LRUзј“еӯҳз®—жі•зҡ„е®һзҺ°ж–№жі•жҳҜд»Җд№Ҳ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңLRUзј“еӯҳз®—жі•зҡ„е®һзҺ°ж–№жі•жҳҜд»Җд№ҲвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңLRUзј“еӯҳз®—жі•зҡ„е®һзҺ°ж–№жі•жҳҜд»Җд№ҲвҖқеҗ§пјҒ
LRUе°ұжҳҜLeast Recently UsedпјҢеҚіжңҖиҝ‘жңҖе°‘дҪҝз”ЁпјҢжҳҜдёҖз§Қеёёз”Ёзҡ„йЎөйқўзҪ®жҚўз®—жі•пјҢе°ҶжңҖиҝ‘й•ҝж—¶й—ҙжңӘдҪҝз”Ёзҡ„йЎөйқўж·ҳжұ°пјҢе…¶е®һд№ҹеҫҲз®ҖеҚ•пјҢе°ұжҳҜиҰҒе°ҶдёҚеҸ—ж¬ўиҝҺзҡ„йЎөйқўеҸҠж—¶ж·ҳжұ°пјҢдёҚи®©е®ғеҚ зқҖиҢ…еқ‘дёҚжӢүshitпјҢжөӘиҙ№иө„жәҗгҖӮ
LRUжҳҜдёҖз§Қеёёи§Ғзҡ„йЎөйқўзҪ®жҚўз®—жі•пјҢеңЁи®Ўз®—дёӯпјҢжүҖжңүзҡ„ж–Ү件ж“ҚдҪңйғҪиҰҒж”ҫеңЁеҶ…еӯҳдёӯиҝӣиЎҢпјҢ然иҖҢи®Ўз®—жңәеҶ…еӯҳеӨ§е°ҸжҳҜеӣәе®ҡзҡ„пјҢжүҖд»ҘжҲ‘们дёҚеҸҜиғҪжҠҠжүҖжңүзҡ„ж–Ү件йғҪеҠ иҪҪеҲ°еҶ…еӯҳпјҢеӣ жӯӨжҲ‘们йңҖиҰҒеҲ¶е®ҡдёҖз§Қзӯ–з•ҘеҜ№еҠ е…ҘеҲ°еҶ…еӯҳдёӯзҡ„ж–Ү件иҝӣйЎ№йҖүжӢ©гҖӮ
еёёи§Ғзҡ„йЎөйқўзҪ®жҚўз®—жі•жңүеҰӮдёӢеҮ з§Қпјҡ
LRU жңҖиҝ‘жңҖд№…жңӘдҪҝз”Ё
FIFO е…Ҳиҝӣе…ҲеҮәзҪ®жҚўз®—жі• зұ»дјјйҳҹеҲ—
OPT жңҖдҪізҪ®жҚўз®—жі• (зҗҶжғідёӯеӯҳеңЁзҡ„)
NRU ClockзҪ®жҚўз®—жі•
LFU жңҖе°‘дҪҝз”ЁзҪ®жҚўз®—жі•
PBA йЎөйқўзј“еҶІз®—жі•
LRUеҺҹзҗҶ
LRUзҡ„и®ҫи®ЎеҺҹзҗҶе°ұжҳҜпјҢеҪ“ж•°жҚ®еңЁжңҖиҝ‘дёҖж®өж—¶й—ҙз»Ҹеёёиў«и®ҝй—®пјҢйӮЈд№Ҳе®ғеңЁд»ҘеҗҺд№ҹдјҡз»Ҹеёёиў«и®ҝй—®гҖӮиҝҷе°ұж„Ҹе‘ізқҖпјҢеҰӮжһңз»Ҹеёёи®ҝй—®зҡ„ж•°жҚ®пјҢжҲ‘们йңҖиҰҒ然其иғҪеӨҹеҝ«йҖҹе‘ҪдёӯпјҢиҖҢдёҚеёёи®ҝй—®зҡ„ж•°жҚ®пјҢжҲ‘们еңЁе®№йҮҸи¶…еҮәйҷҗеҲ¶еҶ…пјҢиҰҒе°Ҷе…¶ж·ҳжұ°гҖӮ
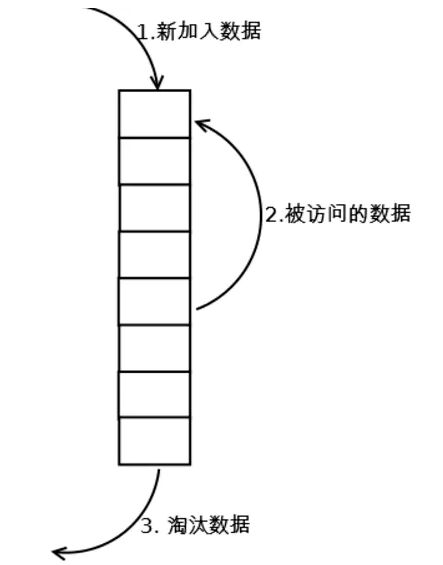
е…¶ж ёеҝғе°ұжҳҜеҲ©з”Ёж ҲпјҢиҝӣиЎҢж“ҚдҪңпјҢе…¶дёӯдё»иҰҒжңүдёӨйЎ№ж“ҚдҪңпјҢgetе’Ңput
