如何优化Python代码,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
优化是什么?
首先定义什么是优化。我们将使用一个直观的示例进行此操作。
这是我们的问题:
假设给定一个数组,其中每个索引代表一个城市,该索引的值代表该城市与下一个城市之间的距离。假设我们有两个索引,我们需要计算这两个索引之间的总距离。简单来说,我们需要找到两个给定索引之间距离的总和。

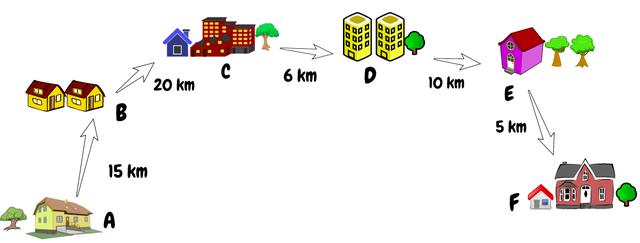
首先想到的是,一个简单的FOR循环在这里可以很好地工作。但是,如果有100,000多个城市,而我们每秒接收50,000多个查询,该怎么办?你是否仍然认为FOR循环可以为我们的问题提供足够好的解决方案?
FOR循环并不能提供足够好的方案。这时候优化就派上用场了
简单地说,代码优化意味着在生成正确结果的同时减少执行任何任务的操作数。
让我们计算一下FOR循环执行此任务所需的操作数:

我们必须在上面的数组中找出索引1和索引3的城市之间的距离。

对于较小的数组大小,循环的性能良好
如果数组大小为100,000,查询数量为50,000,该怎么办?

这是一个很大的数字。如果数组的大小和查询数量进一步增加,我们的FOR循环将花费大量时间。你能想到一种优化的方法,使我们在使用较少数量的解决方案时可以产生正确的结果吗?
在这里,我将讨论一个更好的解决方案,通过使用前缀数组来计算距离来解决这个问题。让我们看看它是如何工作的:

