这篇文章给大家分享的是有关Hive架构设计及原理的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
Hive架构设计及原理
1.什么是Hive:
Hive是构建在Hadoop之上的数据仓库平台,可以结构化的数据文件映射为一张数据库表,并提供完整的SQL查询,然后将SQL语句转换为MapRuce任务进行运行,提交YARN平台调度,优点学习成本之低,通过SQL语句快速实现简单的MapReduce统计
Hive没有专门的数据格式,可以很好的工作在Thrift之上,控制分隔符 允许用户指定的数据格式
2.Hive运行流程及架构:
Hive创建的表的元信息存在于关系型数据库之内, 默认情况下Hive元数组保存在内嵌的Derby数据库,Derby只允许一个回话连接 不适合生产环境,关系型数据库可以是MySQL做为元数据库 Hive内部提供了很好的支持 只需要配置 URL Driver User )而表中的内容存在于HDFS之中,用户输入SQL语句之后进行编译,然后在模板库找到对应的模板组装, MapReduce/Spark/Tez JOB运算,最后交给Yarn调度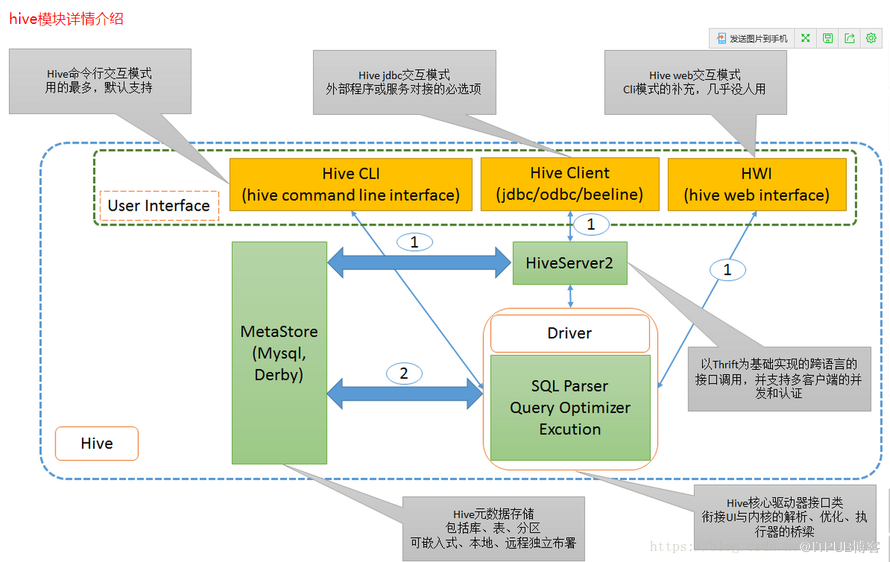
3.Hive体系结构:
一、用户接口主要有三个:CLI命令行,Client 和 Web UI
二、MetaStore: hive 的元数据结构存储,可选用不同的关系型数据库来存储,通过配置文件修改、查看数据库配置信息
三、解释器、编译器、优化器、执行器
Driver: hive核心驱动器接口类,衔接UI与内核的解析、优化、执行器的桥梁,生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行
Driver 调用解释器(Compiler)处理 HiveQL 字串,这些字串可能是一条 DDL、DML或查询语句。编译器将字符串转化为策略(plan)。策略仅由元数据操作 和 HDFS 操作组成,元数据操作只包含 DDL 语句,HDFS 操作只包含 LOAD 语句。对插入和查询而言,策略由 MapReduce 任务中的具有方向的非循环图(directedacyclic graph,DAG)组成,具体流程如下。
1)解析器(parser):将查询字符串转化为解析树表达式。
2)语义分析器(semantic analyzer):将解析树表达式转换为基于块(block-based)的内部查询表达式,将输入表的模式(schema)信息从 metastore 中进行恢复。用这些信息验证列名, 展开 SELECT * 以及类型检查(固定类型转换也包含在此检查中)。
3)逻辑策略生成器(logical plan generator):将内部查询表达式转换为逻辑策略,这些策略由逻辑操作树组成。
4)优化器(optimizer):通过逻辑策略构造多途径并以不同方式重写。优化器的功能如下。
将多 multiple join 合并为一个 multi-way join;
对join、group-by 和自定义的 map-reduce 操作重新进行划分;
消减不必要的列;
在表扫描操作中推行使用断言(predicate);
对于已分区的表,消减不必要的分区;
在抽样(sampling)查询中,消减不必要的桶。
此外,优化器还能增加局部聚合操作用于处理大分组聚合(grouped aggregations)和 增加再分区操作用于处理不对称(skew)的分组聚合。
四、Hadoop
Hive的数据存储在HDFS中大部分查询有MapReduce完成(select * from table 不会生成MapReduce任务)
使用HQL作为查询接口、HDFS作为存储底层、mapReduce作为执行层, 基于Hadoop平台解决了企业数据仓库构建的核心技术问题
感谢各位的阅读!关于“Hive架构设计及原理的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





