本篇内容介绍了“in, not in , exists , not exists它们有什么区别”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
用法讲解
为了方便,我们创建两张表 t1 和 t2 。并分别加入一些数据。(id为主键,name为普通索引)
-- t1 DROP TABLE IF EXISTS `t1`; CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `address` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_t1_name` (`name`(191)) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1009 DEFAULT CHARSET=utf8mb4; INSERT INTO `t1` VALUES ('1001', '张三', '北京'), ('1002', '李四', '天津'), ('1003', '王五', '北京'), ('1004', '赵六', '河北'), ('1005', '杰克', '河南'), ('1006', '汤姆', '河南'), ('1007', '贝尔', '上海'), ('1008', '孙琪', '北京'); -- t2 DROP TABLE IF EXISTS `t2`; CREATE TABLE `t2` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL, `address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `idx_t2_name`(`name`(191)) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1014 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; INSERT INTO `t2` VALUES (1001, '张三', '北京'); INSERT INTO `t2` VALUES (1004, '赵六', '河北'); INSERT INTO `t2` VALUES (1005, '杰克', '河南'); INSERT INTO `t2` VALUES (1007, '贝尔', '上海'); INSERT INTO `t2` VALUES (1008, '孙琪', '北京'); INSERT INTO `t2` VALUES (1009, '曹操', '魏国'); INSERT INTO `t2` VALUES (1010, '刘备', '蜀国'); INSERT INTO `t2` VALUES (1011, '孙权', '吴国'); INSERT INTO `t2` VALUES (1012, '诸葛亮', '蜀国'); INSERT INTO `t2` VALUES (1013, '典韦', '魏国');
那么,对于当前的问题,就很简单了,用 not in 或者 not exists 都可以把 t1 表中比 t2 表多出的那部分数据给挑出来。(当然,t2 比 t1 多出来的那部分不算)
这里假设用 name 来匹配数据。
select * from t1 where name not in (select name from t2); 或者用 select * from t1 where not exists (select name from t2 where t1.name=t2.name);
得到的结果都是一样的。

但是,需要注意的是,not in 和 not exists 还是有不同点的。
在使用 not in 的时候,需要保证子查询的匹配字段是非空的。如,此表 t2 中的 name 需要有非空限制。如若不然,就会导致 not in 返回的整个结果集为空。
例如,我在 t2 表中加入一条 name 为空的数据。
INSERT INTO `t2` VALUES (1014, NULL, '魏国');
则此时,not in 结果就会返回空。

另外需要明白的是, exists 返回的结果是一个 boolean 值 true 或者 false ,而不是某个结果集。因为它不关心返回的具体数据是什么,只是外层查询需要拿这个布尔值做判断。
区别是,用 exists 时,若子查询查到了数据,则返回真。用 not exists 时,若子查询没有查到数据,则返回真。
由于 exists 子查询不关心具体返回的数据是什么。因此,以上的语句完全可以修改为如下,
-- 子查询中 name 可以修改为其他任意的字段,如此处改为 1 。 select * from t1 where not exists (select 1 from t2 where t1.name=t2.name);
从执行效率来说,1 > column > * 。因此推荐用 select 1。(准确的说应该是常量值)
in, exists 执行流程
1、 对于 in 查询来说,会先执行子查询,如上边的 t2 表,然后把查询得到的结果和外表 t1 做笛卡尔积,再通过条件进行筛选(这里的条件就是指 name 是否相等),把每个符合条件的数据都加入到结果集中。
sql 如下,
select * from t1 where name in (select name from t2);
伪代码如下:
for(x in A){ for(y in B){ if(condition is true) {result.add();} } }这里的 condition 其实就是对比两张表中的 name 是否相同。
2、对于 exists 来说,是先查询遍历外表 t1 ,然后每次遍历时,再检查在内表是否符合匹配条件,即检查是否存在 name 相等的数据。
sql 如下,
select * from t1 where name exists (select 1 from t2);
伪代码如下:
for(x in A){ if(exists condition is true){result.add();} }对应于此例,就是从 id 为 1001 开始遍历 t1 表 ,然后遍历时检查 t2 中是否有相等的 name 。
如 id=1001时,张三存在于 t2 表中,则返回 true,把 t1 中张三的这条记录加入到结果集,继续下次循环。id=1002 时,李四不在 t2 表中,则返回 false,不做任何操作,继续下次循环。直到遍历完整个 t1 表。
是否走索引?
针对网上说的 in 和 exists 不走索引,那么究竟是否如此呢?
我们在 MySQL 5.7.18 中验证一下。(注意版本号哦)
单表查询
首先,验证单表的最简单的情况。我们就以 t1 表为例,id为主键, name 为普通索引。
分别执行以下语句,
explain select * from t1 where id in (1001,1002,1003,1004); explain select * from t1 where id in (1001,1002,1003,1004,1005); explain select * from t1 where name in ('张三','李四'); explain select * from t1 where name in ('张三','李四','王五');为什么我要分别查不同的 id 个数呢?看截图,