get
getж—¶пјҢиӢҘж ҲдёӯжңүеҖјеҲҷе°ҶиҜҘеҖјзҡ„keyжҸҗеҲ°ж ҲйЎ¶пјҢжІЎжңүж—¶еҲҷиҝ”еӣһnull
put
ж ҲжңӘж»Ўж—¶пјҢиӢҘж ҲдёӯжңүиҰҒputзҡ„keyпјҢеҲҷжӣҙж–°жӯӨkeyеҜ№еә”зҡ„valueпјҢ并е°ҶиҜҘй”®еҖјжҸҗеҲ°ж ҲйЎ¶пјҢиӢҘж— иҰҒputзҡ„keyпјҢзӣҙжҺҘе…Ҙж Ҳ
ж Ҳж»Ўж—¶пјҢиӢҘж ҲдёӯжңүиҰҒputзҡ„keyпјҢеҲҷжӣҙж–°жӯӨkeyеҜ№еә”зҡ„valueпјҢ并е°ҶиҜҘй”®еҖјжҸҗеҲ°ж ҲйЎ¶;иӢҘж ҲдёӯжІЎжңүputзҡ„key ж—¶пјҢеҺ»жҺүж Ҳеә•е…ғзҙ пјҢе°Ҷputзҡ„еҖје…ҘеҲ°ж ҲйЎ¶
и§Јжі•пјҡз»ҙжҠӨдёҖдёӘж•°з»„пјҢжҸҗдҫӣ get е’Ң put ж–№жі•пјҢ并且йҷҗе®ҡ max ж•°йҮҸгҖӮ
дҪҝз”Ёж—¶пјҢget еҸҜд»Ҙж Үи®°жҹҗдёӘе…ғзҙ жҳҜжңҖж–°дҪҝз”Ёзҡ„пјҢжҸҗеҚҮе®ғеҺ»з¬¬дёҖйЎ№гҖӮput еҸҜд»ҘеҠ е…ҘжҹҗдёӘkey-valueпјҢдҪҶйңҖиҰҒеҲӨж–ӯжҳҜеҗҰе·Із»ҸеҲ°жңҖеӨ§йҷҗеҲ¶ max
иӢҘжңӘеҲ°иғҪзӣҙжҺҘеҫҖ数组第дёҖйЎ№йҮҢжҸ’е…Ҙ иӢҘеҲ°дәҶжңҖеӨ§йҷҗеҲ¶ maxпјҢеҲҷйңҖиҰҒж·ҳжұ°ж•°жҚ®е°ҫз«ҜдёҖдёӘе…ғзҙ гҖӮ
LRUCache cache = new LRUCache( 2 /* зј“еӯҳе®№йҮҸ */ ); cache.put(1, 1); cache.put(2, 2); cache.get(1); // иҝ”еӣһ 1 cache.put(3, 3); // иҜҘж“ҚдҪңдјҡдҪҝеҫ—еҜҶй’Ҙ 2 дҪңеәҹ cache.get(2); // иҝ”еӣһ -1 (жңӘжүҫеҲ°) cache.put(4, 4); // иҜҘж“ҚдҪңдјҡдҪҝеҫ—еҜҶй’Ҙ 1 дҪңеәҹ cache.get(1); // иҝ”еӣһ -1 (жңӘжүҫеҲ°) cache.get(3); // иҝ”еӣһ 3 cache.get(4); // иҝ”еӣһ 4
LRU з®—жі•и®ҫи®Ў
еҲҶжһҗдёҠйқўзҡ„ж“ҚдҪңиҝҮзЁӢпјҢиҰҒи®© put е’Ң get ж–№жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёә O(1)пјҢжҲ‘们еҸҜд»ҘжҖ»з»“еҮә cache иҝҷдёӘж•°жҚ®з»“жһ„еҝ…иҰҒзҡ„жқЎд»¶пјҡжҹҘжүҫеҝ«пјҢжҸ’е…Ҙеҝ«пјҢеҲ йҷӨеҝ«пјҢжңүйЎәеәҸд№ӢеҲҶгҖӮ
