本篇内容介绍了“ChatGPT最小元素的设计方法是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
上一节随着我能抓openai的列表之后,我的野心开始膨胀,既然我们写了一个框架,可以开始写面向各网站的爬虫了,为什么只面向ChatGPT呢?几乎所有的平台都是这么个模式,一个列表,然后逐个抓取。那我能不能把这个能力泛化呢?可不可以设计一套机制,让所有的抓取功能都变得很简单呢?我抽取一系列的基础能力,而不管抓哪个网站只需要复用这些能力就可以快速的开发出爬虫。公司内的各种平台都是这么想的对吧?
那么我们就需要进行设计建模,如果按照正常的面向对象,我可能会这么设计建模:
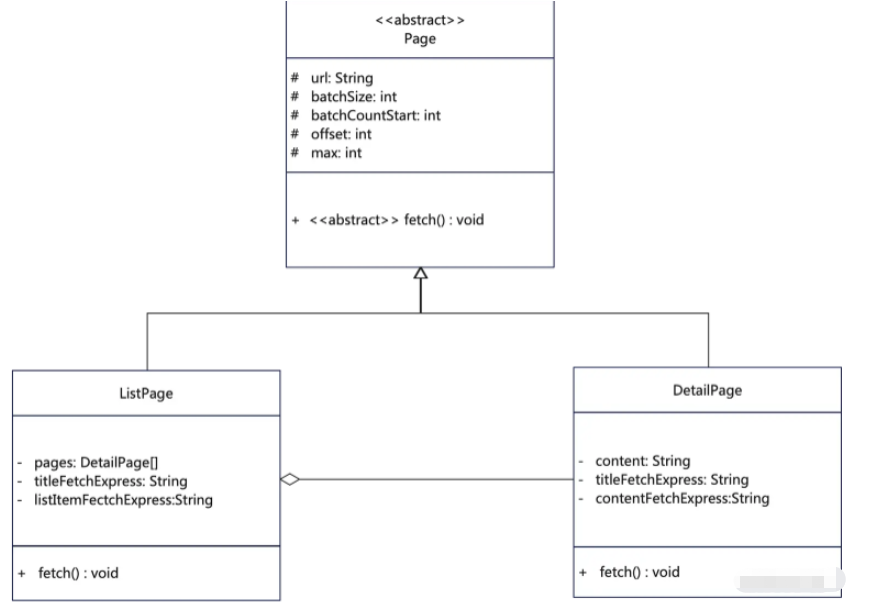
看起来很美好不是吗?是不是可以按照设计去写代码了?其实完全是扯淡,魔鬼隐藏在细节中,每个网站都有各种复杂的HTML、他们可能是简单的列表,也可能是存在好几个iframe,而且你在界面上看到的列表和你真正点开的又不一样,比如说:
有的小说网站,它的列表上假如有N个列表项,但是你真的点击去之后,你会发现有的章节点击他只有一半内容,再点下一页的时候它会调到一个不在列表页上的展示的页面,展示后半段内容,而你如果只根据列表链接去抓,你会丢掉这后半段内容。
有的网站会在你点了几个页面后随机出现一个按钮,点击了才能展开后续内容,防止机器抓取。你不处理这种情况,直接去抓就抓不全。
而有的网站根本就是图片展示文本内容,你得把图片搞下来,然后OCR识别,或者插入了各种看不见的文本需要被清洗掉。
而且每个网站还会升级换代,他们一升级换代,你的抓取方式也要跟着变。 等等等等……而且所有这些要素之间还可以排列组合:
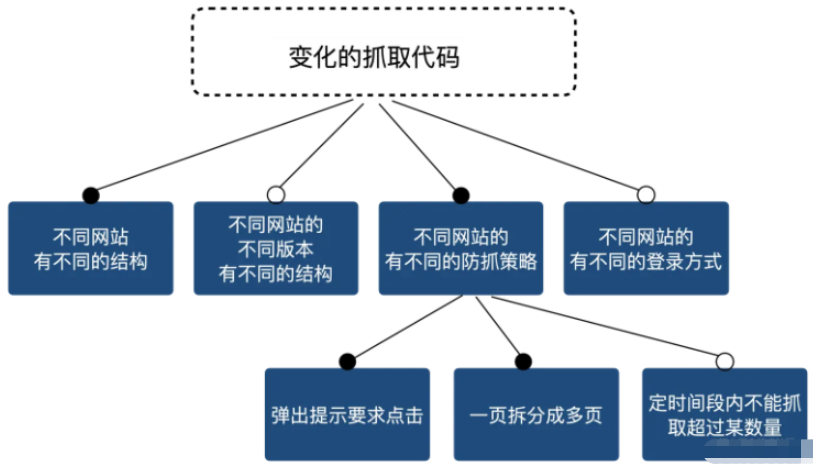
所以最上面的那个建模只能说过于简化而没有用处,起码,以前是这样的。
在以前,我们可能会进一步完善这个设计,得到一系列复杂的内部子概念、子机制、子策略,比如:
反防抓机制
详情分页抓取策略
清洗机制
然后对这些机制进行组合。
然而这并不会让问题变简单,人们总是低估胶水代码的复杂度,最终要么整个体系非常脆弱,要么就从胶水处开始腐化。
那么在今天,我们有没有什么新的做法呢?我们从一个代码示例开始讲起,比如,我这里有一个抓取某小说网站的代码:
const fs = require('fs/promises');
async function main() {
const novel_section_list_url = 'https://example.com/list-1234.html';
await driver.goto(novel_section_list_url);
const novelSections = await driver.evaluate(() => {
let title = getNovelTitle(document)
let section_list = getNovelSectionList(document);
return {
title, section_list
}
function getNovelTitle(document) {
return document.querySelector("h2.index_title").textContent;
}
function getNovelSectionList(document) {
let result = [];
document.querySelectorAll("ul.section_list>li>a").forEach(item => {
const { href } = item;
const name = item.textContent;
result.push({ href, name });
});
return result;
}
});
console.log(novelSections.section_list.length);
const batchSize = 50;
const title = novelSections.title;
let section_list = novelSections.section_list;
if (intention.part_fetch) {
section_list = novelSections.section_list.slice(600, 750);
}
await batchProcess(section_list, batchSize, async (one_batch, batchNumber) => {
await download_one_batch_novel_content(one_batch, driver);
async function download_one_batch_novel_content(one_batch, driver) {
let one_text_file_content = "";
for (section of one_batch) {
await driver.goto(section.href);
await driver.waitForTimeout(3000);
const section_text = await driver.evaluate(() => {
return "\n\n" + document.querySelector("h2.chapter_title").textContent
+ "\n"
+ document.querySelector("#chapter_content").textContent;
});
one_text_file_content += section_text;
}
await fs.writeFile(`./output/example/${title}-${batchNumber}.txt`, one_text_file_content);
}
});
}
main().then(() => { });
async function batchProcess(list, batchSize, asyncFn) {
const listCopy = [...list];
const batches = [];
while (listCopy.length > 0) {
batches.push(listCopy.splice(0, batchSize));
}
let batchNumber = 12;
for (const batch of batches) {
await asyncFn(batch, batchNumber);
batchNumber++;
}
}在实际工作中这样的代码应该是比较常见的,由于上述的设计没有什么用处,我们经常见到的就是另一个极端,那就是代码写的过于随意,整个代码的实现变得无法阅读,当我想要做稍微地调整,比如说我昨天抓了100个,今天接着从101个往后抓,就要去读代码,然后从代码中看改点什么好让这个抓取可以从101往后抓。
那在以前呢,我们就要像上面说的要设计比较精密的机制,而越是精密的机制,就越不健壮。而且,以我的经验,你想让人们使用那么精细的机制也不好办,因为大多数人的能力并不足以驾驭精细的机制。
而在今天,我们可以做的更粗放一些。
首先,我们意识到有些代码,准确的说,是有些变量,是我们经常修改的,所以我们在不改变整体结构的情况下,我们把这些变量提到上面去,变成一个变量:
//意图描述
const intention = {
list_url:'https://example.com/list-1234.html',
batchSize: 50,
batchStart: 12,
page_waiting_time: 3000,
part_fetch:{ //如果全抓取,就注释掉整个part_fetch属性
from:600,//不含该下标
to:750
},
output_folder: "./output/example"
}
const fs = require('fs/promises');
const driver = require('../util/driver.js');
async function main() {
const novel_section_list_url = intention.list_url;
await driver.goto(novel_section_list_url);
const novelSections = await driver.evaluate(() => {
let title = getNovelTitle(document)
let section_list = getNovelSectionList(document);
return {
title, section_list
}
function getNovelTitle(document) {
return document.querySelector("h2.index_title").textContent;
}
function getNovelSectionList(document) {
let result = [];
document.querySelectorAll("ul.section_list>li>a").forEach(item => {
const { href } = item;
const name = item.textContent;
result.push({ href, name });
});
return result;
}
});
console.log(novelSections.section_list.length);
const batchSize = intention.batchSize;
const title = novelSections.title;
let section_list = novelSections.section_list;
if (intention.part_fetch) {
section_list = novelSections.section_list.slice(intention.part_fetch.from, intention.part_fetch.to);
}
await batchProcess(section_list, batchSize, async (one_batch, batchNumber) => {
await download_one_batch_novel_content(one_batch, driver);
