这篇文章主要介绍“虚拟化Pod性能比裸机还要好的原因”,在日常操作中,相信很多人在虚拟化Pod性能比裸机还要好的原因问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”虚拟化Pod性能比裸机还要好的原因”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
为什么太平洋项目的 Native Pods 更快?
现代的服务器一般有多个处理器(CPU),采用的是 NUMA(非统一内存访问)的内存访问方式。在 NUMA 体系架构中,每个 CPU 负责管理一块内存,称为本地(local)内存。
当 CPU 访问自己管理的内存时,因为是就近访问,速度比较快;但如果需要访问其它 CPU 名下的内存时(称为远程访问),往往需要经过若干个电路开关,通常会慢一些。
ESXi 在调度 Pod 的时候,考虑到了 Pod 使用内存的本地性(locality),会确保其尽量访问本地内存,这样 Pod 运行性能比较好,并提高总体 CPU 效率。另一方面,裸机 Linux 中的进程调度程序可能无法在 NUMA 域之间提供类似的功能,因此性能有一定的损失。
ESXi CPU 调度程序知道 Pod 是独立的运行实体,因此会尽量确保其内存访问位于本地 NUMA 域内,大大减少了远程内存访问的次数,从而为 Pod 中的工作负载提供更好的性能,并提高 CPU 总体效率。另一方面,Linux 中的进程调度程序无法较好地识别 NUMA 域之间差异,所以不能提供类似的调度能力。
太平洋项目 Native Pods 的性能评估实验
为了比较性能,VMware 的工程师在相同的硬件上配置了图1所示的测试平台,每台服务器硬件是 2.2 GHz 的内核 44 个以及 512 GB 内存:
a) 两个太平洋项目的ESXi节点和其上的主管集群
b) 两个缺省配置的某主流企业级 Linux 裸机集群节点
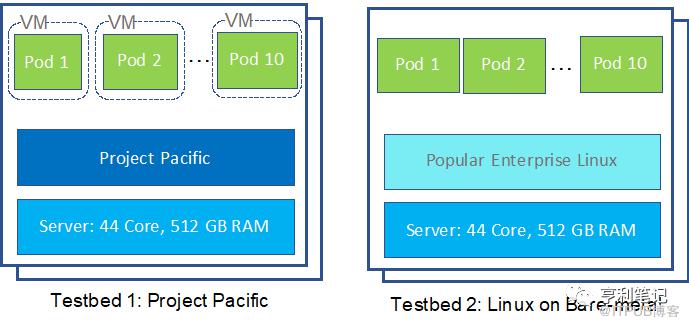 图1:测试平台配置
图1:测试平台配置
通常,超线程处理器内核具有多个逻辑内核(超线程),它们之间共享硬件资源。为了减少对测试影响的因素,在两个测试平台中都禁用了超线程。在每个集群中,使用其中一个节点作为被测系统(Worker Node),而在另一个节点上运行 Kubernetes Master 。

图2:Pod配置
在 Worker 节点中部署了10个 Kubernetes Pod,每个 Pod 的资源限制为 8个CPU,42 GB 内存,并在每个容器中运行一个标准 Java 事务基准测试,如图2所示。
考虑到用于我们的工作负载的复杂性和性质,在实验中使用了较大的 Pod ,以便管理测试样例运行和 Pod 的评分汇总。使用 Pod 定义将 Pod 固定(affinitized)到每个测试平台中的 Worker节点。使用所有10个 Pod 的汇总分数(最大吞吐量)来评估被测系统的性能。测试中基本没有设计I / O或网络传输,并且所有实验都限于单个 Kubernetes节点。因此,I / O或网络性能方面的影响不在本文中讨论。
测试结果
图3显示了某主流企业级 Linux 裸机节点的性能和太平洋主管群集的性能(绿色条)对比,裸机 Linux 的性能作为基准1.0。
与裸机企业级 Linux 相比,太平洋主管群集的性能提高了8%。
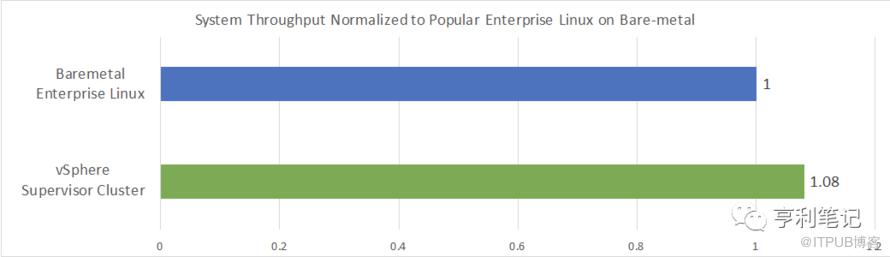
图3:太平洋主管集群与裸机企业级Linux节点相对性能
测试重复了多次并用平均数减少了实验的误差。与裸机情况相比,太平洋主管群集可实现约8%的总体性能提升。
分析和优化
查看系统统计信息,与 vSphere 主管集群相比,裸机上运行的工作负载被许多远程 NUMA 内存访问拖累了性能。vSphere 主管群集的性能优势主要来自更优的CPU调度方法,同时还抵扣掉因虚拟化带来的性能额外开销。
进一步分析发现,在裸机 Linux 中,只有约43.5%的非命中L3高速缓存的数据可从本地 DRAM 中获取,其余的则需要由远程内存提供。相比之下,vSphere 主管群集得益于ESXi中出色的 CPU 调度功能,有 99.2%的未命中 L3 数据可在本地 DRAM中获得,从而避免了远程内存访问,提高了vSphere主管群集的性能。(如图4所示)
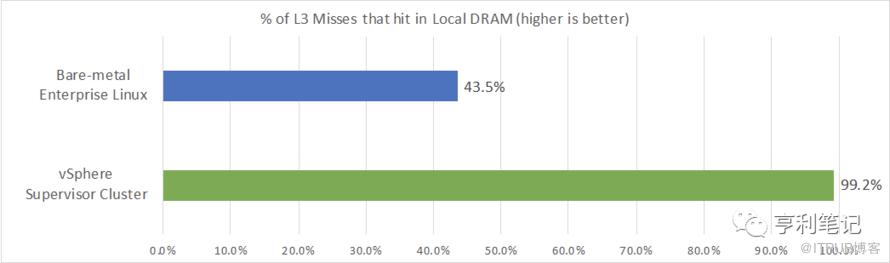
图4:vSphere 主管群集与裸机 Linux上的 DRAM 命中率对比(数值越大越好)
为了减少裸机 Linux上非本地 NUMA 访问对性能的影响,工程师们尝试了一些基本的优化,例如切换 NUMA 平衡开关和使用基于任务集的Pod固定到 CPU,但是这些都没有实质性地提高性能。目前 Kubernetes 没有对 NUMA 架构的 CPU 使用纳入 Pod 规范,因此暂时没有教好的方法解决这个问题。
在本实验的结论取决于Pod访问内存的密集度情况,如果工作负载具有不同的内存需求,则 NUMA 本地性对其性能的影响可能会有所不同。简而言之,对内存访问频率高的 Pod 应用,跑在 vSphere 主管群集上可能比裸机上性能更好。
更多信息,参见:
https://blogs.vmware.com/performance/2019/10/how-does-project-pacific-deliver-8-better-performance-than-bare-metal.html
到此,关于“虚拟化Pod性能比裸机还要好的原因”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