еӣ дёәжҳҫ然 cache еҝ…йЎ»жңүйЎәеәҸд№ӢеҲҶпјҢд»ҘеҢәеҲҶжңҖиҝ‘дҪҝз”Ёзҡ„е’Ңд№…жңӘдҪҝз”Ёзҡ„ж•°жҚ®;иҖҢдё”жҲ‘们иҰҒеңЁ cache дёӯжҹҘжүҫй”®жҳҜеҗҰе·ІеӯҳеңЁ;еҰӮжһңе®№йҮҸж»ЎдәҶиҰҒеҲ йҷӨжңҖеҗҺдёҖдёӘж•°жҚ®;жҜҸж¬Ўи®ҝй—®иҝҳиҰҒжҠҠж•°жҚ®жҸ’е…ҘеҲ°йҳҹеӨҙгҖӮ
йӮЈд№ҲпјҢд»Җд№Ҳж•°жҚ®з»“жһ„еҗҢж—¶з¬ҰеҗҲдёҠиҝ°жқЎд»¶е‘ў?е“ҲеёҢиЎЁжҹҘжүҫеҝ«пјҢдҪҶжҳҜж•°жҚ®ж— еӣәе®ҡйЎәеәҸ;й“ҫиЎЁжңүйЎәеәҸд№ӢеҲҶпјҢжҸ’е…ҘеҲ йҷӨеҝ«пјҢдҪҶжҳҜжҹҘжүҫж…ўгҖӮжүҖд»Ҙз»“еҗҲдёҖдёӢпјҢеҪўжҲҗдёҖз§Қж–°зҡ„ж•°жҚ®з»“жһ„пјҡе“ҲеёҢй“ҫиЎЁгҖӮ
LRU зј“еӯҳз®—жі•зҡ„ж ёеҝғж•°жҚ®з»“жһ„е°ұжҳҜе“ҲеёҢй“ҫиЎЁпјҢеҸҢеҗ‘й“ҫиЎЁе’Ңе“ҲеёҢиЎЁзҡ„з»“еҗҲдҪ“гҖӮиҝҷдёӘж•°жҚ®з»“жһ„й•ҝиҝҷж ·пјҡ
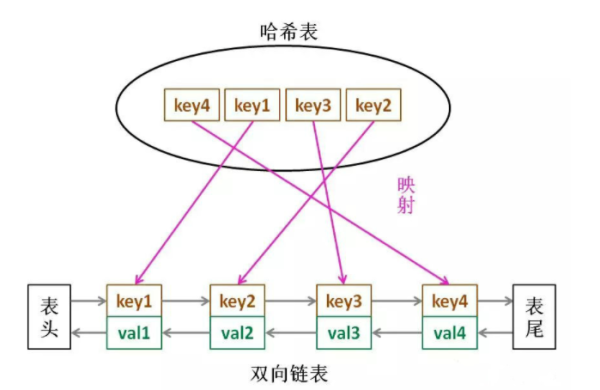
js е®һзҺ°
е·Із»ҸйҖҡиҝҮ leetCode 146 зҡ„жЈҖжөӢгҖӮжү§иЎҢз”Ёж—¶ : 720 msгҖӮеҶ…еӯҳж¶ҲиҖ— : 58.5 MBгҖӮ
function LRUCache(capacity) { this.capacity = capacity; // жңҖеӨ§йҷҗеҲ¶ this.cache = []; }; /** * @param {number} key * @return {number} */ LRUCache.prototype.get = function (key) { let index = this.cache.findIndex((item) => item.key === key); if (index === -1) { return -1; } // еҲ йҷӨжӯӨе…ғзҙ еҗҺжҸ’е…ҘеҲ°ж•°з»„第дёҖйЎ№ let value = this.cache[index].value; this.cache.splice(index, 1); this.cache.unshift({ key, value, }); return value; }; /** * @param {number} key * @param {number} value * @return {void} */ LRUCache.prototype.put = function (key, value) { let index = this.cache.findIndex((item) => item.key === key); // жғіиҰҒжҸ’е…Ҙзҡ„ж•°жҚ®е·Із»ҸеӯҳеңЁдәҶпјҢйӮЈд№ҲзӣҙжҺҘжҸҗеҚҮе®ғе°ұеҸҜд»Ҙ if (index > -1) { this.cache.splice(index, 1); } else if (this.cache.length >= this.capacity) { // иӢҘе·Із»ҸеҲ°иҫҫжңҖеӨ§йҷҗеҲ¶пјҢе…Ҳж·ҳжұ°дёҖдёӘжңҖд№…жІЎжңүдҪҝз”Ёзҡ„ this.cache.pop(); } this.cache.unshift({ key, value }); };дёҠйқўзҡ„еҒҡжі•е…¶е®һжңүеҸҳз§ҚпјҢеҸҜд»ҘйҖҡиҝҮдёҖдёӘеҜ№иұЎжқҘеӯҳй”®еҖјеҜ№пјҢдёҖдёӘж•°з»„жқҘеӯҳж”ҫй”®зҡ„йЎәеәҸгҖӮ
ж—¶й—ҙеӨҚжқӮеәҰ O(1)пјҢйӮЈе°ұдёҚиғҪж•°з»„йҒҚеҺҶеҺ»жҹҘжүҫ key еҖјгҖӮеҸҜд»Ҙз”Ё ES6 зҡ„ Map жқҘи§ЈдәҶпјҢеӣ дёә Map ж—ўиғҪдҝқжҢҒй”®еҖјеҜ№пјҢиҝҳиғҪи®°дҪҸжҸ’е…ҘйЎәеәҸгҖӮ
function LRUCache(capacity) { this.cache = new Map(); this.capacity = capacity; // жңҖеӨ§йҷҗеҲ¶ }; LRUCache.prototype.get = function (key) { if (this.cache.has(key)) { // еӯҳеңЁеҚіжӣҙж–° let temp = this.cache.get(key); this.cache.delete(key); this.cache.set(key, temp); return temp; } return -1; }; LRUCache.prototype.put = function (key, value) { if (this.cache.has(key)) { // еӯҳеңЁеҚіжӣҙж–°пјҲеҲ йҷӨеҗҺеҠ е…Ҙпјү this.cache.delete(key); } else if (this.cache.size >= this.capacity) { // дёҚеӯҳеңЁеҚіеҠ е…Ҙ // зј“еӯҳи¶…иҝҮжңҖеӨ§еҖјпјҢеҲҷ移йҷӨжңҖиҝ‘жІЎжңүдҪҝз”Ёзҡ„ this.cache.delete(this.cache.keys().next().value); } this.cache.set(key, value); };ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңLRUзј“еӯҳз®—жі•зҡ„е®һзҺ°ж–№жі•жҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№LRUзј“еӯҳз®—жі•зҡ„е®һзҺ°ж–№жі•жҳҜд»Җд№ҲиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ





