目的
两年前曾为了租房做过一个找房机器人 「爬取豆瓣租房并定时推送到微信」,维护一段时间后就荒废了。
当时因为代码比较简单一直没开源,现在想想说不定开源后也能帮助一些同学更好的找到租房信息,所以简单整理后,开源到 github,地址:https://github.com/facert/zufang (本地下载)
下面是当时写的简单原理介绍:
身在帝都的人都知道租房的困难,每次找房都是心力交瘁。其中豆瓣租房小组算是比较靠谱的房源了,但是由于小组信息繁杂,而且没有搜索的功能,想要实时获取租房信息是件很困难的事情,所以最近给自己挖了个坑,做个微信找房机器人,先看大概效果吧,见下图:
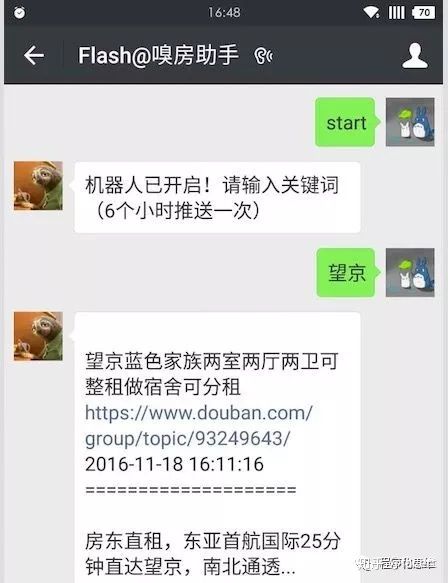

实现
说下大概的技术实现吧,首先是 scrapy 爬虫对于豆瓣北京租房的小组实时爬取,并做了全文检索,对 title, description 使用 jieba 和 whoosh 进行了分词和索引,做成 api。接下来就是应用的接入,网上有微信机器人的开源 [wxBot](http://github.com/liuwons/wxBo),所以对它进行了修改, 实现了定时推送和持久化。最后顺便把公众号也做了同样的功能,支持实时租房信息搜索。
部分代码
scrapy 支持自定义 pipeline,能很方便的实现数据录入的时候实时生成索引,见 code:
class IndexPipeline(object):
def __init__(self, index):
self.index = index
@classmethod
def from_crawler(cls, crawler):
return cls(
index=crawler.settings.get('WHOOSH_INDEX', 'indexes')
)
def process_item(self, item, spider):
self.writer = AsyncWriter(get_index(self.index, zufang_schema))
create_time = datetime.datetime.strptime(item['create_time'], "%Y-%m-%d %H:%M:%S")
self.writer.update_document(
url=item['url'].decode('utf-8'),
title=item['title'],
description=item['description'],
create_time=create_time
)
self.writer.commit()
return item
搜索 api 代码很简单:
def zufang_query(keywords, limit=100):
ix = get_index('indexes', zufang_schema)
content = ["title", "description"]
query = MultifieldParser(content, ix.schema).parse(keywords)
result_list = []
with ix.searcher() as searcher:
results = searcher.search(query, sortedby="create_time", reverse=True, limit=limit)
for i in results:
result_list.append({'url': i['url'], 'title': i['title'], 'create_time': i['create_time']})
return result_list
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