async function download_one_batch_novel_content(one_batch, driver) {
let one_text_file_content = "";
for (section of one_batch) {
await driver.goto(section.href);
await driver.waitForTimeout(intention.page_waiting_time);
const section_text = await driver.evaluate(() => {
return "\n\n" + document.querySelector("h2.chapter_title").textContent
+ "\n"
+ document.querySelector("#chapter_content").textContent;
});
one_text_file_content += section_text;
}
await fs.writeFile(`${intention.output_folder}/${title}-${batchNumber}.txt`, one_text_file_content); //一个批次一存储
}
});
}
main().then(() => { });
async function batchProcess(list, batchSize, asyncFn) {
const listCopy = [...list];
const batches = [];
while (listCopy.length > 0) {
batches.push(listCopy.splice(0, batchSize));
}
let batchNumber = intention.batchStart;
for (const batch of batches) {
await asyncFn(batch, batchNumber);
batchNumber++;
}
}于是我们把程序分成了两部分结构:

接下来我会发现,在网站不变的情况下,下面这个意图执行代码相当的稳定。我经常需要做的不管是偏移量的计算,还是修改抓取目标等等,这些都只需要修改上面的意图描述数据结构即可。而且我们可以做进一步的封装,得到下面的代码(下面的JsDoc也是ChatGPT给我写的):
/**
* @typedef {Object} Intention
* @property {string} list_url
* @property {integer} batchSize
* @property {integer} batchStart
* @property {integer} page_waiting_time
* @property {PartFetch} part_fetch 如果全抓取,就注释掉整个part_fetch属性
* @property {string} output_folder
*
* @typedef {Object} PartFetch
* @property {integer} from 不含该下标
* @property {integer} batchStart
*/
//意图执行
/**
* @param {Intention} intention
*/
module.exports = (intention, context) => {
Object.assign(this, context);
const {fs,console} = context;
async function main() {
const novel_section_list_url = intention.list_url;
await driver.goto(novel_section_list_url);
const novelSections = await driver.evaluate(() => {
let title = getNovelTitle(document)
let section_list = getNovelSectionList(document);
return {
title, section_list
}
function getNovelTitle(document) {
return document.querySelector("h2.index_title").textContent;
}
function getNovelSectionList(document) {
let result = [];
document.querySelectorAll("ul.section_list>li>a").forEach(item => {
const { href } = item;
const name = item.textContent;
result.push({ href, name });
});
return result;
}
});
console.log(novelSections.section_list.length);
const batchSize = intention.batchSize;
const title = novelSections.title;
// const section_list = novelSections.section_list.slice(0, 3);