会惊奇的发现,当 id 是四个值时,还走主键索引。而当 id 是五个值时,就不走索引了。这就很耐人寻味了。
再看 name 的情况,
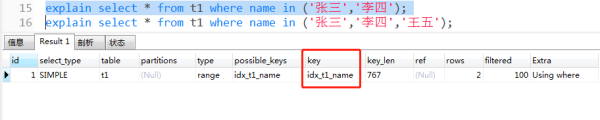

同样的当值多了之后,就不走索引了。
所以,我猜测这个跟匹配字段的长度有关。按照汉字是三个字节来计算,且程序设计中喜欢用2的n次幂的尿性,这里大概就是以 16 个字节为分界点。
然而,我又以同样的数据,去我的服务器上查询(版本号 5.7.22),发现四个id值时,就不走索引了。因此,估算这里的临界值为 12 个字节。
不管怎样,这说明了,在 MySQL 中应该对 in 查询的字节长度是有限制的。(没有官方确切说法,所以,仅供参考)
多表涉及子查询
我们主要是去看当前的这个例子中的两表查询时, in 和 exists 是否走索引。
一、分别执行以下语句,主键索引(id)和普通索引(name),在 in , not in 下是否走索引。
explain select * from t1 where id in (select id from t2); --1 explain select * from t1 where name in (select name from t2); --2 explain select * from t1 where id not in (select id from t2); --3 explain select * from t1 where name not in (select name from t2); --4
结果截图如下,
1、t1 走索引,t2 走索引。

1
2、t1 不走索引,t2不走索引。(此种情况,实测若把name改为唯一索引,则t1也会走索引)

2
3、t1 不走索引,t2走索引。

3
4、t1不走索引,t2不走索引。

4
我滴天,这结果看起来乱七八糟的,好像走不走索引,完全看心情。
但是,我们发现只有第一种情况,即用主键索引字段匹配,且用 in 的情况下,两张表才都走索引。
这个到底是不是规律呢?有待考察,且往下看。
二、接下来测试,主键索引和普通索引在 exists 和 not exists 下的情况。sql如下,
explain select * from t1 where exists (select 1 from t2 where t1.id=t2.id); explain select * from t1 where exists (select 1 from t2 where t1.name=t2.name); explain select * from t1 where not exists (select 1 from t2 where t1.id=t2.id); explain select * from t1 where not exists (select 1 from t2 where t1.name=t2.name);
这个结果就非常有规律了,且看,




