我不知道有没有人这么玩过,也许有,也许没有。
时间和空间永远都在厚此薄彼,只因为设施不全,在资源匮乏的年代,只能取舍。但是如果资源丰盈,鱼
与熊掌,完全可以兼得!对于路由查找而言,紧凑的数据结构占用了很小的空间,难道它就要为此付出时间的代价吗?如果我们考虑MMU设施,就会发现,紧凑的
数据结构不但节省了空间,还提高了速度。
我们长期受到的教育就是取义一定要舍身这样的教育,如果不舍身,取到的不会是义,也可能会被讹诈,不怪自己被讹,只因自己没死。其实仔细想想,即便在资源
不那么丰盈,甚至资源紧缺的年代,紧凑小巧的数据结构一定会带来时间的浪费吗?或者说,速度快高效率的算法就一定要浪费内存吗?如果是这样,那么MMU是
怎么会被设计出来的呢?如果真的是这样,MMU会因其维护自身所消耗的时间和空间超过了它的目标带来的收益而被无情pass掉。然而,我们都知道,它最终
被设计出来了。并且,得益于CPU
Cache的高效利用,MMU退化成了一个Cache不命中时才会启用的慢速路径,而通过局部性我们知道,大多数时候,执行流走的是快速路经...看来,
思路该换一下了。
我知道的是,DxR算法就是这么玩的,所以这不是我个人在胡扯。但是我的玩法和DxR稍微有一点不同...
就
Linux等通用操作系统而言,路由表的查表开销主要集中在“最长掩码匹配”上,因为在数据包执行IP路由的过程中,输入仅仅是一个IPv4地址,即IP
头中提取的目标IP地址,而此时的IP路由模块并不知道路由表中哪些条目和这个IPv4地址相关,需要进行一次查找才能确定,在查找的过程中执行“最长掩
码匹配”逻辑,对于HASH组织算法而言,按照掩码的长度组织hash表,匹配顺序自32位掩码依次向下,而对于TRIE组织算法而言,情况也差不多,详
情参阅《Internet路由之路由表查找算法概述-哈希/LC-Trie树/256-way-mtrie树》。
对于查找而言,特别是HASH算法,难免要进行比较,比较结果要么为0要么非0,如果去除了比较的成本,理论上会节省一半的时间,对于TRIE树而言,算
上回溯,节省的成本更多。当然了,不管是HASH算法还是TRIE树算法,都会围绕数据结构本身以及地址的特点做很多的优化,但是遗憾的是,这些优化治标
不治本,无法从根本上将“查找”这个操作根除!好吧,消除查找/比较就是根本目标!
将IPv4地址索引化,就是答案!IPv4地址空间总共有4G个地址,如果将每一个地址都作为一个索引,那么将会消耗巨量的内存,但是这不是本质问题,完
全可以学着页表那样组织成分级索引。本质问题是如何将路由项和索引进行多对一的对应!即根据一个IPv4地址,将其作为一个索引,然后索引直接指向所有路
由结果中最长掩码的那一条结果!这个倒也不难,我姑且不引入多级索引,仍然用平坦的32位IPv4地址空间做一级索引。如下图所示: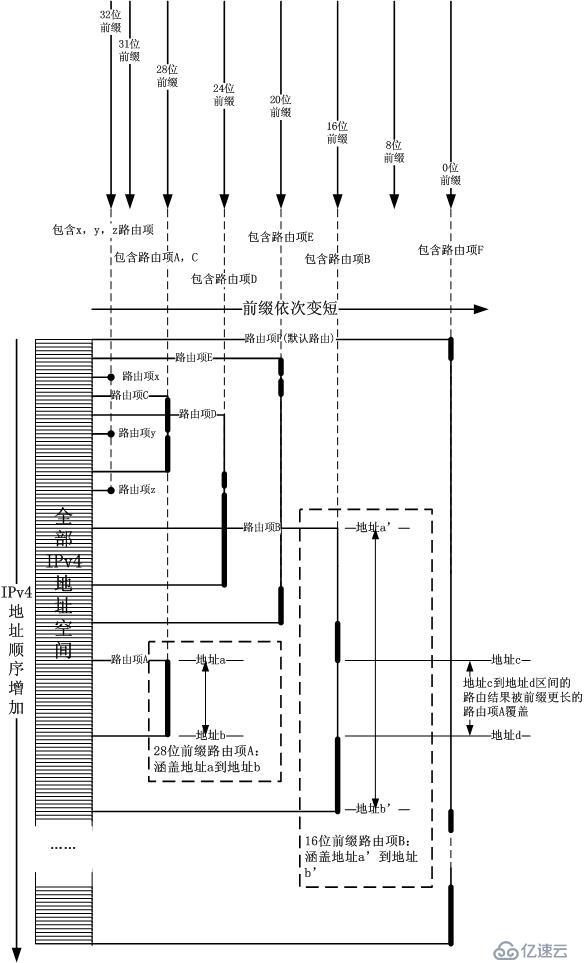 可
以看出,最关键的就是用路由前缀将IPv4地址空间划分为多个区间,按照上图所示,拿着目标IP地址当索引,向右走,碰到的第一个路由项就是结果。最长掩
码的逻辑完全体现在插入/删除过程中,即从左到右前缀依次变短,长前缀的路由项会盖在短前缀的路由项的前面,这就是核心思想。其实在HiPac防火墙中,
也正是使用了这个思想,即区间优先级。只是合理巧妙的编排数据结构,将最长掩码逻辑提前到插入/删除的时刻,将IP地址索引化,这样会让匹配过程一步到
位。
可
以看出,最关键的就是用路由前缀将IPv4地址空间划分为多个区间,按照上图所示,拿着目标IP地址当索引,向右走,碰到的第一个路由项就是结果。最长掩
码的逻辑完全体现在插入/删除过程中,即从左到右前缀依次变短,长前缀的路由项会盖在短前缀的路由项的前面,这就是核心思想。其实在HiPac防火墙中,
也正是使用了这个思想,即区间优先级。只是合理巧妙的编排数据结构,将最长掩码逻辑提前到插入/删除的时刻,将IP地址索引化,这样会让匹配过程一步到
位。
我们不能用前缀长的路由完全覆盖后面的,因为当它被删除掉的时候,后面的还是要暴露出来的。
好了,总结一下。插入/删除操作在执行的时候,保证了最长掩码的那个路由项覆盖在了它作用地址区间的最前面。
IP
互联网被设计成基于路由的而非基于交换的,这背后有一个哲学意义上理由。然而如今,人们逐渐在IP路由上加入了交换的特征,从而设计出了很多基于硬件的快
速转发装置或者依靠路由表生成交换转发表实现快速转发,比如三层交换机。但是到底什么是交换?什么又是路由?简单来讲,路由是一种比较软的叫法,其执行方
式为“取出协议头的字段,然后和路由表的内容做‘最长前缀匹配’,其间经历大量的访存,比较操作”,而交换则是比较硬一些的说法,其执行方式为“从协议头
中取出一个‘索引字段’,直接索引交换表,然后根据索引指向的结果直接转发”。看看吧,我的玩法和DxR是不是变路由为交换了,也许你觉得这无非雕虫小
技,但是生活难道不应该为这种小事情而乐呵乐呵么...
众所周知,现代操作系统是基于虚拟内存的,更好地实现了进程之间的隔离与访问控制,但是本文不谈这些,本文要说的是基于这个原则的“一种利用”。
事实上,在运行着现代操作系统的计算机的运行过程中,每访问一个地址都要经历一番“查找”,这个查找过程是如此地快以至于大多数用户甚至程序员(系统程序
员除外)都会视而不见,甚至很多人都不知道存在这么一个查找过程,这个查找过程就是MMU的虚拟/物理地址的转换过程。
如果我用IPv4路由前缀作为虚拟内存地址,将其对应的下一跳等路由结果信息作为物理页面的内容并按照此对应关系建立页表映射,那么我只需要访问一下从
IP头中抽取的目标IPv4地址,就可以获取对应的物理页面的内容,内容是什么?西服吗?NO!内容就是路由的结果。我将第一节的示意图加以简化再稍微变
换一下,变成了下面的样子: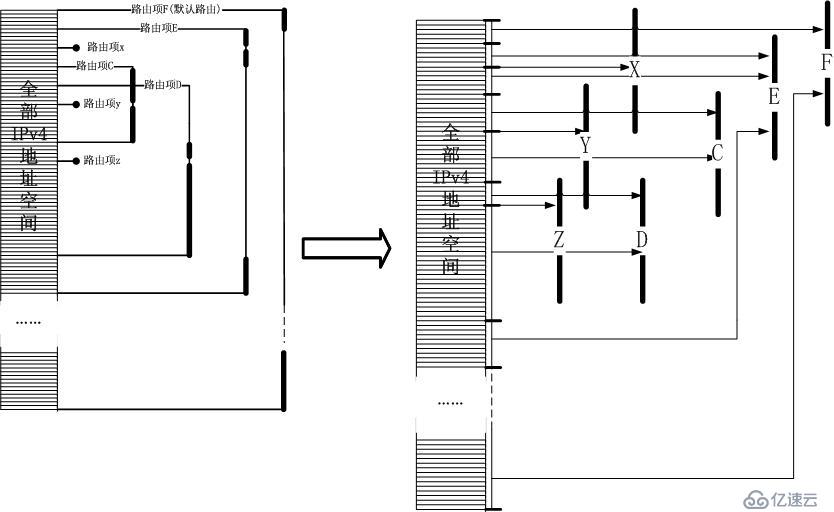 看出来什么了吗?这不就是页表么?是的,IPv4地址作为索引,而路由
项结果作为物理页面,最长掩码匹配过程体现在了构建映射的过程中。但是,这有问题!占用空间太大了!是的,MMU的解决办法就是构建多级映射,路由表也可
以采用这个原则。将上面的图折弯一下,就变成了一个类MMU设施的路由匹配表:
看出来什么了吗?这不就是页表么?是的,IPv4地址作为索引,而路由
项结果作为物理页面,最长掩码匹配过程体现在了构建映射的过程中。但是,这有问题!占用空间太大了!是的,MMU的解决办法就是构建多级映射,路由表也可
以采用这个原则。将上面的图折弯一下,就变成了一个类MMU设施的路由匹配表: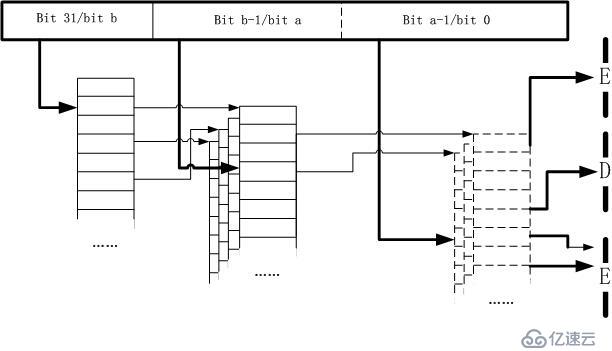 好了,现在完全将路由匹配表套在了MMU设施中,IPv4地址完全索引化!直接像访问内存地址那样“访问IPv4”地址,比如IPv4地址为0x01020304,那么为了获取它的路由项结果,只需要如下的访问:
好了,现在完全将路由匹配表套在了MMU设施中,IPv4地址完全索引化!直接像访问内存地址那样“访问IPv4”地址,比如IPv4地址为0x01020304,那么为了获取它的路由项结果,只需要如下的访问:
char *addr = 0x01020304; struct fib_res *res = (struct fib_res *)*addr;
如果发生缺页,就说明没有匹配的路由,即Network is unreachable,如果有默认路由,所有没有指定映射的虚拟地址都会落在“默认路由页面”上。
虽然上面画出的那幅图看上去真的狠像MMU设施,但是你注意到它们的区别了吗?
MMU映射的物理页面大小是固定的,然而路由表中被各条路由覆盖的地址区间范围却不是固定的,但是这又有什么关系呢?折腾了大半天准备写个模拟实现,觉得
很兴奋,然后去冲个澡,没办法,我喜欢冷,但是家里实在太冷了,也许,冲个热水澡可以带来点思路,然而不但没有带来什么思路,反而发现一个严重的问题,就
是路由项和物理页面无法完全类比,因为它的大小并不固定,如果按照类似4096大小页面来切分IPv4地址空间,最终在二级“路由页表”中索引到的是一个
覆盖4096个IPv4地址的范围,难道它们必须使用同一个路由项吗?我感觉自己那个时候好傻!把自己的思路向下推进一步问题就解决了,而这根本就不是一
个问题,我在上面最后一个图里画得一清二楚!我使用了全部的32位IPv4地址做索引,而不是像4096大小页表那样空出低12位!我实际上构建的是一个
地址表而不是地址块表。复杂性全部在插入以及对下一跳的编码上。我想,是绝对不能在最终的路由"页面"存储指针的,因为对于32位系统,指针要4字
节,64位的话更多,为了应付一个IPv4地址一条路由这种极端情况,每一个目标IPv4作为索引最终定位到的那个所谓的“项”,只能有一个字节可以使
用!!
一个字节怎么使用?如果我有1万个表项怎么办?哈哈!反过来想,最终我们要得到什么?得到一个下一跳而已!总共会有多少下一跳?256个够吗?我觉得是够
了!你可能会有1万个路由表项,但是它们会复用少得多的“下一跳”。你见过哪个路由器开花一样接200多根线缆出去的吗?交换机吧!因此我可能会如下的编
码:将所有的下一跳连续放在一块连续的内存中,每个项大小固定,然后用最终的路由页表加偏移指向的那一个字节索引这些下一跳们(如果下一跳们的数量超过了
256,那还有办法,就是从为了对齐而空余不用的byte中借位,对齐不但有利于快速内存寻址,也利用cacheline的映射)。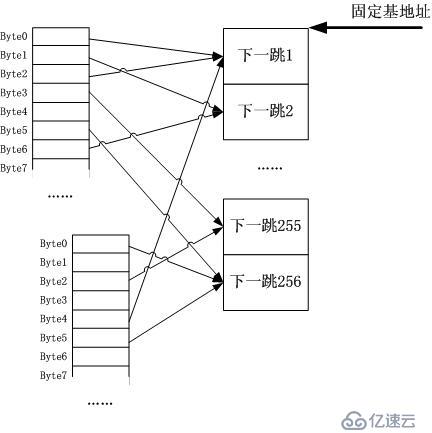 以上的图示是我事后画的,洗澡的时候我没有照着这个思路走下去,反而在思考D16R(以16bit作为直接索引的DxR实例)的合理性,难道我也要被引到
DxR的思想中去吗?想到这里,我又兴奋又沮丧,兴奋是由于我原创性质地自行设计出了DxR,沮丧在于我实在不想学它,我想设计一个完全索引化的多级索引
表,不加入任何所谓的“算法”,所以我要避开各种树,各种诸如二分查找之类的,甚至避开哈希和遍历。因此在用起来之前,我要记录一下我要避开这种算法的理
由,下面的一节本应该加密,万一被看到了,不喜勿喷,这不是吐嘈,这是爱好。
以上的图示是我事后画的,洗澡的时候我没有照着这个思路走下去,反而在思考D16R(以16bit作为直接索引的DxR实例)的合理性,难道我也要被引到
DxR的思想中去吗?想到这里,我又兴奋又沮丧,兴奋是由于我原创性质地自行设计出了DxR,沮丧在于我实在不想学它,我想设计一个完全索引化的多级索引
表,不加入任何所谓的“算法”,所以我要避开各种树,各种诸如二分查找之类的,甚至避开哈希和遍历。因此在用起来之前,我要记录一下我要避开这种算法的理
由,下面的一节本应该加密,万一被看到了,不喜勿喷,这不是吐嘈,这是爱好。
O(1)一定很快吗?O(n)和O(lgn)呢?大O当自强!
首先,在设计和实现一个体系的时候,不要被算法书上的理论捆住了手脚。大O旨在扩展性方面提供一个考量,简单说,如果算法不随着元素个数的增加而增加计算
延时,那么它就是O(1),如果元素个数和时间的增加是log关系,那么它就是O(lgn)。具体n是多少,曲线到多少才会"大拐"?也许你会说,这种基
于MMU的路由表不适合IPv6,那样它会占据大多的空间,因此就不具备可扩展性,但是我也没说要用于IPv6啊,对于IPv4路由而言,它难道不和32
位虚拟地址一样么?MMU的设计怎么就没有考虑可扩展性呢?答案是当MMU应用在64位系统上的时候,它可以有更多的选择,比如反向hash表等,但是对
于32位系统,完全索引化的MMU绝对比各种树各种hash要好,另外,它更适合硬件实现
,因为它“无逻辑”,简单!举一个不恰当的例子。如果一个O(1)算法,它的执行时间是100年,哪怕n到了10000000000...每趟下来都是
100年,绝对一个O(1)算法,另外有一个O(n2)算法,它在n等于100的时候执行时间为1ns,而赫拉克勒斯知道,在特定的环境中,n不会大于
500,你会选择哪个算法呢?
在IPv4的环境下,或者在不差钱买内存的IPv6环境下,或者在任意的可控的有限环境下(可别扯无限!在计算机中没有无限!你看OpenSSL中算个
big
number多费劲啊),多级索引表无疑是最快的数据结构,最好用的当然是hash,但它绝对没有索引快。索引化保证了速度,多级保证了空间占用不会太
大,其中级数就是算法执行操作的数量,别的都是浮云。
算法的大O法适合算法分析,但如果用于真实系统,必须考虑很多别的约束。大O在数据访问上忽略了访存寻址的开销,平滑了各级cache带来的效率差异(它
们可是数量级的差异啊),在指令执行上平滑了各种操作的指令时间差异,忽略了cache,忽略了MMU,然而这些在实际的实现中都不能忽略。算法分析甚至
都不能算是软件性能的分析,这不是它的缺陷,因为人家就不是干这个的。软件和硬件的改造都可以将同一个算法改良,硬件布线的不同可造成实际开销的差异,比
如换一条总线,挪一个位置...因此最终的性能应该是算法本身,软件实现,硬件实现三者的函数,权值偏重还不一样。人们往往十分在乎算法本身,其次在乎软
件实现,对于硬件,基本是仰望,没钱怎么都不行,不像前两者,换个算法,换个实现就可以搞定的。
这么美妙的一个类比,成全了一个完美的查找结构,是时候用起来了!
简单来讲,只需要建立一个“地址空间”,然后用路由表内容来填充MMU就可以了。但是没有这么简单,比如在Linux中会面临下面的问题:
因为地址空间中有数据也有指令,每一个指令,即进程本身的指令都会占据一个虚拟地址,这个地址便不能作为IPv4地址了...程序库封装了大量的指令,因此不能用。
这可没得玩了,内核本身为所有的地址空间共享,内核作为一个管理机构,其代码本身也映射在了任何地址空间中,比如0xC0000000以上的很多地址都是和物理内存一一映射的,不多说了吧。
由于代码指令的映射,整个虚拟地址空间不能全部为IPv4地址所用,那么解决办法是什么呢?
既然已经学会了思想,干嘛非要完完全全照搬呢?直接使用MMU设施?这个想法太疯狂,也印证了思想者太懒惰!诚然,你可以使用带有虚拟化支持的虚拟MMU中的一套设施,但这只能说明你对硬件本身比较精通。为何不自己构建一套软的MMU呢?
DxR路由表的构建无疑是紧凑而精妙的,它并没有指望使用现成的MMU,反而在其中加入了二分法,这便是一个很好的折中模拟,我也可以这么做。我并不指望
这个模拟MMU的匹配算法本身能有多快,而是要学习一下DxR的思想,即使用紧凑的数据结构来提高CPU
Cache的利用率,尽可能将结果Cache到CPU而不是将请求发射到总线!即便完全使用系统的硬件MMU,又能如何呢?能利用它的TLB吗?如果不
能,还有什么意义呢?你知道TLB命中意味着什么吗?你知道大部分的MMU寻址操作都不是直接去查页表而基本都是在TLB中命中的吗?TLB是一种
Cache!因此,模拟MMU并不是根本目的,利用Cache才是王道!
我们知道,CPU
Cache(包括TLB)之所以可以被以可观的频率命中,是因为内存寻址的局部性!对于IP地址而言,这种局部性存在吗?想象一下属于一个数据流的多个数
据包会持续经过,不同数据流的数据包错峰经过,就会知道局部性原则是一个普适的原则。核心路径上的流量工程都是基于路径的,而QoS是基于应用的,这种分
类原则会促进局部性而不是抵消它!毕竟,分类,what is
分类?这是一个哲学问题,柏拉图以来,两千年了,人们还在持续论争,分类到底是为了聚合,还是为了散列...
这是羊年春节期间的一个收获,类比了MMU,模拟了了MMU,另外的收获是,读了很多历史方面的书,看了几部电影,其中一部还算可以的恐怖片《怨灵》,在绍兴兰亭讲历史...
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





