PyTorchйӣ¶еҹәзЎҖе…Ҙй—Ёд№Ӣжңүе“Әдәӣжһ„е»әжЁЎеһӢеҹәзЎҖ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPyTorchйӣ¶еҹәзЎҖе…Ҙй—Ёд№Ӣжңүе“Әдәӣжһ„е»әжЁЎеһӢеҹәзЎҖвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
дёҖгҖҒзҘһз»ҸзҪ‘з»ңзҡ„жһ„йҖ
PyTorchдёӯзҘһз»ҸзҪ‘з»ңжһ„йҖ дёҖиҲ¬жҳҜеҹәдәҺ Module зұ»зҡ„жЁЎеһӢжқҘе®ҢжҲҗзҡ„пјҢе®ғи®©жЁЎеһӢжһ„йҖ пӨҒеҠ зҒөжҙ»гҖӮModule зұ»жҳҜ nn жЁЎеқ—里жҸҗдҫӣзҡ„дёҖдёӘжЁЎеһӢжһ„йҖ зұ»пјҢжҳҜжүҖжңүзҘһз»ҸзҪ‘з»ңжЁЎеқ—зҡ„еҹәзұ»пјҢжҲ‘们еҸҜд»Ҙ继жүҝе®ғжқҘе®ҡд№үжҲ‘们жғіиҰҒзҡ„жЁЎеһӢгҖӮ
дёӢйқўз»§жүҝ Module зұ»жһ„йҖ еӨҡеұӮж„ҹзҹҘжңәгҖӮиҝҷ里е®ҡд№үзҡ„ MLP зұ»йҮҚиҪҪпҰә Module зұ»зҡ„ init еҮҪж•°е’Ң forward еҮҪж•°гҖӮе®ғ们еҲҶеҲ«з”ЁдәҺеҲӣе»әжЁЎеһӢеҸӮж•°е’Ңе®ҡд№үеүҚеҗ‘и®Ўз®—гҖӮеүҚеҗ‘и®Ўз®—д№ҹеҚіжӯЈеҗ‘дј ж’ӯгҖӮ
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 09:43:21 2021
@author: 86493
"""
import torch
from torch import nn
class MLP(nn.Module):
# еЈ°жҳҺеёҰжңүжЁЎеһӢеҸӮж•°зҡ„еұӮпјҢжӯӨеӨ„еЈ°жҳҺдәҶ2дёӘе…ЁиҝһжҺҘеұӮ
def __init__(self, **kwargs):
# и°ғз”ЁMLPзҲ¶зұ»Blockзҡ„жһ„йҖ еҮҪж•°жқҘиҝӣиЎҢеҝ…иҰҒзҡ„еҲқе§ӢеҢ–
# иҝҷж ·еңЁжһ„йҖ е®һдҫӢж—¶иҝҳеҸҜд»ҘжҢҮе®ҡе…¶д»–еҮҪж•°
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256, 10)
# е®ҡд№үжЁЎеһӢзҡ„еүҚеҗ‘и®Ўз®—
# еҚіеҰӮдҪ•ж №жҚ®иҫ“е…Ҙxи®Ўз®—иҝ”еӣһжүҖйңҖиҰҒзҡ„жЁЎеһӢиҫ“еҮә
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
X = torch.rand(2, 784)
net = MLP()
print(net)
print('-' * 60)
print(net(X))з»“жһңдёәпјҡ
MLP(
(hidden): Linear(in_features=784, out_features=256, bias=True)
(act): ReLU()
(output): Linear(in_features=256, out_features=10, bias=True)
)
------------------------------------------------------------
tensor([[ 0.1836, 0.1946, 0.0924, -0.1163, -0.2914, -0.1103, -0.0839, -0.1274,
0.1618, -0.0601],
[ 0.0738, 0.2369, 0.0225, -0.1514, -0.3787, -0.0551, -0.0836, -0.0496,
0.1481, 0.0139]], grad_fn=<AddmmBackward>)
жіЁж„Ҹпјҡ
пјҲ1пјүдёҠйқўзҡ„MLPзұ»дёҚйңҖиҰҒе®ҡд№үеҸҚеҗ‘дј ж’ӯеҮҪж•°пјҢзі»з»ҹе°ҶйҖҡиҝҮиҮӘеҠЁжұӮжўҜеәҰиҖҢиҮӘеҠЁз”ҹжҲҗеҸҚеҗ‘дј ж’ӯжүҖйңҖзҡ„backwardеҮҪж•°гҖӮ
пјҲ2пјүе°Ҷж•°жҚ®Xдј е…Ҙе®һдҫӢеҢ–MLPзұ»еҗҺеҫ—еҲ°зҡ„netеҜ№иұЎпјҢдјҡеҒҡдёҖж¬ЎеүҚеҗ‘и®Ўз®—пјҢ并且net(X)дјҡи°ғз”ЁMLPзұ»з»§жүҝиҮӘзҲ¶зұ»Moduleзҡ„callеҮҪж•°вҖ”вҖ”иҜҘеҮҪж•°и°ғз”ЁжҲ‘们е®ҡд№үзҡ„еӯҗзұ»MLPзҡ„forwardеҮҪж•°е®ҢжҲҗеүҚеҗ‘дј ж’ӯи®Ўз®—гҖӮ
пјҲ3пјүиҝҷйҮҢжІЎе°ҶModuleзұ»е‘ҪеҗҚдёәLayerпјҲеұӮпјүжҲ–иҖ…ModelпјҲжЁЎеһӢпјүзӯүпјҢжҳҜеӣ дёәиҜҘзұ»жҳҜдёҖдёӘеҸҜдҫӣиҮӘз”ұз»„е»әзҡ„йғЁд»¶пјҢ е®ғзҡ„еӯҗзұ»ж—ўеҸҜд»ҘжҳҜдёҖдёӘеұӮпјҲеҰӮ继жүҝзҲ¶зұ»nnзҡ„еӯҗзұ»зәҝжҖ§еұӮLinearпјүпјҢд№ҹеҸҜд»ҘжҳҜдёҖдёӘжЁЎеһӢпјҲеҰӮжӯӨеӨ„зҡ„еӯҗзұ»MLPпјүпјҢд№ҹеҸҜд»ҘжҳҜжЁЎеһӢзҡ„дёҖйғЁеҲҶгҖӮ
дәҢгҖҒзҘһз»ҸзҪ‘з»ңдёӯеёёи§Ғзҡ„еұӮ
жңүе…ЁиҝһжҺҘеұӮгҖҒеҚ·з§ҜеұӮгҖҒжұ еҢ–еұӮдёҺеҫӘзҺҜеұӮзӯүпјҢдёӢйқўеӯҰд№ дҪҝз”ЁModuleе®ҡд№үеұӮгҖӮ
2.1 дёҚеҗ«жЁЎеһӢеҸӮж•°зҡ„еұӮ
дёӢйқўжһ„йҖ зҡ„ MyLayer зұ»йҖҡиҝҮ继жүҝ Module зұ»иҮӘе®ҡд№үпҰәдёҖдёӘе°Ҷиҫ“е…ҘеҮҸжҺүеқҮеҖјеҗҺиҫ“еҮәзҡ„еұӮпјҢ并е°ҶеұӮзҡ„и®Ўз®—е®ҡд№үеңЁпҰә forward еҮҪ数里гҖӮиҝҷдёӘеұӮ里пҘ§еҗ«жЁЎеһӢеҸӮж•°гҖӮ
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 10:19:59 2021
@author: 86493
"""
import torch
from torch import nn
class MyLayer(nn.Module):
def __init__(self, **kwargs):
# и°ғз”ЁзҲ¶зұ»зҡ„ж–№жі•
super(MyLayer, self).__init__(**kwargs)
def forward(self, x):
return x - x.mean()
# жөӢиҜ•пјҢе®һдҫӢеҢ–иҜҘеұӮпјҢеҒҡеүҚеҗ‘и®Ўз®—
layer = MyLayer()
layer1 = layer(torch.tensor([1, 2, 3, 4, 5],
dtype = torch.float))
print(layer1)
з»“жһңдёәпјҡ
tensor([-2., -1., 0., 1., 2.])
2.2 еҗ«жЁЎеһӢеҸӮж•°зҡ„еұӮ
еҸҜд»ҘиҮӘе®ҡд№үеҗ«жЁЎеһӢеҸӮж•°зҡ„иҮӘе®ҡд№үеұӮгҖӮе…¶дёӯзҡ„жЁЎеһӢеҸӮж•°еҸҜд»ҘйҖҡиҝҮи®ӯз»ғеӯҰеҮәгҖӮ
Parameter зұ»е…¶е®һжҳҜ Tensor зҡ„еӯҗзұ»пјҢеҰӮжһңдёҖдёӘ Tensor жҳҜ Parameter пјҢйӮЈд№Ҳе®ғдјҡиҮӘеҠЁиў«ж·»еҠ еҲ°жЁЎеһӢзҡ„еҸӮж•°пҰң表里гҖӮжүҖд»ҘеңЁиҮӘе®ҡд№үеҗ«жЁЎеһӢеҸӮж•°зҡ„еұӮж—¶пјҢжҲ‘们еә”иҜҘе°ҶеҸӮж•°е®ҡд№үжҲҗ Parameter пјҢйҷӨдәҶзӣҙжҺҘе®ҡд№үжҲҗ Parameter зұ»еӨ–пјҢиҝҳеҸҜд»ҘдҪҝз”Ё ParameterList е’Ң ParameterDict еҲҶеҲ«е®ҡд№үеҸӮж•°зҡ„пҰңиЎЁе’Ңеӯ—е…ёгҖӮ
PSпјҡдёӢйқўеҮәзҺ°torch.mmжҳҜе°ҶдёӨдёӘзҹ©йҳөзӣёд№ҳпјҢеҰӮ
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 10:56:03 2021
@author: 86493
"""
import torch
a = torch.randn(2, 3)
b = torch.randn(3, 2)
print(torch.mm(a, b))
# ж•ҲжһңзӣёеҗҢ
print(torch.matmul(a, b))
#tensor([[1.8368, 0.4065],
# [2.7972, 2.3096]])
#tensor([[1.8368, 0.4065],
# [2.7972, 2.3096]])
пјҲ1пјүд»Јз Ғж —еӯҗ1
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 10:33:04 2021
@author: 86493
"""
import torch
from torch import nn
class MyListDense(nn.Module):
def __init__(self):
super(MyListDense, self).__init__()
# 3дёӘrandnзҡ„ж„ҸжҖқ
self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4, 1)))
def forward(self, x):
for i in range(len(self.params)):
# mmжҳҜжҢҮзҹ©йҳөзӣёд№ҳ
x = torch.mm(x, self.params[i])
return x
net = MyListDense()
print(net)
жү“еҚ°еҫ—пјҡ
MyListDense(
(params): ParameterList(
(0): Parameter containing: [torch.FloatTensor of size 4x4]
(1): Parameter containing: [torch.FloatTensor of size 4x4]
(2): Parameter containing: [torch.FloatTensor of size 4x4]
(3): Parameter containing: [torch.FloatTensor of size 4x1]
)
)
пјҲ2пјүд»Јз Ғж —еӯҗ2
иҝҷеӣһз”ЁеҸҳйҮҸеӯ—е…ёпјҡ
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 11:03:29 2021
@author: 86493
"""
import torch
from torch import nn
class MyDictDense(nn.Module):
def __init__(self):
super(MyDictDense, self).__init__()
self.params = nn.ParameterDict({
'linear1': nn.Parameter(torch.randn(4, 4)),
'linear2': nn.Parameter(torch.randn(4, 1))
})
# ж–°еўһ
self.params.update({'linear3':
nn.Parameter(torch.randn(4, 2))})
def forward(self, x, choice = 'linear1'):
return torch.mm(x, self.params[choice])
net = MyDictDense()
print(net)жү“еҚ°еҫ—пјҡ
MyDictDense(
(params): ParameterDict(
(linear1): Parameter containing: [torch.FloatTensor of size 4x4]
(linear2): Parameter containing: [torch.FloatTensor of size 4x1]
(linear3): Parameter containing: [torch.FloatTensor of size 4x2]
)
)
2.3 дәҢз»ҙеҚ·з§ҜеұӮ
дәҢз»ҙеҚ·з§ҜеұӮе°Ҷиҫ“е…Ҙе’ҢеҚ·з§Ҝж ёеҒҡдә’зӣёе…іиҝҗз®—пјҢ并еҠ дёҠдёҖдёӘж ҮпҘҫеҒҸе·®жқҘеҫ—еҲ°иҫ“еҮәгҖӮеҚ·з§ҜеұӮзҡ„жЁЎеһӢеҸӮж•°еҢ…жӢ¬пҰәеҚ·з§Ҝж ёе’Ңж ҮпҘҫеҒҸе·®гҖӮеңЁи®ӯз»ғжЁЎеһӢзҡ„ж—¶еҖҷпјҢйҖҡеёёжҲ‘们е…ҲеҜ№еҚ·з§Ҝж ёйҡҸжңәеҲқе§ӢеҢ–пјҢ然еҗҺдёҚж–ӯиҝӯд»ЈеҚ·з§Ҝж ёе’ҢеҒҸе·®гҖӮ
еҚ·з§ҜзӘ—еҸЈеҪўзҠ¶дёә p Г— q p \times q pГ—q зҡ„еҚ·з§ҜеұӮз§°дёә p Г— q p \times q pГ—q еҚ·з§ҜеұӮгҖӮеҗҢж ·пјҢ p Г— q p \times q pГ—q еҚ·з§ҜжҲ– p Г— q p \times q pГ—q еҚ·з§Ҝж ёиҜҙжҳҺеҚ·з§Ҝж ёзҡ„й«ҳе’Ңе®ҪеҲҶеҲ«дёә p p p е’Ң q q qгҖӮ
пјҲ1пјүеЎ«е……еҸҜд»ҘеўһеҠ иҫ“еҮәзҡ„й«ҳе’Ңе®ҪгҖӮиҝҷеёёз”ЁжқҘдҪҝиҫ“еҮәдёҺиҫ“е…Ҙе…·жңүзӣёеҗҢзҡ„й«ҳе’Ңе®ҪгҖӮ
пјҲ2пјүжӯҘе№…еҸҜд»ҘеҮҸе°Ҹиҫ“еҮәзҡ„й«ҳе’Ңе®ҪпјҢпҰөеҰӮиҫ“еҮәзҡ„й«ҳе’Ңе®Ҫд»…дёәиҫ“вјҠе…Ҙзҡ„й«ҳе’Ңе®Ҫзҡ„ ( дёәеӨ§дәҺ1зҡ„ж•ҙж•°)гҖӮ
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 11:20:57 2021
@author: 86493
"""
import torch
from torch import nn
# еҚ·з§Ҝиҝҗз®—(дәҢз»ҙдә’зӣёе…і)
def corr2d(X, K):
h, w = K.shape
X, K = X.float(), K.float()
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (x[i: i + h, j: j + w] * K).sum()
return Y
# дәҢз»ҙеҚ·з§ҜеұӮ
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
conv2d = nn.Conv2d(in_channels = 1,
out_channels = 1,
kernel_size = 3,
padding = 1)
print(conv2d)
еҫ—пјҡ
Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
еЎ«е……(padding)жҳҜжҢҮеңЁиҫ“е…Ҙй«ҳе’Ңе®Ҫзҡ„дёӨдҫ§еЎ«е……е…ғзҙ (йҖҡеёёжҳҜ0е…ғзҙ )гҖӮ
дёӢдёӘж —еӯҗпјҡеҲӣе»әдёҖдёӘй«ҳе’Ңе®Ҫдёә3зҡ„дәҢз»ҙеҚ·з§ҜеұӮпјҢи®ҫиҫ“е…Ҙй«ҳе’Ңе®ҪдёӨдҫ§зҡ„еЎ«е……ж•°еҲҶеҲ«дёә1гҖӮз»ҷе®ҡдёҖй«ҳе’Ңе®ҪйғҪдёә8зҡ„inputпјҢиҫ“еҮәзҡ„й«ҳе’Ңе®Ҫдјҡд№ҹжҳҜ8гҖӮ
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 11:54:29 2021
@author: 86493
"""
import torch
from torch import nn
# е®ҡд№үдёҖдёӘеҮҪж•°и®Ўз®—еҚ·з§ҜеұӮ
# еҜ№иҫ“е…Ҙе’Ңиҫ“еҮәе·ҰеҜ№еә”зҡ„еҚҮз»ҙе’ҢйҷҚз»ҙ
def comp_conv2d(conv2d, X):
# (1, 1)д»ЈиЎЁжү№йҮҸеӨ§е°Ҹе’ҢйҖҡйҒ“ж•°
X = X.view((1, 1) + X.shape)
Y = conv2d(X)
# жҺ’йҷӨдёҚе…іеҝғзҡ„еүҚ2з»ҙпјҡжү№йҮҸе’ҢйҖҡйҒ“
return Y.view(Y.shape[2:])
# жіЁж„ҸиҝҷйҮҢжҳҜдёӨдҫ§еҲҶеҲ«еЎ«е……1иЎҢжҲ–еҲ—пјҢжүҖд»ҘеңЁдёӨдҫ§е…ұеЎ«е……2иЎҢжҲ–еҲ—
conv2d = nn.Conv2d(in_channels = 1,
out_channels = 1,
kernel_size = 3,
padding = 1)
X = torch.rand(8, 8)
endshape = comp_conv2d(conv2d, X).shape
print(endshape)
# дҪҝз”Ёй«ҳдёә5пјҢе®Ҫдёә3зҡ„еҚ·з§Ҝж ёпјҢеңЁй«ҳе’Ңе®ҪдёӨдҫ§еЎ«е……ж•°дёә2е’Ң1
conv2d = nn.Conv2d(in_channels = 1,
out_channels = 1,
kernel_size = (5, 3),
padding = (2, 1))
endshape2 = comp_conv2d(conv2d, X).shape
print(endshape2)
з»“жһңдёәпјҡ
torch.Size([8, 8])
torch.Size([8, 8])
stride
еңЁдәҢз»ҙдә’зӣёе…іиҝҗз®—дёӯпјҢеҚ·з§ҜзӘ—еҸЈд»Һиҫ“е…Ҙж•°з»„зҡ„жңҖе·ҰдёҠж–№ејҖе§ӢпјҢжҢүд»Һе·ҰеҫҖеҸігҖҒд»ҺдёҠеҫҖдёӢ зҡ„йЎәеәҸпјҢдҫқж¬ЎеңЁиҫ“вјҠж•°з»„дёҠж»‘еҠЁгҖӮжҲ‘们е°ҶжҜҸж¬Ўж»‘еҠЁзҡ„пЁҲж•°е’ҢпҰңж•°з§°дёәжӯҘе№…(stride)гҖӮ
# жӯҘе№…stride
conv2d = nn.Conv2d(in_channels = 1,
out_channels = 1,
kernel_size = (3, 5),
padding = (0, 1),
stride = (3, 4))
endshape3 = comp_conv2d(conv2d, X).shape
print(endshape3)
# torch.Size([2, 2])
2.4 жұ еҢ–еұӮ
жұ еҢ–еұӮжҜҸж¬ЎеҜ№иҫ“е…Ҙж•°жҚ®зҡ„дёҖдёӘеӣәе®ҡеҪўзҠ¶зӘ—еҸЈ(еҸҲз§°жұ еҢ–зӘ—еҸЈ)дёӯзҡ„е…ғзҙ и®Ўз®—иҫ“еҮәгҖӮпҘ§еҗҢдәҺеҚ·з§ҜеұӮ里计算иҫ“е…Ҙе’Ңж ёзҡ„дә’зӣёе…іжҖ§пјҢжұ еҢ–еұӮзӣҙжҺҘи®Ўз®—жұ еҢ–зӘ—еҸЈеҶ…е…ғзҙ зҡ„жңҖеӨ§еҖјжҲ–иҖ…е№іеқҮеҖјгҖӮиҜҘиҝҗз®—д№ҹ еҲҶеҲ«еҸ«еҒҡжңҖеӨ§жұ еҢ–жҲ–е№іеқҮжұ еҢ–гҖӮ
еңЁдәҢз»ҙжңҖеӨ§жұ еҢ–дёӯпјҢжұ еҢ–зӘ—еҸЈд»Һиҫ“е…Ҙж•°з»„зҡ„жңҖе·ҰдёҠж–№ејҖе§ӢпјҢжҢүд»Һе·ҰеҫҖеҸігҖҒд»ҺдёҠеҫҖдёӢзҡ„йЎәеәҸпјҢдҫқж¬ЎеңЁиҫ“е…Ҙж•°з»„дёҠж»‘еҠЁгҖӮеҪ“жұ еҢ–зӘ—еҸЈж»‘еҠЁеҲ°жҹҗвјҖдҪҚзҪ®ж—¶пјҢзӘ—еҸЈдёӯзҡ„иҫ“е…Ҙеӯҗж•°з»„зҡ„жңҖеӨ§еҖјеҚіиҫ“еҮәж•°з»„дёӯзӣёеә”дҪҚзҪ®зҡ„е…ғзҙ гҖӮ
дёӢйқўжҠҠжұ еҢ–еұӮзҡ„еүҚеҗ‘и®Ўз®—е®һзҺ°еңЁpool2dеҮҪж•°йҮҢгҖӮ
жңҖеӨ§жұ еҢ–пјҡ
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 18:49:27 2021
@author: 86493
"""
import torch
from torch import nn
def pool2d(x, pool_size, mode = 'max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.Tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
end = pool2d(X, (2, 2)) # й»ҳи®ӨжҳҜжңҖеӨ§жұ еҢ–
# end = pool2d(X, (2, 2), mode = 'avg')
print(end)
tensor([[4., 5.],
[7., 8.]])
е№іеқҮжұ еҢ–пјҡ
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 18:49:27 2021
@author: 86493
"""
import torch
from torch import nn
def pool2d(x, pool_size, mode = 'max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.FloatTensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
# end = pool2d(X, (2, 2)) # й»ҳи®ӨжҳҜжңҖеӨ§жұ еҢ–
end = pool2d(X, (2, 2), mode = 'avg')
print(end)
з»“жһңеҰӮдёӢпјҢжіЁж„ҸдёҠйқўеҰӮжһңmodeжҳҜavgжЁЎејҸпјҲе№іеқҮжұ еҢ–пјүж—¶пјҢдёҚиғҪеҶҷX = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]])пјҢеҗҰеҲҷдјҡжҠҘй”ҷCan only calculate the mean of floating types. Got Long instead.гҖӮжҠҠtensorж”№жҲҗTensorжҲ–FloatTensorеҗҺе°ұеҸҜд»ҘдәҶпјҲTensorжҳҜFloatTensorзҡ„зј©еҶҷпјүгҖӮ
tensor([[2., 3.],
[5., 6.]])
дёүгҖҒLeNetжЁЎеһӢж —еӯҗ
дёҖдёӘзҘһз»ҸзҪ‘з»ңзҡ„е…ёеһӢи®ӯз»ғиҝҮзЁӢеҰӮдёӢпјҡ
1 е®ҡд№үеҢ…еҗ«дёҖдәӣеҸҜеӯҰд№ еҸӮж•°(жҲ–иҖ…еҸ«жқғйҮҚпјүзҡ„зҘһз»ҸзҪ‘з»ң
2. еңЁиҫ“е…Ҙж•°жҚ®йӣҶдёҠиҝӯд»Ј
3. йҖҡиҝҮзҪ‘з»ңеӨ„зҗҶиҫ“е…Ҙ
4. и®Ўз®— loss (иҫ“еҮәе’ҢжӯЈзЎ®зӯ”жЎҲзҡ„и·қзҰ»пјү
5. е°ҶжўҜеәҰеҸҚеҗ‘дј ж’ӯз»ҷзҪ‘з»ңзҡ„еҸӮж•°
6. жӣҙж–°зҪ‘з»ңзҡ„жқғйҮҚпјҢдёҖиҲ¬дҪҝз”ЁдёҖдёӘз®ҖеҚ•зҡ„规еҲҷпјҡweight = weight - learning_rate * gradient

# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 19:21:19 2021
@author: 86493
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
# йңҖиҰҒжҠҠзҪ‘з»ңдёӯе…·жңүеҸҜеӯҰд№ еҸӮж•°зҡ„еұӮж”ҫеңЁжһ„йҖ еҮҪж•°__init__
def __init__(self):
super(LeNet, self).__init__()
# иҫ“е…ҘеӣҫеғҸchannelпјҡ1пјӣиҫ“еҮәchannelпјҡ6
# 5*5еҚ·з§Ҝж ё
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation:y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2 * 2 жңҖеӨ§жұ еҢ–
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# еҰӮжһңжҳҜж–№йҳөпјҢеҲҷеҸҜд»ҘеҸӘдҪҝз”ЁдёҖдёӘж•°еӯ—иҝӣиЎҢе®ҡд№ү
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# еҒҡдёҖж¬Ўflatten
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
# йҷӨеҺ»жү№еӨ„зҗҶз»ҙеәҰ,еҫ—еҲ°е…¶д»–жүҖжңүз»ҙеәҰ
size = x.size()[1:]
num_features = 1
# е°ҶеҲҡжүҚеҫ—еҲ°зҡ„з»ҙеәҰд№Ӣй—ҙзӣёд№ҳиө·жқҘ
for s in size:
num_features *= s
return num_features
net = LeNet()
print(net)
# дёҖдёӘжЁЎеһӢзҡ„еҸҜеӯҰд№ еҸӮж•°еҸҜд»ҘйҖҡиҝҮ`net.parameters()`иҝ”еӣһ
params = list(net.parameters())
print("paramsзҡ„len:", len(params))
# print("params:\n", params)
print(params[0].size()) # conv1зҡ„жқғйҮҚ
print('-' * 60)
# йҡҸжңәдёҖдёӘ32Г—32зҡ„input
input = torch.randn(1, 1, 32, 32)
out = net(input)
print("зҪ‘з»ңзҡ„outputдёәпјҡ", out)
print('-' * 60)
# йҡҸжңәжўҜеәҰзҡ„еҸҚеҗ‘дј ж’ӯ
net.zero_grad() # жё…йӣ¶жүҖжңүеҸӮж•°зҡ„жўҜеәҰзј“еӯҳ
end = out.backward(torch.randn(1, 10))
print(end) # Noneprintзҡ„з»“жһңдёәпјҡ
LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
paramsзҡ„len: 10
torch.Size([6, 1, 5, 5])
------------------------------------------------------------
зҪ‘з»ңзҡ„outputдёәпјҡ tensor([[ 0.0904, 0.0866, 0.0851, -0.0176, 0.0198, 0.0530, 0.0815, 0.0284,
-0.0216, -0.0425]], grad_fn=<AddmmBackward>)
------------------------------------------------------------
None
дёүзӮ№жҸҗйҶ’пјҡ
пјҲ1пјүеҸӘйңҖиҰҒе®ҡд№ү forward еҮҪж•°пјҢbackwardеҮҪж•°дјҡеңЁдҪҝз”Ёautogradж—¶иҮӘеҠЁе®ҡд№үпјҢbackwardеҮҪж•°з”ЁжқҘи®Ўз®—еҜјж•°гҖӮжҲ‘们еҸҜд»ҘеңЁ forward еҮҪж•°дёӯдҪҝз”Ёд»»дҪ•й’ҲеҜ№еј йҮҸзҡ„ж“ҚдҪңе’Ңи®Ўз®—гҖӮ
пјҲ2пјүеңЁbackwardеүҚжңҖеҘҪnet.zero_grad()пјҢеҚіжё…йӣ¶жүҖжңүеҸӮж•°зҡ„жўҜеәҰзј“еӯҳгҖӮ
пјҲ3пјүtorch.nnеҸӘж”ҜжҢҒе°Ҹжү№йҮҸеӨ„зҗҶ (mini-batchesпјүгҖӮж•ҙдёӘ torch.nn еҢ…еҸӘж”ҜжҢҒе°Ҹжү№йҮҸж ·жң¬зҡ„иҫ“е…ҘпјҢдёҚж”ҜжҢҒеҚ•дёӘж ·жң¬зҡ„иҫ“е…ҘгҖӮжҜ”еҰӮпјҢnn.Conv2d жҺҘеҸ—дёҖдёӘ4з»ҙзҡ„еј йҮҸпјҢеҚіnSamples x nChannels x Height x WidthеҰӮжһңжҳҜдёҖдёӘеҚ•зӢ¬зҡ„ж ·жң¬пјҢеҸӘйңҖиҰҒдҪҝз”Ёinput.unsqueeze(0) жқҘж·»еҠ дёҖдёӘвҖңеҒҮзҡ„вҖқжү№еӨ§е°Ҹз»ҙеәҰгҖӮ
torch.TensorпјҡдёҖдёӘеӨҡз»ҙж•°з»„пјҢж”ҜжҢҒиҜёеҰӮbackward()зӯүзҡ„иҮӘеҠЁжұӮеҜјж“ҚдҪңпјҢеҗҢж—¶д№ҹдҝқеӯҳдәҶеј йҮҸзҡ„жўҜеәҰгҖӮ
nn.ModuleпјҡзҘһз»ҸзҪ‘з»ңжЁЎеқ—гҖӮжҳҜдёҖз§Қж–№дҫҝе°ҒиЈ…еҸӮж•°зҡ„ж–№ејҸпјҢе…·жңүе°ҶеҸӮ数移еҠЁеҲ°GPUгҖҒеҜјеҮәгҖҒеҠ иҪҪзӯүеҠҹиғҪгҖӮ
nn.Parameterпјҡеј йҮҸзҡ„дёҖз§ҚпјҢеҪ“е®ғдҪңдёәдёҖдёӘеұһжҖ§еҲҶй…Қз»ҷдёҖдёӘModuleж—¶пјҢе®ғдјҡиў«иҮӘеҠЁжіЁеҶҢдёәдёҖдёӘеҸӮж•°гҖӮ
autograd.Functionпјҡе®һзҺ°дәҶиҮӘеҠЁжұӮеҜјеүҚеҗ‘е’ҢеҸҚеҗ‘дј ж’ӯзҡ„е®ҡд№үпјҢжҜҸдёӘTensorиҮіе°‘еҲӣе»әдёҖдёӘFunctionиҠӮзӮ№пјҢиҜҘиҠӮзӮ№иҝһжҺҘеҲ°еҲӣе»әTensorзҡ„еҮҪ数并еҜ№е…¶еҺҶеҸІиҝӣиЎҢзј–з ҒгҖӮ
еӣӣгҖҒAlexNetжЁЎеһӢж —еӯҗ
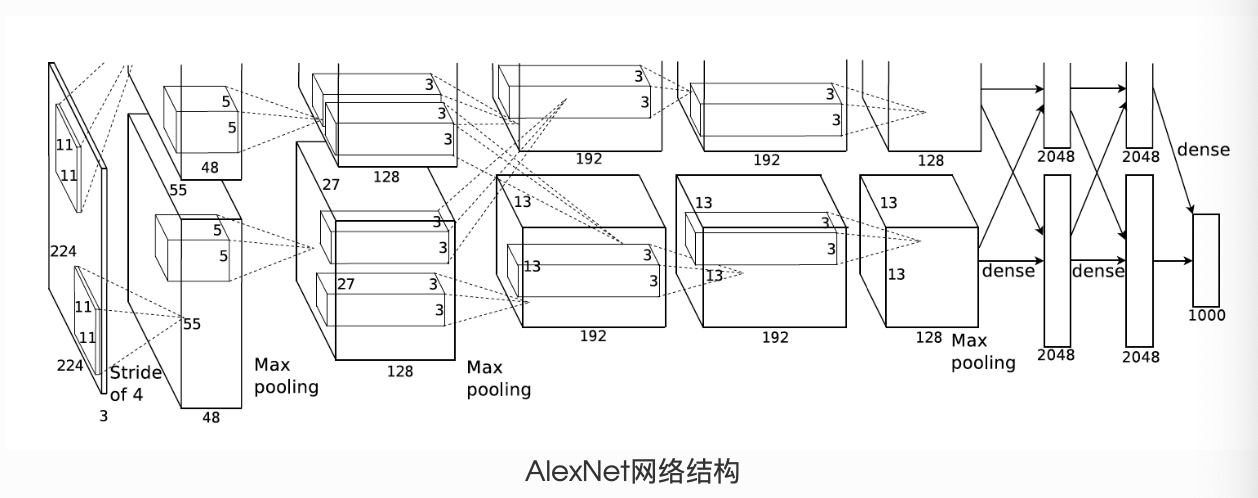
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 16 21:00:39 2021
@author: 86493
"""
import torch
from torch import nn
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
# in_channels,out_channels,kernel_size,stride,padding
nn.Conv2d(1, 96, 11, 4),
nn.ReLU(),
# kernel_size, stride
nn.MaxPool2d(3, 2),
# и§Ғ笑еҚ·з§ҜзӘ—еҸЈпјҢдҪҶдҪҝз”Ёpadding=2жқҘдҪҝиҫ“е…Ҙе’Ңиҫ“еҮәзҡ„й«ҳе®ҪзӣёеҗҢ
# дё”еўһеӨ§иҫ“еҮәйҖҡйҒ“ж•°
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# иҝһз»ӯ3дёӘеҚ·з§ҜеұӮпјҢдё”еҗҺйқўдҪҝз”Ёжӣҙе°Ҹзҡ„еҚ·з§ҜзӘ—еҸЈ
# йҷӨдәҶжңҖеҗҺзҡ„еҚ·з§ҜеұӮеӨ–пјҢиҝӣдёҖжӯҘеўһеӨ§дәҶиҫ“еҮә
# жіЁ:еүҚ2дёӘеҚ·з§ҜеұӮеҗҺдёҚдҪҝз”Ёжұ еҢ–еұӮжқҘеҮҸе°‘иҫ“е…Ҙзҡ„й«ҳе’Ңе®Ҫ
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 383, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# иҝҷйҮҢзҡ„е…ЁиҝһжҺҘеұӮзҡ„иҫ“еҮәдёӘж•°жҜ”LeNetдёӯзҡ„еӨ§ж•°еҖҚгҖӮ
# дҪҝз”ЁдёўејғеұӮжқҘзј“и§ЈиҝҮжӢҹеҗҲ
self.fc = nn.Sequential(
nn.Linear(256 *5 * 5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4086),
nn.ReLU(),
nn.Dropout(0.5),
# иҫ“еҮәеұӮпјҢдёӢж¬Ўдјҡз”ЁеҲ°Fash-MNISTпјҢжүҖд»ҘжӯӨеӨ„зұ»еҲ«и®ҫдёә10,
# иҖҢйқһи®әж–Үдёӯзҡ„1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
net = AlexNet()
print(net)
еҸҜд»ҘзңӢеҲ°иҜҘзҪ‘з»ңзҡ„з»“жһ„пјҡ
AlexNet(
(conv): Sequential(
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU()
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): Conv2d(384, 383, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU()
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=6400, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4086, bias=True)
(4): ReLU()
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
вҖңPyTorchйӣ¶еҹәзЎҖе…Ҙй—Ёд№Ӣжңүе“Әдәӣжһ„е»әжЁЎеһӢеҹәзЎҖвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