有没有发现, t1 表哪种情况都不会走索引,而 t2 表是有索引的情况下就会走索引。为什么会出现这种情况?
其实,上一小节说到了 exists 的执行流程,就已经说明问题了。
它是以外层表为驱动表,无论如何都会循环遍历的,所以会全表扫描。而内层表通过走索引,可以快速判断当前记录是否匹配。
效率如何?
针对网上说的 exists 一定比 in 的执行效率高,我们做一个测试。
分别在 t1,t2 中插入 100W,200W 条数据。
我这里,用的是自定义函数来循环插入,语句参考如下,(没有把表名抽离成变量,因为我没有找到方法,尴尬)
-- 传入需要插入数据的id开始值和数据量大小,函数返回结果为最终插入的条数,此值正常应该等于数据量大小。 -- id自增,循环往 t1 表添加数据。这里为了方便,id、name取同一个变量,address就为北京。 delimiter // drop function if exists insert_datas1// create function insert_datas1(in_start int(11),in_len int(11)) returns int(11) begin declare cur_len int(11) default 0; declare cur_id int(11); set cur_id = in_start; while cur_len < in_len do insert into t1 values(cur_id,cur_id,'北京'); set cur_len = cur_len + 1; set cur_id = cur_id + 1; end while; return cur_len; end // delimiter ; -- 同样的,往 t2 表插入数据 delimiter // drop function if exists insert_datas2// create function insert_datas2(in_start int(11),in_len int(11)) returns int(11) begin declare cur_len int(11) default 0; declare cur_id int(11); set cur_id = in_start; while cur_len < in_len do insert into t2 values(cur_id,cur_id,'北京'); set cur_len = cur_len + 1; set cur_id = cur_id + 1; end while; return cur_len; end // delimiter ;
在此之前,先清空表里的数据,然后执行函数,
select insert_datas1(1,1000000);
对 t2 做同样的处理,不过为了两张表数据有交叉,就从 70W 开始,然后插入 200W 数据。
select insert_datas2(700000,2000000);
在家里的电脑,实际执行时间,分别为 36s 和 74s。
不知为何,家里的电脑还没有在 Docker 虚拟机中跑的脚本快。。害,就这样凑合着用吧。
等我有了新欢钱,就把它换掉,哼哼。
同样的,把上边的执行计划都执行一遍,进行对比。我这里就不贴图了。
in 和 exists 孰快孰慢
为了方便,主要拿以下这两个 sql 来对比分析。
select * from t1 where id in (select id from t2); select * from t1 where exists (select 1 from t2 where t1.id=t2.id);
执行结果显示,两个 sql 分别执行 1.3s 和 3.4s 。
注意此时,t1 表数据量为 100W, t2 表数据量为 200W 。
按照网上对 in 和 exists 区别的通俗说法,
如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in;
对应于此处就是:
当 t1 为小表, t2 为大表时,应该用 exists ,这样效率高。
当 t1 为大表,t2 为小表时,应该用 in,这样效率较高。
而我用实际数据测试,就把第一种说法给推翻了。因为很明显,t1 是小表,但是 in 比 exists 的执行速度还快。
为了继续测验它这个观点,我把两个表的内表外表关系调换一下,让 t2 大表作为外表,来对比查询,
select * from t2 where id in (select id from t1); select * from t2 where exists (select 1 from t1 where t1.id=t2.id);
执行结果显示,两个 sql 分别执行 1.8s 和 10.0s 。
是不是很有意思。可以发现,
对于 in 来说,大表小表调换了内外层关系,执行时间并无太大区别。一个是 1.3s,一个是 1.8s。
对于 exists 来说,大小表调换了内外层关系,执行时间天壤之别,一个是 3.4s ,一个是 10.0s,足足慢了两倍。
一、以查询优化器维度对比。
为了探究这个结果的原因。我去查看它们分别在查询优化器中优化后的 sql 。
-- 此为 5.7 写法,如果是 5.6版本,需要用 explain extended ... explain select * from t1 where id in (select id from t2); -- 本意为显示警告信息。但是和 explain 一块儿使用,就会显示出优化后的sql。需要注意使用顺序。 show warnings;
-- 此为 5.7 写法,如果是 5.6版本,需要用 explain extended ...explain select * from t1 where id in (select id from t2);-- 本意为显示警告信息。但是和 explain 一块儿使用,就会显示出优化后的sql。需要注意使用顺序。show warnings;
在结果 Message 里边就会显示我们要的语句。
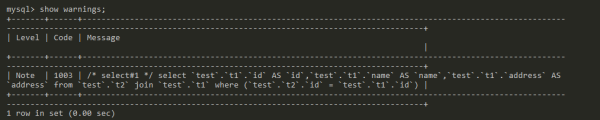
-- message 优化后的sql select `test`.`t1`.`id` AS `id`,`test`.`t1`.`name` AS `name`,`test`.`t1`.`address` AS `address` from `test`.`t2` join `test`.`t1` where (`test`.`t2`.`id` = `test`.`t1`.`id`)
可以发现,这里它把 in 转换为了 join 来执行。
这里没有用 on,而用了 where,是因为当只有 join 时,后边的 on 可以用 where 来代替。即 join on 等价于 join where 。
PS: 这里我们也可以发现,select * 最终会被转化为具体的字段,知道为什么我们不建议用 select * 了吧。
同样的,以 t2 大表为外表的查询情况,也查看优化后的语句。
explain select * from t2 where id in (select id from t1); show warnings;
我们会发现,它也会转化为 join 的。
select `test`.`t2`.`id` AS `id`,`test`.`t2`.`name` AS `name`,`test`.`t2`.`address` AS `address` from `test`.`t1` join `test`.`t2` where (`test`.`t2`.`id` = `test`.`t1`.`id`)
这里不再贴 exists 的转化 sql ,其实它没有什么大的变化。
二、以执行计划维度对比。
我们再以执行计划维度来对比他们的区别。
explain select * from t1 where id in (select id from t2); explain select * from t2 where id in (select id from t1); explain select * from t1 where exists (select 1 from t2 where t1.id=t2.id); explain select * from t2 where exists (select 1 from t1 where t1.id=t2.id);
执行结果分别为,

1

2

3

4
可以发现,对于 in 来说,大表 t2 做外表还是内表,都会走索引的,小表 t1 做内表时也会走索引。看它们的 rows 一列也可以看出来,前两张图结果一样。
对于 exists 来说,当小表 t1 做外表时,t1 全表扫描,rows 近 100W;当 大表 t2 做外表时, t2 全表扫描,rows 近 200W 。这也是为什么 t2 做外表时,执行效率非常低的原因。
因为对于 exists 来说,外表总会执行全表扫描的,当然表数据越少越好了。
最终结论: 外层大表内层小表,用in。外层小表内层大表,in和exists效率差不多(甚至 in 比 exists 还快,而并不是网上说的 exists 比 in 效率高)。
not in 和 not exists 孰快孰慢
此外,实测对比 not in 和 not exists 。
explain select * from t1 where id not in (select id from t2); explain select * from t1 where not exists (select 1 from t2 where t1.id=t2.id); explain select * from t1 where name not in (select name from t2); explain select * from t1 where not exists (select 1 from t2 where t1.name=t2.name); explain select * from t2 where id not in (select id from t1); explain select * from t2 where not exists (select 1 from t1 where t1.id=t2.id); explain select * from t2 where name not in (select name from t1); explain select * from t2 where not exists (select 1 from t1 where t1.name=t2.name);
小表做外表的情况下。对于主键来说, not exists 比 not in 快。对于普通索引来说, not in 和 not exists 差不了多少,甚至 not in 会稍快。
大表做外表的情况下,对于主键来说, not in 比 not exists 快。对于普通索引来说, not in 和 not exists 差不了多少,甚至 not in 会稍快。
感兴趣的同学,可自行尝试。以上边的两个维度(查询优化器和执行计划)分别来对比一下。
join 的嵌套循环 (Nested-Loop Join)
为了理解为什么这里的 in 会转换为 join ,我感觉有必要了解一下 join 的三种嵌套循环连接。
1、简单嵌套循环连接,Simple Nested-Loop Join ,简称 SNLJ
join 即是 inner join ,内连接,它是一个笛卡尔积,即利用双层循环遍历两张表。
我们知道,一般在 sql 中都会以小表作为驱动表。所以,对于 A,B 两张表,若A的结果集较少,则把它放在外层循环,作为驱动表。自然,B 就在内层循环,作为被驱动表。
简单嵌套循环,就是最简单的一种情况,没有做任何优化。
因此,复杂度也是最高的,O(mn)。伪代码如下,
for(id1 in A){ for(id2 in B){ if(id1==id2){ result.add(); } } }2、索引嵌套循环连接,Index Nested-Loop Join ,简称 INLJ
看名字也能看出来了,这是通过索引进行匹配的。外层表直接和内层表的索引进行匹配,这样就不需要遍历整个内层表了。利用索引,减少了外层表和内层表的匹配次数。
所以,此种情况要求内层表的列要有索引。
伪代码如下,
for(id1 in A){ if(id1 matched B.id){ result.add(); } }3、块索引嵌套连接,Block Nested-Loop Join ,简称 BNLJ
块索引嵌套连接,是通过缓存外层表的数据到 join buffer 中,然后 buffer 中的数据批量和内层表数据进行匹配,从而减少内层循环的次数。
以外层循环100次为例,正常情况下需要在内层循环读取外层数据100次。如果以每10条数据存入缓存buffer中,并传递给内层循环,则内层循环只需要读取10次(100/10)就可以了。这样就降低了内层循环的读取次数。
所以,这里转化为 join,可以用到索引嵌套循环连接,从而提高了执行效率。
“in, not in , exists , not exists它们有什么区别”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





