这篇文章给大家分享的是有关python中普通程序员如何了解日志系统的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
当我们在做系统开发时,日志系统是绕不开的话题。作为日志系统的最终使用者,我们会接触不同的日志系统,比如 log4j、 logback 和 slf4j 等等,还会接触到日志系统的各种概念,比如 Formatter、Appender 和 Priority 等。这些日志系统有什么区别,这些概念又该怎么理解呢?
今天我们就聊下:我们普通程序员,也就是日志系统最终使用者,可以怎么理解日志系统。
Logging 系统的雏型
让我们回到计算机世界的远古时期或者我们刚刚接触计算机世界的时期,那个时候我们有两种调试程序的办法:1)单步调试,一步步地跟踪,查看代码中变量的值。2) 是 printf 大法 —— 在特定的地方打印日志, 通过日志的输出,帮助快速定位。
单步调试方法费时费力,但能准确定位问题。printf 大法简单粗暴,需要尝试,大部分情况能快速找到问题。单步调试和 printf 方法搭配使用,相得益彰。但是单步调试止步于 gdb 等调试工具,而 printf 大法最终发展出了一系列的日志系统。原因就在于单步调试在程序员调试才能用,而 printf 大法可以在调试和生产线上都能用,并且输出的日志被各方面的人利用和解读。
什么时候打印日志是个问题 —— Level
printf 大法是很简陋的。在调试过程中,有可能日志打到很细粒度,比如每条数据的第三个字段是什么都打印出来了,但是真正运行又要把这些细粒度的日志删除。等到下次调试,我们又要知道每条数据的第三个字段是什么了。为此,我们希望日志打印是智能:调试或者线上出问题的时候,各种细粒度的日志全部打印出来,正常运行的时候输出一些最简单的信息就可以了。
针对这个问题,日志系统引入日志级别(Level)的办法解决。引入日志级别的概念之后,我们编程时打印日志,需要指明这条日志的级别。由于日志级别是最重要的参数,现在的日志系统都是直接通过使用不同的函数来指明级别的,包括 logger.TRACE、logger.DEGUB、logger.INFO、logger.WARN、logger.ERROR、logger.FATAL。其中级别的对比是 TRACE < DEBUG < INFO <WARN < ERROR < FATAL。同时系统运行行,我们将设定 log level设置在某一个级别上,那么级别优先级高的 log 都能打印出来,低的都不能打印出。例如,如果设置优先级为WARN,那么FATAL、ERROR、WARN 级别的log能正常输出,而INFO、DEBUG、TRACE 级别的log则会被忽略。
我们编程时 DEBUG 或者 TRACE 级别打出细粒度的信息,比如每条数据的样子。当我们调试时或者线上有问题时,我们将程序的当前日志级别设置成 TRACE 或者 DEBUG,从而将细粒度的信息打出来。而正常运行时,我们将当前日志级别设置成 INFO 或者 WARN 级别,从而忽略细粒度的信息,降低 IO 操作和提升系统性能。
打印日志到哪里是还是一个问题 —— Appender
有了 Level,我们可以随心意写点 log 了,只要控制好日志级别就行。默认情况下,我们的日志是打印到 Console 里,我们直接人眼看。随着时间的推移,情况变得复杂起来。比如我们需要将日志打入文件里,方便以后查看。即使日志打到文件,我们也需要登录到机器才能查看,我们需要在发生错误时收到邮件或者短信。为了满足这些需求,我们在日志系统中加入 Appender 部件。Appender 部件负责将日志写的不同的目的。

比如下图就是 Log4j 的日志配置示例。这个示例会打印出所有的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档。

日志系统可以自定多种 Appender,人们基于这套逻辑发明了一套日志收集和实时检索的系统,也称之为日志系统。在这里为了区别,我们将日志收集和检索系统称之为日志收集检索系统。日志收集检索系统一般有 Kafka 流、实时处理组件 Spark Streaming 或者 Storm、实时检索系统 ElasticSearch 组成。后台系统通过日志系统的 Appender 组件将日志打到 Kafka 流,然后 Spark Streaming 或者 Storm 处理流数据并将之写入 ElasticSearch 检索系统。这样开发和运维就可以在 ElasticSearch 提供的 Web 查看可视化的日志了。日志收集检索系统的主要好处是,1) 日志集中管理,不需要登录到不同机器;2) 提供可视化的日志查看;3) 提供基于日志的监控、监测服务等。
目前最有名的日志收集检索系统应该是上图的 Splunk 了。
日志什么样也是个问题 —— Formatter
有了日志的 Level 和 Appender,我们还需要解决日志样式的问题。一般情况,我们希望的日志格式包括:Level,函数名,文件名和打日志的代码行数。这可以通过日志系统的 Formatter 组件来实现的。下图是一个 Python 自定义的Formatter。
import logging def AltCustomFormatter(logging.Formatter): def __init__(self, fmt=None, datefmt=None): super(AltCustomFormatter, self).__init__(fmt, datefmt) def format(self, record): # 如果你添加了多个handler,你会发现我们的定制消息被重复了多次, # 我们在record里设置一个marker来避免 if record.levelno > logging.INFO and not hasattr(record, 'is_custom'): record.msg = "[%s, %s, %s] %s" % (record.filename, record.lineno, record.funcName, record.msg) record.is_custom = True return super(AltCustomFormatter, self).format(record)
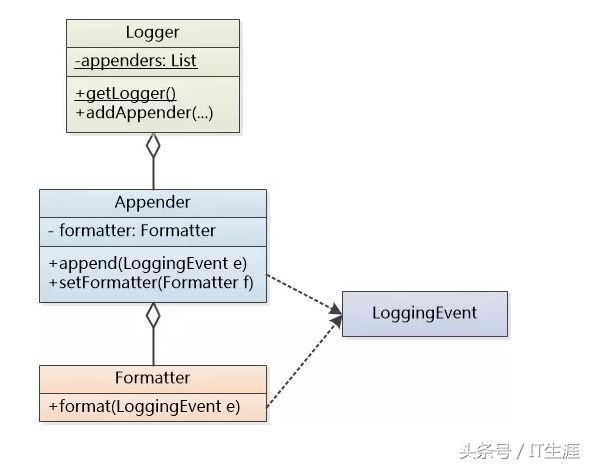
在引入 Level、Formater 和 Appender 概念之后,整个日志系统的架子算是搭起来了,如下图所示。作为一个普通程序员,可以安心使用这个日志系统了。
高效地打印日志是另外一个问题 —— Efficient
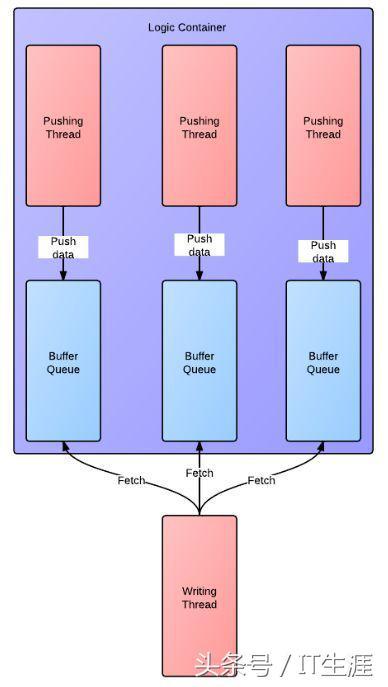
但是作为一个有追求的普通程序,我们想知道大规模系统的极限环境中,日志系统能不能撑得住。答案嘛,是按照上面设计的日志系统是撑不住的。因为大规模系统的极限环境,实时要求高,不能忍受写文件或者写网络的延迟。怎么办呢?有请对付 IO 延迟利器 —— Buffer。基于 Buffer,并考虑到 Buffer 所带来的线程同步的问题, 人们设计了下面的方案。在这个方案中,每个线程生成一个 Buffer,然后写线程轮询从 Buffer 读入信息,并写目的地。在这套方案中,写日志并不会导致服务延迟。
除了架构上的设计,还有一些小 trick 提高性能。比如我们在 log4j 官方 API 查到丑陋的 INFO 函数们。Java 语言不支持不定长参数的情况下,log4j 强行搞一个支持不定长的 INFO 函数,就只能靠着写不同的函数重载,最终也只支持 9 个参数。
但这些丑陋的 INFO 是有意义的。这些丑陋的 INFO 是为了能够实现下表中不定长参数的方式。这种不定长参数方式相比字符串拼接方式的区别在哪里呢? 当前级别是 ERROR 时,INFO 级别的信息是不用输出的,字符串拼接方式还是要拼字符串,而不定长参数方式就可以不用拼接字符串了。

感谢各位的阅读!关于“python中普通程序员如何了解日志系统”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





