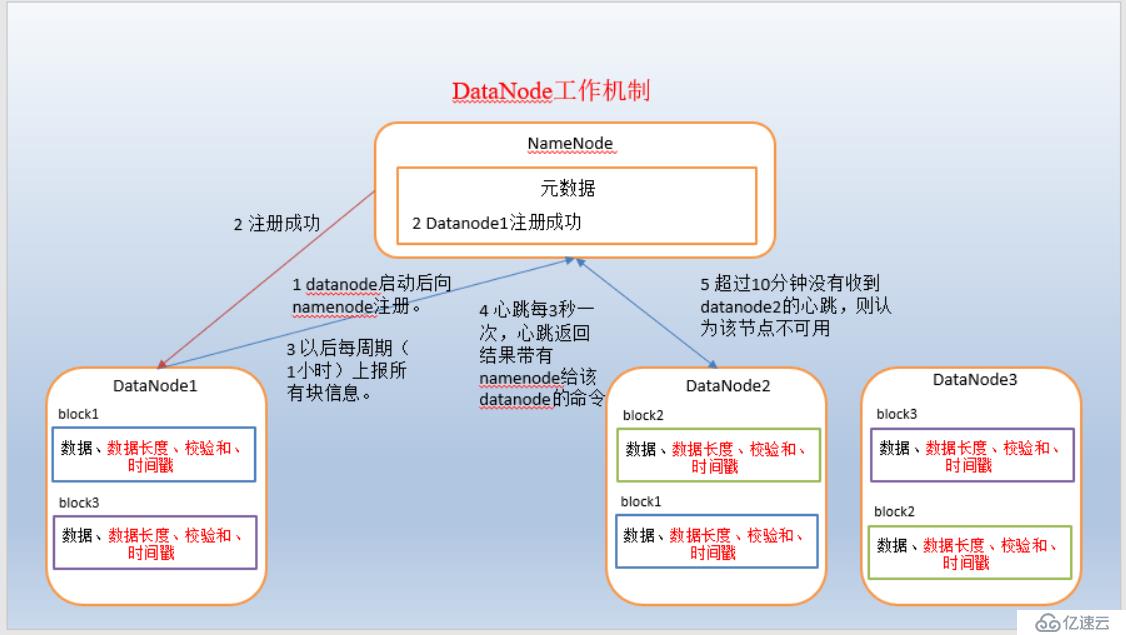
1)datanode启动后会根据配置文件中指定的namenode地址,向namenode进行注册。 2)namenode返回注册成功 3)此后,datanode会周期性向namenode上报所有块信息,默认是1小时 4)同时,datanode会每3秒给namenode发送心跳信息,namenode返回的心跳结果带有namenode给该datanode的命令,如复制块数据到另外一台机器,或者删除某个数据块。如果超过超过10分钟(默认)没有收到某个datanode的心跳信息,则认为该节点不可用。 5)集群运行过程中可以安全的加入和退出一些datanode机器
namenode 的目录结构是通过手动初始化hdfs namenode -format时创建的,而datanode的则是在启动时自动创建的,无需手动格式化。而且就算在datanode上格式化了namenode的目录结构,只要不在datanode在启动namenode,那么这些格式化的目录也是没有任何用处的。 一般datanode 的目录在 ${hadoop.tmp.dir}/dfs/data 下,看看目录结构
data
├── current
│ ├── BP-473222668-192.168.50.121-1558262787574 以poolID作为目录命名
│ │ ├── current
│ │ │ ├── dfsUsed
│ │ │ ├── finalized
│ │ │ │ └── subdir0
│ │ │ │ └── subdir0
│ │ │ │ ├── blk_1073741825
│ │ │ │ ├── blk_1073741825_1001.meta
│ │ │ │ ├── blk_1073741826
│ │ │ │ ├── blk_1073741826_1002.meta
│ │ │ │ ├── blk_1073741827
│ │ │ │ ├── blk_1073741827_1003.meta
│ │ │ ├── rbw
│ │ │ └── VERSION
│ │ ├── scanner.cursor
│ │ └── tmp
│ └── VERSION
└── in_use.lock
(1)/data/current/VERSION 文件内容如下:
# datanode的id,非全局唯一,没什么用
storageID=DS-0cb8a268-16c9-452b-b1d1-3323a4b0df60
# 集群ID,全局唯一
clusterID=CID-c12b7022-0c51-49c5-942f-edc889d37fee
# 创建时间,没什么用
cTime=0
# datanode 的唯一标识码,全局唯一
datanodeUuid=085a9428-9732-4486-a0ba-d75e6ff28400
# 存储类型为datanode
storageType=DATA_NODE
layoutVersion=-57
(2)/data/current/POOL_ID/current/VERSION
# 对接的namenode 的ID
namespaceID=983105879
# 创建时间戳
cTime=1558262787574
# 使用的pool id
blockpoolID=BP-473222668-192.168.50.121-1558262787574
layoutVersion=-57
(3)/data/current/POOL_ID/current/finalized/subdir0/subdir0 这个目录下是真正存储数据块。一个block主要分为两个文件存储:
blk_${BLOCK-ID}
blk_${BLOCK-ID}_xxx.meta
对于目录来说:
blk_${BLOCK-ID} :
是一个xml格式的文件,上面记录了了类似edits文件的操作日志,如:
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>22</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
<DATA>
<TXID>23</TXID>
<LENGTH>0</LENGTH>
<INODEID>16386</INODEID>
<PATH>/input</PATH>
<TIMESTAMP>1558105166840</TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>root</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
</EDITS>
blk_${BLOCK-ID}_xxx.meta:
是一个raw G3 data, byte-padded格式的文件,主要存储目录下的inode记录
对于文件来说:
blk_${BLOCK-ID} :
记录的是block中的实际数据
blk_${BLOCK-ID}_xxx.meta:
CRC32校验文件,保存数据块的校验信息
1)datanode读取block时,会计算其对于的checksum,如果和创建block时的checksum不同,那么证明该当前datanode上的该block已经损坏。此时client就会想存储该block 的其他datanode节点请求读取该block。 2)datanode在创建了block之后,会周期性检查block是否损坏,也是通过检查checksum的方式实现的。
datanode进程死亡,或者因为网络故障导致datanode无法与namenode通信,namenode不会立刻把该datanode判定为死亡,而是经过一段时间内,该datanode都没有心跳信息的话,就判定为死亡。而超时时间的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
dfs.namenode.heartbeat.recheck-interval:是namenode检查datanode是否存活的时间间隔,默认是为 5分钟,单位是毫秒
dfs.heartbeat.interval:datanode上传心跳信息的时间间隔,默认是3秒,单位是秒
两者都在 hdfs-site.xml中进行设置
datanode的多目录配置和namenode不同,多目录之间的数据是不相同的,而是将block数据分成两部分,分别放到两个目录下而已。配置如下:
//hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
虽然说每个block的大小都是128M(hadoop2.x),即使存储的数据实际大小并没有128M,也仍旧占据128M。但是实际存储到磁盘上时占据的是数据实际大小,而不是128M。因为物理磁盘的block默认是4KB,所以不可能是会白占128M。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