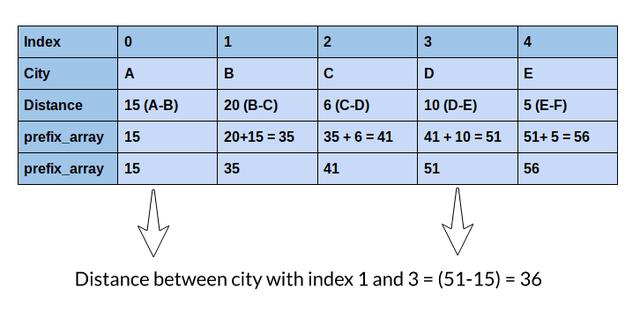

你能理解吗?我们只需一次操作就可以得到相同的距离!关于此方法的最好之处在于,无论索引之间的差是1还是100,000,都只需执行一个操作即可计算任意两个索引之间的距离。
我创建了一个样本数据集,其数组大小为100,000和50,000个查询。你可以自己执行代码来比较两者所用的时间
注意:数据集总共有50,000个查询,你可以更改参数execute_queries以执行最多50,000个查询,并查看每种方法执行任务所花费的时间。
import time from tqdm import tqdm data_file = open('sample-data.txt', 'r') distance_between_city = data_file.readline().split() queries = data_file.readlines() print('SIZE OF ARRAY = ', len(distance_between_city)) print('TOTAL NUMBER OF QUERIES = ', len(queries)) data_file.close() # 分配要执行的查询数 execute_queries = 2000 print('\n\nExecuting',execute_queries,'Queries') # FOR循环方法 # 读取文件并存储距离和查询 start_time_for_loop = time.time() data_file = open('sample-data.txt', 'r') distance_between_city = data_file.readline().split() queries = data_file.readlines() # 存储距离的列表 distances_for_loop = [] # 计算开始索引和结束索引之间的距离的函数 def calculateDistance(startIndex, endIndex): distance = 0 for number in range(startIndex, endIndex+1, 1): distance += int(distance_between_city[number]) return distance for query in tqdm(queries[:execute_queries]): query = query.split() startIndex = int(query[0]) endIndex = int(query[1]) distances_for_loop.append(calculateDistance(startIndex,endIndex)) data_file.close() # 获取结束时间 end_time_for_loop = time.time() print('\n\nTime Taken to execute task by for loop :', (end_time_for_loop-start_time_for_loop),'seconds') # 前缀数组方法 # 读取文件并存储距离和查询 start_time_for_prefix = time.time() data_file = open('sample-data.txt', 'r') distance_between_city = data_file.readline().split() queries = data_file.readlines() # 存储距离列表 distances_for_prefix_array = [] # 创建前缀数组 prefix_array = [] prefix_array.append(int(distance_between_city[0])) for i in range(1, 100000, 1): prefix_array.append((int(distance_between_city[i]) + prefix_array[i-1])) for query in tqdm(queries[:execute_queries]): query = query.split() startIndex = int(query[0]) endIndex = int(query[1]) if startIndex == 0: distances_for_prefix_array.append(prefix_array[endIndex]) else: distances_for_prefix_array.append((prefix_array[endIndex]-prefix_array[startIndex-1])) data_file.close() end_time_for_prefix = time.time() print('\n\nTime Taken by Prefix Array to execute task is : ', (end_time_for_prefix-start_time_for_prefix), 'seconds') # 检查结果 correct = True for result in range(0,execute_queries): if distances_for_loop[result] != distances_for_prefix_array[result] : correct = False if correct: print('\n\nDistance calculated by both the methods matched.') else: print('\n\nResults did not matched!!')结果极大的节省了时间,这就是优化Python代码的重要性。我们不仅节省时间,而且还可以节省很多计算资源!
你可能想知道这些如何应用于数据科学项目。你可能已经注意到,很多时候我们必须对大量数据点执行相同的查询。在数据预处理阶段尤其如此。
我们必须使用一些优化的技术而不是基本的编程来尽可能快速高效地完成工作。因此,这里我将分享一些我用来改进和优化Python代码的优秀技术
1. Pandas.apply() | 特征工程的钻石级函数
Pandas已经是一个高度优化的库,但是我们大多数人仍然没有充分利用它。现在你思考一下在数据科学中会使用它的常见地方。
我能想到的一项是特征工程,我们使用现有特征创建新特征。最有效的方法之一是使用Pandas.apply()。
在这里,我们可以传递用户定义的函数,并将其应用于Pandas序列化数据的每个数据点。它是Pandas库中很好的插件之一,因为此函数可以根据所需条件选择性隔离数据。所以,我们可以有效地将其用于数据处理任务。
让我们使用Twitter情绪分析数据来计算每条推文的字数。我们将使用不同的方法,例如dataframe iterrows方法,NumPy数组和apply方法。你可以从此处下载数据集(https://datahack.analyticsvidhya.com/contest/practice-problem-twitter-sentiment-analysis/?utm_source=blog&utm_medium=4-methods-optimize-python-code-data-science)。
''' 优化方法:apply方法 ''' # 导入库 import pandas as pd import numpy as np import time import math data = pd.read_csv('train_E6oV3lV.csv') # 打印头部信息 print(data.head()) # 使用dataframe iterows计算字符数 print('\n\nUsing Iterrows\n\n') start_time = time.time() data_1 = data.copy() n_words = [] for i, row in data_1.iterrows(): n_words.append(len(row['tweet'].split())) data_1['n_words'] = n_words print(data_1[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by iterrows :', (end_time-start_time),'seconds') # 使用Numpy数组计算字符数 print('\n\nUsing Numpy Arrays\n\n') start_time = time.time() data_2 = data.copy() n_words_2 = [] for row in data_2.values: n_words_2.append(len(row[2].split())) data_2['n_words'] = n_words_2 print(data_2[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by numpy array : ', (end_time-start_time),'seconds') # 使用apply方法计算字符数 print('\n\nUsing Apply Method\n\n') start_time = time.time() data_3 = data.copy() data_3['n_words'] = data_3['tweet'].apply(lambda x : len(x.split())) print(data_3[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by Apply Method : ', (end_time-start_time),'seconds')你可能已经注意到apply方法比iterrows方法快得多。其性能可媲美与NumPy数组,但apply方法提供了更多的灵活性。你可以在此处阅读apply方法的文档。(https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html)
2. Pandas.DataFrame.loc | Python数据处理的技巧
这是我最喜欢的Pandas库的技巧之一。我觉得对于处理数据任务的数据科学家来说,这是一个必须知道的方法(所以几乎每个人都是这样!)
大多数时候,我们只需要根据某些条件来更新数据集中特定列的某些值。Pandas.DataFrame.loc为我们提供了针对此类问题的优化的解决方案。
让我们使用loc函数解决一个问题。你可以在此处下载将要使用的数据集(https://drive.google.com/file/d/1VwXDA27zgx5jIq8C7NQW0A5rtE95e3XI/view?usp=sharing)。
# 导入库 import pandas as pd data = pd.read_csv('school.csv') data.head()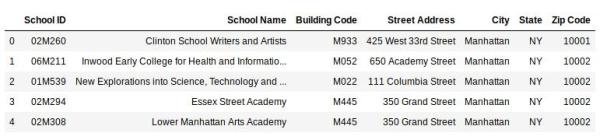
检查“City”变量的各个值的频数:
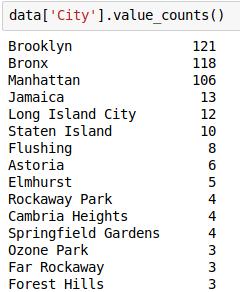
现在,假设我们只需要排名前5位的城市,并希望将其余城市替换为“Others”(其他)城市。因此,让我们这么写:
# 将热门城市保存在列表中 top_cities = ['Brooklyn','Bronx','Manhattan','Jamaica','Long Island City'] # 使用loc更新目标 data.loc[(data.City.isin(top_cities) == False),'City'] = 'Others' # 各个城市的频数 data.City.value_counts()
Pandas来更新数据的值是非常容易的!这是解决此类数据处理任务的优化方法。
3.在Python中向量化你的函数
摆脱慢循环的另一种方法是对函数进行向量化处理。这意味着新创建的函数将应用于输入列表,并将返回结果数组。Python中的向量化可以加速计算
让我们在相同的Twitter Sentiment Analysis数据集对此进行验证。
''' 优化方法:向量化函数 ''' # 导入库 import pandas as pd import numpy as np import time import math data = pd.read_csv('train_E6oV3lV.csv') # 输出头部信息 print(data.head()) def word_count(x) : return len(x.split()) # 使用Dataframe iterrows 计算词的个数 print('\n\nUsing Iterrows\n\n') start_time = time.time() data_1 = data.copy() n_words = [] for i, row in data_1.iterrows(): n_words.append(word_count(row['tweet'])) data_1['n_words'] = n_words print(data_1[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by iterrows :', (end_time-start_time),'seconds') # 使用向量化方法计算词的个数 print('\n\nUsing Function Vectorization\n\n') start_time = time.time() data_2 = data.copy() # 向量化函数 vec_word_count = np.vectorize(word_count) n_words_2 = vec_word_count(data_2['tweet']) data_2['n_words'] = n_words_2 print(data_2[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by numpy array : ', (end_time-start_time),'seconds')难以置信吧?对于上面的示例,向量化速度提高了80倍!这不仅有助于加速我们的代码,而且使其变得更整洁。
4. Python中的多进程
多进程是系统同时支持多个处理器的能力。
在这里,我们将流程分成多个任务,并且所有任务都独立运行。当我们处理大型数据集时,即使apply函数看起来也很慢。
因此,让我们看看如何利用Python中的多进程库加快处理速度。
我们将随机创建一百万个值,并求出每个值的除数。我们将使用apply函数和多进程方法比较其性能:
# 导入库 import pandas as pd import math import multiprocessing as mp from random import randint # 计算除数的函数 def countDivisors(n) : count = 0 for i in range(1, (int)(math.sqrt(n)) + 1) : if (n % i == 0) : %%time pool = mp.Pool(processes = (mp.cpu_count() - 1)) answer = pool.map(countDivisors,random_data) pool.close() pool.join() if (n / i == i) : count = count + 1 else : count = count + 2 return count # 创建随机数 random_data = [randint(10,1000) for i in range(1,1000001)] data = pd.DataFrame({'Number' : random_data }) data.shape
%%time data['Number_of_divisor'] = data.Number.apply(countDivisors)

%%time pool = mp.Pool(processes = (mp.cpu_count() - 1)) answer = pool.map(countDivisors,random_data) pool.close() pool.join()

关于如何优化Python代码问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





