这篇文章主要为大家展示了“怎么让Hadoop运行得更快一些”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“怎么让Hadoop运行得更快一些”这篇文章吧。
Hadoop是用以下的方式来解决速度问题:
1 使用分布式文件系统:这使得负载分摊,并壮大系统
2 优化写入速度:为了获得更快的写入速度,Hadoop架构是设计成先写入记录,然后在进行处理
3 使用批处理(Map/Reduce)来平衡数据传送速度和处理速度。
批处理所带来的挑战
批量处理的挑战在于,数据必须要间断性地进入才能保证流程正常运作,而如果数据源连续地输入,就会造成系统崩溃。
如果我们增加批处理窗口的话,结果就会增加数据处理过程的时间,使得相关的数据分析报告也要推迟落入我们的手中。在许多系统里,他们会选择在非高峰时间进行数据批处理,而这个时间是非常有限的。随着数据的体积不断胀大,处理数据的时间就不断增加,这样发展下去的话,需要被处理的数据就会不断积压。这最终的结果有可能一天都处理不完数据。
通过流处理来提升速度
流处理的概念是非常简单的。我们并不需要等到所有数据记录完后才进行处理,我们可以边记录边处理。
拿生产线来做比喻,我们可以等到所有的组件齐全后才开始装配汽车,也可以在生产厂那边把组件包装好,然后再送到特定的生产线,并马上组装起来。不用说,你也知道哪个速度会更快一点吧。
数据处理就跟生产线一样,而流处理进程就是把数据包装起来,并送到特定的“生产线”上。而在传统行业上,即使生产商把所有的部件都预装起来,我们依然需要一条生产线来组装。同样,流处理并不是要取代Hadoop,它只是用于减少系统大量工作,从而提升系统的处理速度。
Curt Monash在他的“传统数据库最终会在RAM中终结”的研究中指出的,内存间的流处理能够打造出更好的流处理系统。下面就是一个实时大数据的分析案例,并用Twitter来演示数据的相应处理方式。
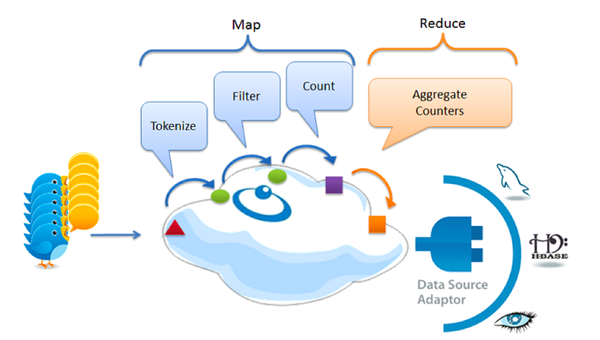
Google更快的处理方案:用流处理来替代Map/Reduce
由于当时缺乏可替方案,即使Map/Reduce性能不佳,许多大数据系统依然要使用这个技术。一个***的应用例子就是使用这项技术来维护全球的搜索索引。现在Google在索引处理方面大大减少使用Map/Reduce,反而加入了实时处理模式,这使得索引速度缩短为原来的一百分之一。
在网络中,一些类型的数据在不断膨胀。这也是HBase为什么计入触发式处理的原因,而Twitter未来将要处理更庞大的流数据。
以上是“怎么让Hadoop运行得更快一些”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