let section_list = novelSections.section_list;
if (intention.part_fetch) {
section_list = novelSections.section_list.slice(intention.part_fetch.from, intention.part_fetch.to);
}
await batchProcess(section_list, batchSize, async (one_batch, batchNumber) => {
await download_one_batch_novel_content(one_batch, driver);
async function download_one_batch_novel_content(one_batch, driver) {
let one_text_file_content = "";
for (section of one_batch) {
await driver.goto(section.href);
await driver.waitForTimeout(intention.page_waiting_time);
const section_text = await driver.evaluate(() => {
return "\n\n" + document.querySelector("h2.chapter_title").textContent
+ "\n"
+ document.querySelector("#chapter_content").textContent;
});
one_text_file_content += section_text;
}
await fs.writeFile(`${intention.output_folder}/${title}-${batchNumber}.txt`, one_text_file_content); //一个批次一存储
}
});
}
main().then(() => { });
async function batchProcess(list, batchSize, asyncFn) {
const listCopy = [...list];
const batches = [];
while (listCopy.length > 0) {
batches.push(listCopy.splice(0, batchSize));
}
let batchNumber = intention.batchStart;
for (const batch of batches) {
await asyncFn(batch, batchNumber);
batchNumber++;
}
}
}于是我们就有了一个稳定的接口将意图的描述和意图的执行彻底分离,随着我对我的代码进行了进一步的整理后发现,这个意图描述结构竟然相当的通用,我写的好多网站的抓取代码竟然都可以抽取出这样一个结构。 于是我们可以进一步抽象,到了一种适用于我特定领域的DSL,类似下面的结构:
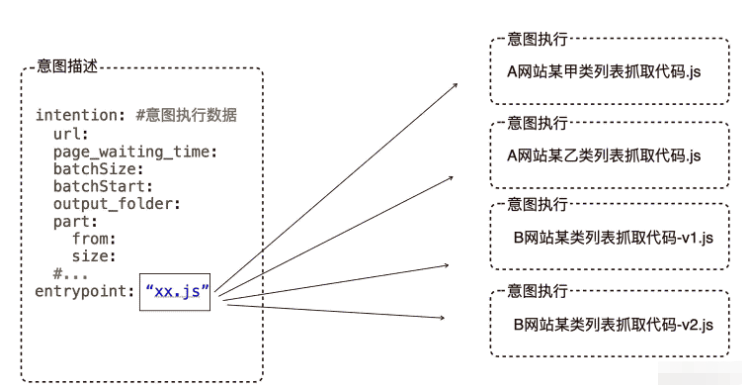
到此为止,我的意图描述和意图执行彻底解耦,意图执行变成了意图描述中的一个属性,我只需要写一个引擎,根据意图描述中entrypoint的属性值,加载对应的函数,然后将意图数据传给他就可以了,大概的代码如下:
const intentionString = await fs.readFile(templatePath, 'utf8'); const intention = yaml.load(intentionString); const intention_exec = require(intention.entrypoint); intention_exec(intention, context);
而我们的每一个意图执行的代码,可以有自己的不同变化原因,不管是网站升级了,还是我们要抓下一个网站了,我们只需要把HTML扔给ChatGPT,他就可以帮我们生成对应的意图执行代码。哪怕我们想基于一些可以复用库函数,比如之前说的反防抓、反详情页分页机制封装的库函数,他也可以给我们生成胶水代码把这些函数粘起来(具体的手法我们在后续的文章里讲),所有这一切的变化,都可以用ChatGPT生成代码这一步解决。那么所谓的在胶水层腐化的问题也就不存在了。
很有趣的是,在我基于该结构的DSL得到一组实例之后,我很快就开始产生了在DSL这一层的新需求,比如:
DSL文件的管理需求,因为人总是很懒的,而且我只有业余时间写点这些东西,不能保证自己一直记得哪个网站对应哪个文件,然后怎么设置。
我还希望能够根据我本地已经抓的内容和智能生成偏移量
我也希望能定时去查看更新然后生成抓取意图。
这一切都是很有价值的需求,而如果我们没有一个稳定的下层DSL结构,我们这些更上层需求也注定是不稳定的。
而有了这个稳定的DSL结构后,我们回过头来看我们的设计,其实是在更大的尺度上实现了面向对象设计中的开闭原则,尽管扩展需要大量的代码,而这些代码却并不需要人来写,所以效率依然很高。
“ChatGPT最小元素的设计方法是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





