bind_address = 0.0.0.0,然后重启 Scrapyd service。pip install scrapydwebscrapydweb 启动 ScrapydWeb(首次启动将自动在当前工作目录生成配置文件)。ENABLE_AUTH = True
USERNAME = 'username'
PASSWORD = 'password'SCRAPYD_SERVERS = [
'127.0.0.1',
# 'username:password@localhost:6801#group',
('username', 'password', 'localhost', '6801', 'group'),
]scrapydweb 重启 ScrapydWeb。通过浏览器访问并登录 http://127.0.0.1:5000。
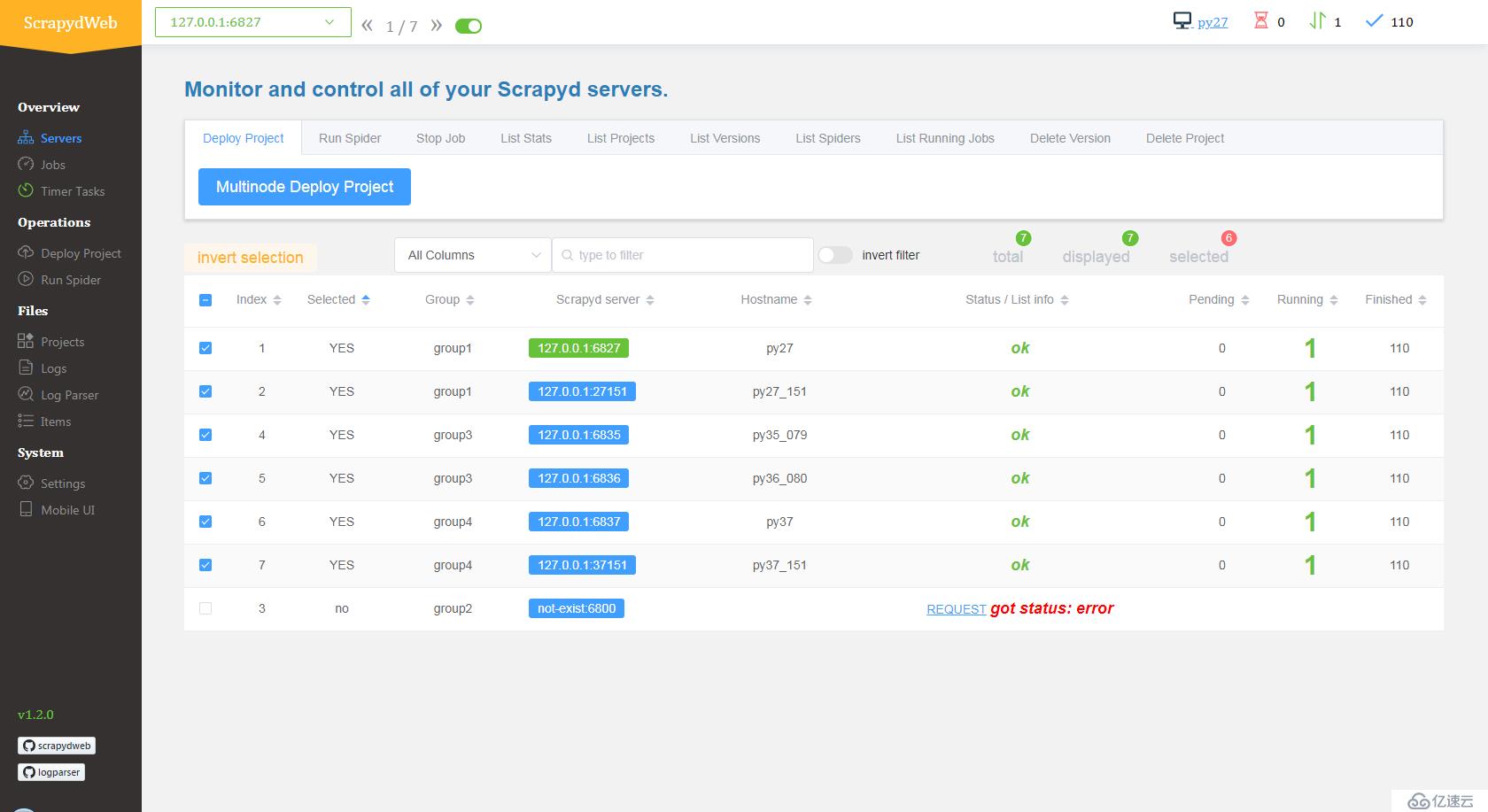
SCRAPY_PROJECTS_DIR 指定 Scrapy 项目开发目录,ScrapydWeb 将自动列出该路径下的所有项目,默认选定最新编辑的项目,选择项目后即可自动打包和部署指定项目。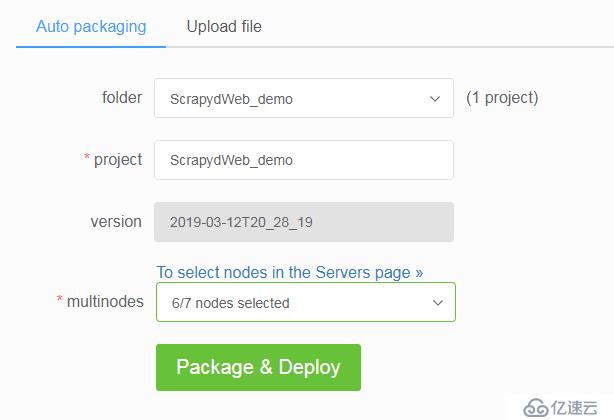
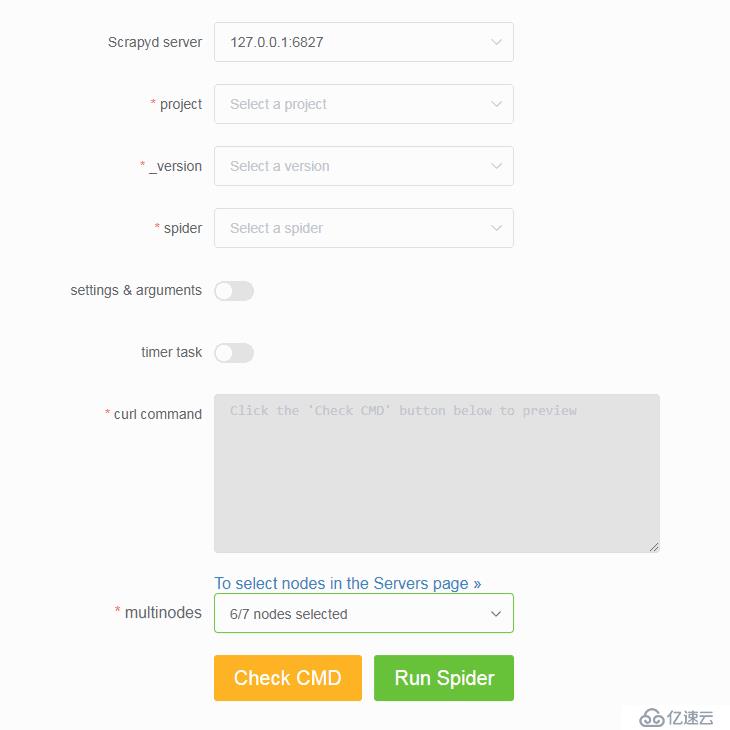
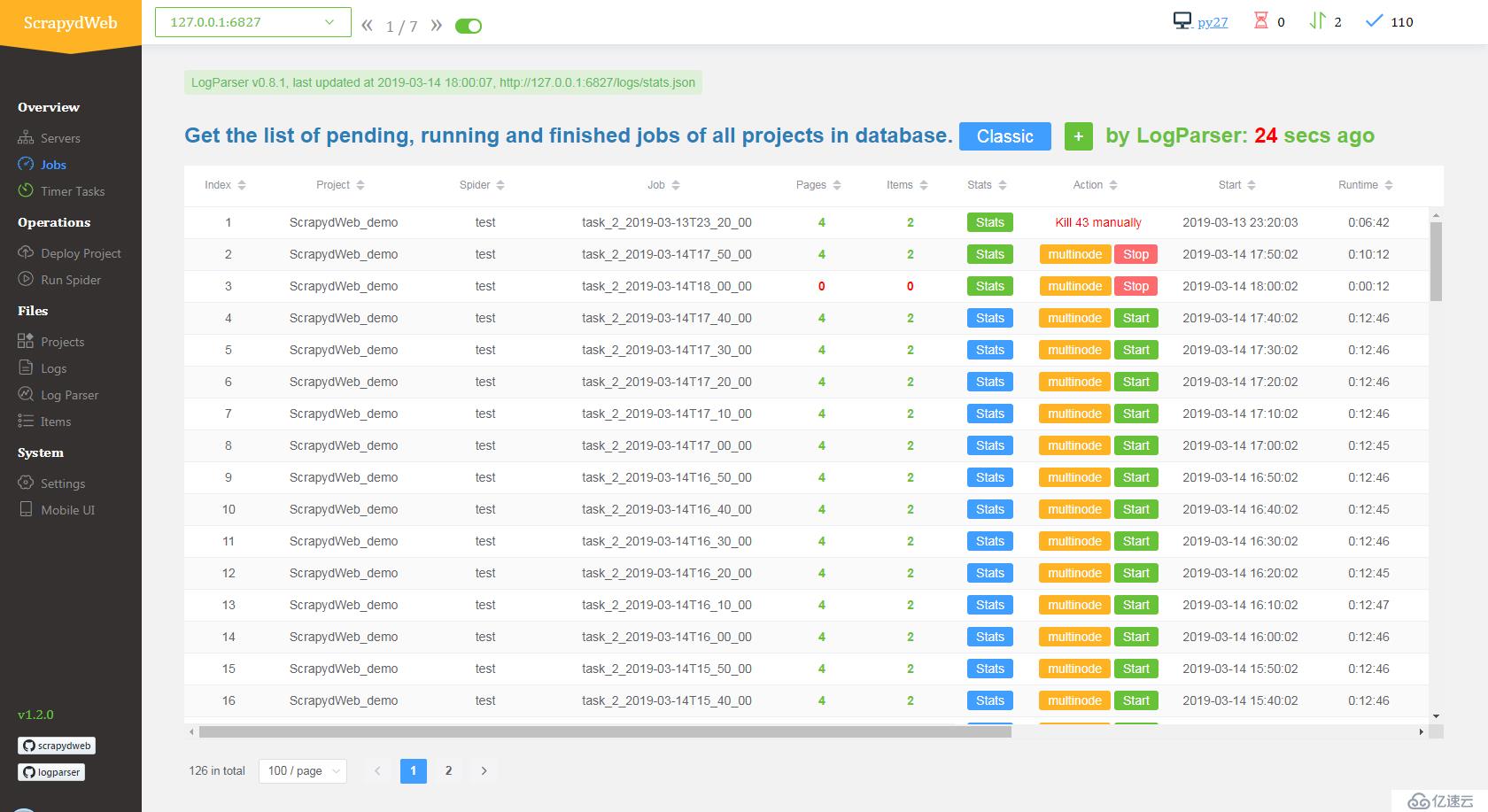
SCRAPYD_LOGS_DIR 和 ENABLE_LOGPARSER,则启动 ScrapydWeb 时将自动运行 LogParser,该子进程通过定时增量式解析指定目录下的 Scrapy 日志文件以加快 Stats 页面的生成,避免因请求原始日志文件而占用大量内存和网络资源。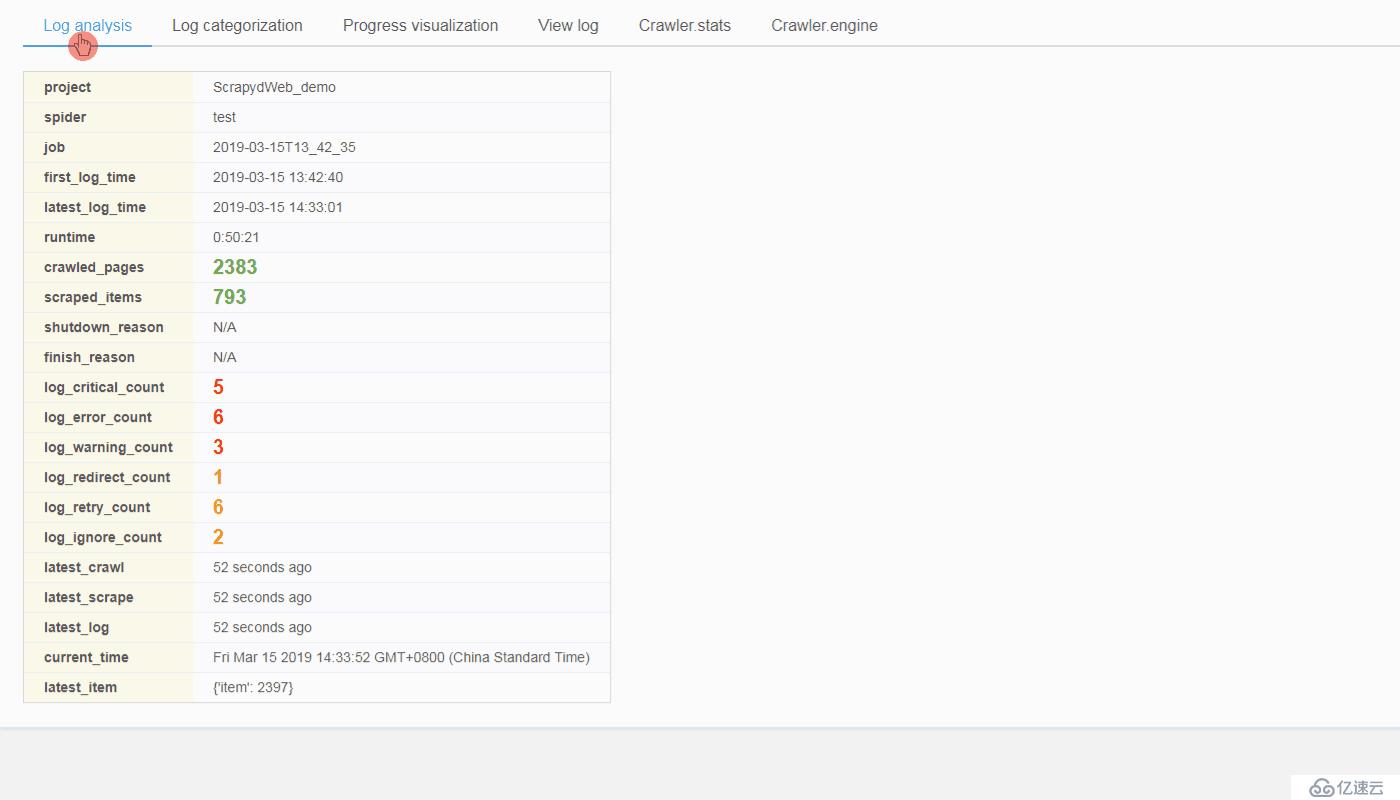
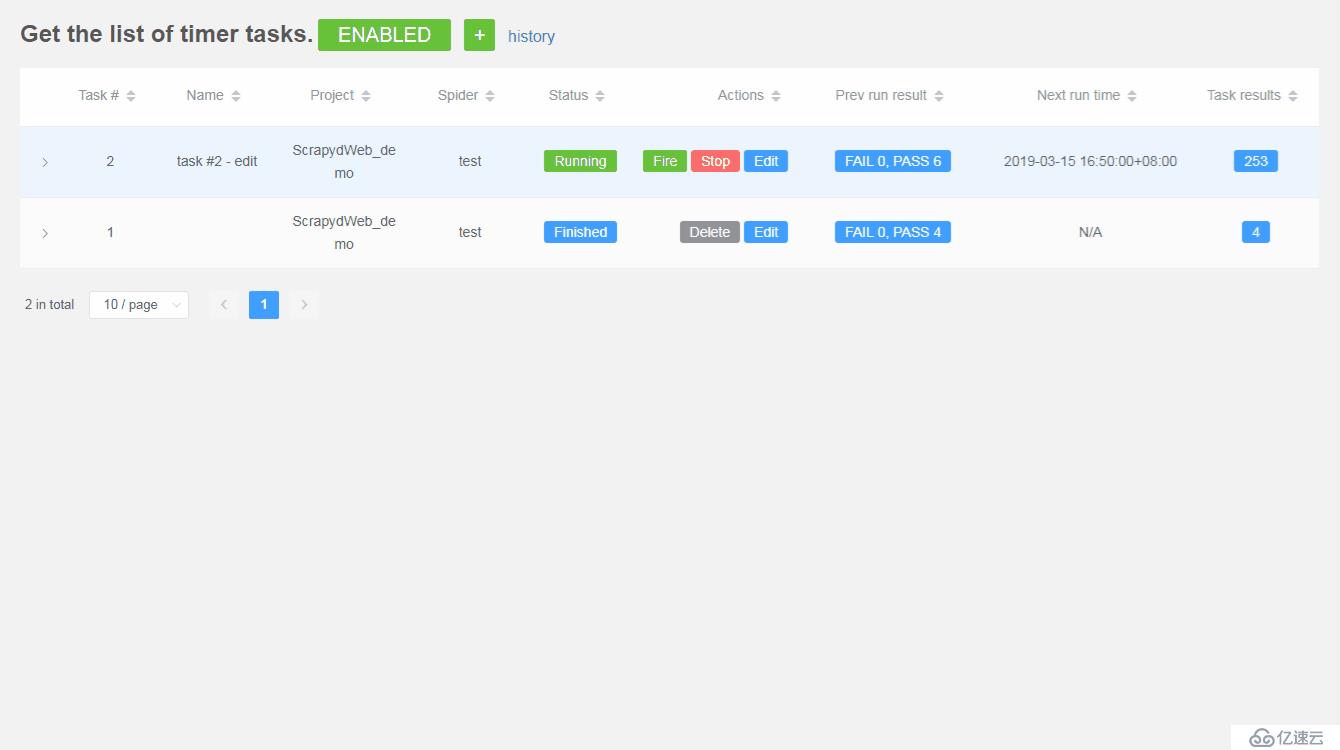
通过轮询子进程在后台定时模拟访问 Stats 页面,ScrapydWeb 将在满足特定触发器时根据设定自动停止爬虫任务并发送通知邮件,邮件正文包含当前爬虫任务的统计信息。
SMTP_SERVER = 'smtp.qq.com'
SMTP_PORT = 465
SMTP_OVER_SSL = True
SMTP_CONNECTION_TIMEOUT = 10EMAIL_USERNAME = '' # defaults to FROM_ADDR
EMAIL_PASSWORD = 'password'
FROM_ADDR = 'username@qq.com'
TO_ADDRS = [FROM_ADDR]
2. 设置邮件工作时间和基本触发器,以下示例代表:每隔1小时或当某一任务完成时,并且当前时间是工作日的9点,12点和17点,*ScrapydWeb* 将会发送通知邮件。
```python
EMAIL_WORKING_DAYS = [1, 2, 3, 4, 5]
EMAIL_WORKING_HOURS = [9, 12, 17]
ON_JOB_RUNNING_INTERVAL = 3600
ON_JOB_FINISHED = TrueLOG_CRITICAL_THRESHOLD = 3
LOG_CRITICAL_TRIGGER_STOP = True
LOG_CRITICAL_TRIGGER_FORCESTOP = False
# ...
LOG_IGNORE_TRIGGER_FORCESTOP = False以上示例代表:当日志中出现3条或以上的 critical 级别的 log 时,ScrapydWeb 将自动停止当前任务,如果当前时间在邮件工作时间内,则同时发送通知邮件。
my8100/scrapydweb
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





