјҢunique_ptrзҡ„зү№зӮ№жҳҜжңүдё”еҸӘжңүдёҖдёӘжҢҮй’ҲжӢҘжңүжүҖеҲҶй…Қзҡ„еҜ№иұЎпјҢеҸӘжңүдёҖдёӘеҜ№иұЎжҢҮй’ҲжӢҘжңүеҜ№иұЎзҡ„жүҖжңүжқғпјҢиҖҢshared_ptrзҡ„зү№зӮ№жҳҜеҸҜд»ҘжңүеӨҡдёӘжҢҮй’Ҳе…ұеҗҢжҢҮеҗ‘еҗҢдёҖдёӘеҜ№иұЎпјҢжҳҫ然shared_ptrжҜ”unique_ptrзҡ„ејҖй”ҖжӣҙеӨ§дёҖдәӣгҖӮйҖүжӢ©жҷәиғҪжҢҮй’Ҳж—¶еҸҜд»ҘжӣҙеӨҡзҡ„йҖүжӢ©unique_ptrпјҢзј–иҜ‘еҷЁеҸҜд»ҘеҒҡдјҳеҢ–пјҢиғҪеӨҹеңЁз®ҖеҚ•жғ…еҶөдёӢеүҘзҰ»жҺүunique_ptrзҡ„еӨ§йғЁеҲҶжҲ–иҖ…е…ЁйғЁејҖй”ҖпјҢиҝҷж ·ж•ҲзҺҮе°ұе’ҢзӣҙжҺҘдҪҝз”Ёnewе’Ңdeleteеҹәжң¬зӣёеҗҢгҖӮдёҖиҲ¬дёҖдёӘеҮҪж•°еҶ…newпјҢйңҖиҰҒеҸҰдёҖдёӘеҮҪж•°еҶ…deleteзҡ„еңәжҷҜдёӢпјҢеҸҜд»ҘиҖғиҷ‘дҪҝз”ЁжҷәиғҪжҢҮй’ҲгҖӮдҪҶеҰӮжһңеңЁеҗҢдёҖдёӘеҮҪж•°еҶ…newе’ҢdeleteпјҢдё”еҮҪж•°дҪ“жІЎжңүиҝҮеӨҡзҡ„еҲҶж”ҜпјҢжҲ–и®ёе°ұдёҚйңҖиҰҒдҪҝз”ЁжҷәиғҪжҢҮй’Ҳе•ҰгҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңC++д»Јз Ғж“ҚдҪңзҡ„ж•ҲзҺҮжңүе“ӘдәӣвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№C++д»Јз Ғж“ҚдҪңзҡ„ж•ҲзҺҮжңүе“ӘдәӣиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ





