这篇“怎么用Python实现常见数据格式转换”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“怎么用Python实现常见数据格式转换”文章吧。
代码如下:
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
print(os.getcwd())
# 结果为E:\python_code\crack\models_trainning
# ToDo 根据自己实际目录修改
# image_path = os.path.join(os.getcwd(), 'dataset/crack/test') # 根据自己实际目录修改,或者使用下面的路径
image_path = 'E:/python_code/crack/models_trainning/dataset/crack/test'
print(image_path)
xml_df = xml_to_csv(image_path)
xml_df.to_csv('./dataset/crack/train/crack_test.csv', index=None) # 根据自己实际目录修改
print('Successfully converted xml to csv.')
main()这里需要注意的是,这里的话我们只需要修改路径,就不需要在终端运行(每次需要先去该目录下)了,对于不玩linux的同学比较友好。
print(os.getcwd())
结果为E:\python_code\crack\models_trainning
image_path = os.path.join(os.getcwd(), 'dataset/crack/test') image_path = 'E:/python_code/crack/models_trainning/dataset/crack/test'
以上两种图片路径方法都可以,一个采用的是os.path.join()进行路径拼接。
xml_df.to_csv('./dataset/crack/train/crack_test.csv', index=None)保存为csv的路径可以随意写
结果如下

# -*- coding: utf-8-*-
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
import tensorflow.compat.v1 as tf
from PIL import Image
from research.object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# 将分类名称转成ID号
def class_text_to_int(row_label):
if row_label == 'crack':
return 1
# elif row_label == 'car':
# return 2
# elif row_label == 'person':
# return 3
# elif row_label == 'kite':
# return 4
else:
print('NONE: ' + row_label)
# None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
print(os.path.join(path, '{}'.format(group.filename)))
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = (group.filename + '.jpg').encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(csv_input, output_path, imgPath):
writer = tf.python_io.TFRecordWriter(output_path)
path = imgPath
examples = pd.read_csv(csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
# ToDo 修改相应目录
imgPath = r'E:\python_code\crack\models_trainning\dataset\crack\test'
output_path = 'dataset/crack/test/crack_test.record'
csv_input = 'dataset/crack/test/crack_test.csv'
main(csv_input, output_path, imgPath)如xml_to_csv类似,只要把路径改好即可
imgPath是图片所在文件夹路径
output_path是tfrecord生成的路径
csv_iinput是使用的csv的路径
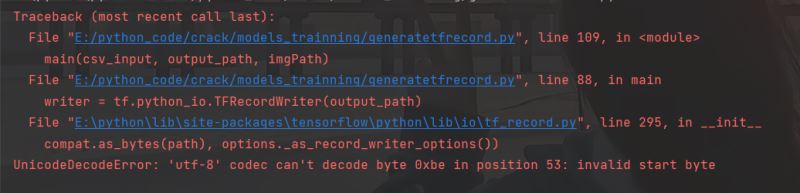
当然,你可能会出现下面报错,起初笔者还以为是编码问题,可是始终未能解决。后来仔细检查发现,是自己路径搞错了,因此大家出现这个错误的时候,检查一下路径先。
以上就是关于“怎么用Python实现常见数据格式转换”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





